Odds/Odds Ratio
Odds:几率/优势,事件发生与不发生的概率比值
- $p$:事件发生概率
Odds Ratio:优势比,两组事件 odds 的比值
WOE 值
WOE 值:将预测变量(二分类场景中)集中度作为分类变量编码的数值
- $\%B_i, \%G_i$:分类变量取第 $i$ 值时,预测变量为 B 类、G 类占所有 B 类、G 类比例
- $#B_i, #B_T$:分类变量取第 $i$ 值时预测变量为 B 类数量,所有 B 类总数量
- $#G_i, #G_T$:分类变量取第 $i$ 值时预测变量为 G 类数量,所有 G 类样本总数量
- $odds_i$:分类变量取第 $i$ 值时,预测变量取 B 类优势
- $odds_T$:所有样本中,预测变量取 B 类优势
- 其中 $log$ 一般取自然对数
WOE 编码是有监督的编码方式,可以衡量分类变量各取值中
- B 类占所有 B 类样本比例、G 类占所有 G 类样本比例的差异
- B 类、G 类比例,与所有样本中 B 类、G 类比例的差异
WOE 编码值能体现分类变量取值的预测能力,变量各取值 WOE 值方差越大,变量预测能力越强
- WOE 越大,表明该取值对应的取 B 类可能性越大
- WOE 越小,表明该取值对应的取 G 类可能性越大
- WOE 接近 0,表明该取值预测能力弱,对应取 B 类、G 类可能性相近
OR与WOE线性性
即:预测变量对数优势值与 WOE 值呈线性函数关系
- 预测变量在取 $i,j$ 值情况下,预测变量优势之差为取 $i,j$ 值的 WOE 值之差
- WOE 值编码时,分类变量在不同取值间跳转时类似于线性回归中数值型变量
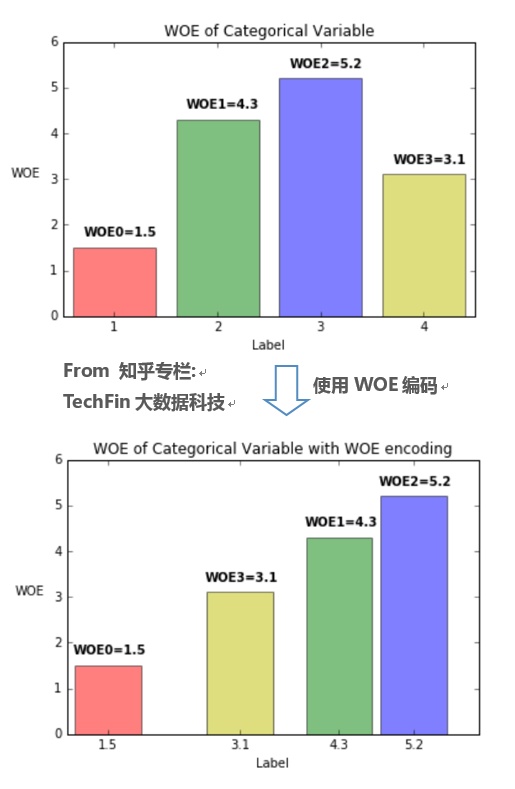
考虑到对数优势的数学形式,单变量 LR 模型中分类型变量 WOE 值可以类似数值型变量直接入模
- 当然,WOE 值编码在多元 LR 中无法保证单变量分类情况下的线性
- 或者说多变量 LR 中个变量系数值不一定为 1
- 在基于单变量预测能力优秀在多变量场合也优秀的假设下,WOE 值编码(IV 值)等单变量分析依然有价值
Bayes Factor、WOE 编码、多元 LR
- $\frac {P(x_i|Y=1)} {P(x_i|Y=0)}$:贝叶斯因子,常用于贝叶斯假设检验
Naive Bayes 中满足各特征 $X$ 关于 $Y$ 条件独立的强假设下,第二个等式成立
Semi-Naive Bayes 中放宽各特征关于 $Y$ 条件独立假设,使用权重体现变量相关性,此时则可以得到多元 LR 的预测变量取值对数 OR 形式
- 则多元 LR 场景中,WOE 值可以从非完全条件独立的贝叶斯因子角度理解
IV 值
- $IV_i$:特征 $i$ 取值 IV 值
- $IV$:特征总体 IV 值
- 特征总体的 IV 值实际上是其各个取值 IV 值的加权和
- 类似交叉熵为各取值概率的加权和