OptimalBST(P[1..n]) // 动态规划法构建最优二叉查找树 // 输入:P[1..n]n个键查找概率 // 输出:在最优BST中查找成功的平均比较次数,最优BST子树根表 for i = 1 to n do C[i, i-1] = 0 C[i, i] = P[i] R[i, i] = i C[n+1, n] = 0 // 初始化平均查找次数表、子树根表 for d = 1 to n-1do // d为二叉树节点数 for i = 1 to n-d do // n-d是为了控制j的取值 j = i + d minval = \infty for k = i to j do // 遍历设置二叉树根节点 if C[i, k-1] + C[k+1, j] < minval minval = C[i, k-1] + C[k+1, j] kmin = k R[i, j] = kmin sum = P[i] for s=i+1 to j do sum += P[s] C[i, j] = minval + sum return C[1, n], R
算法特点
算法效率
算法时间效率为立方级
算法空间效率为平方级
AVL Tree
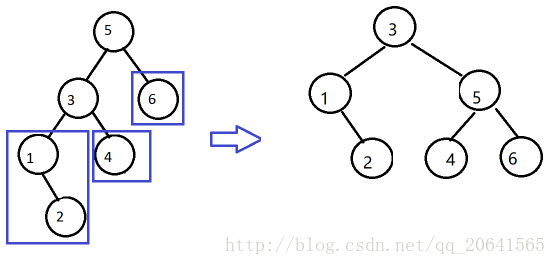
AVL树:要求其节点在左右子树高度差不能超过1的平衡二叉树
基本思想:总能通过一次简单的节点重排使树达到平衡
如果树插入操作使得一棵AVL树失去平衡,利用旋转对树作
变换
若有多个这样的节点,找出最靠近新插入的叶子节点不平衡
结点,然后旋转以该节点为根的子树
AVL树高度h即为其查找、插入效率
包含n个节点AVL树高度h满足
$\lfloor log_2 n \rfloor \leq h < 1.4405log_2(n+2) - 1.3277$
最差情况下,操作效率$\in \Theta(logn)$
平均而言,在n不是太小时,高度h平均为
$1.01log_2 n + 0.1$(几乎同折半查找有序数组)
AVL树缺点(平衡代价),阻碍AVL树成为实现字典的标准结构
需要频繁旋转
维护树的节点平衡
总体比较复杂
旋转
按照节点平衡符号进行旋转:+左旋、-右旋
单旋:不平衡节点、不平衡子节点不平衡因子符号相同
全为+:不平衡节点左旋
全为-:不平衡节点右旋
双旋:不平衡节点、不平衡子节点不平衡因子符号不同
先旋转不平衡子节点
再旋转不平衡节点
优先考虑最底层、不平衡节点
插入节点
AVL树插入关键:查找不平衡节点
节点中应有存储其平衡因子的实例变量
插入过程中经过每个节点返回当前节点子树深度是否变化
比较节点平衡因子、子节点深度变化返回值判断是否平衡
插入过程中查询的每个节点都有可能不平衡
自下而上返回深度变化情况,优先旋转最底层不平衡节点
4种插入情况
根据插入情况的不同,对最靠近新插入叶子节点的不平衡点T
LL
插入T左儿子L的左子树LL:平衡因子全-
即T到最底层叶节点(只可能有一个)的路径为LL(中间省略)
R-rotation:右单转,对T做一次右旋即可平衡
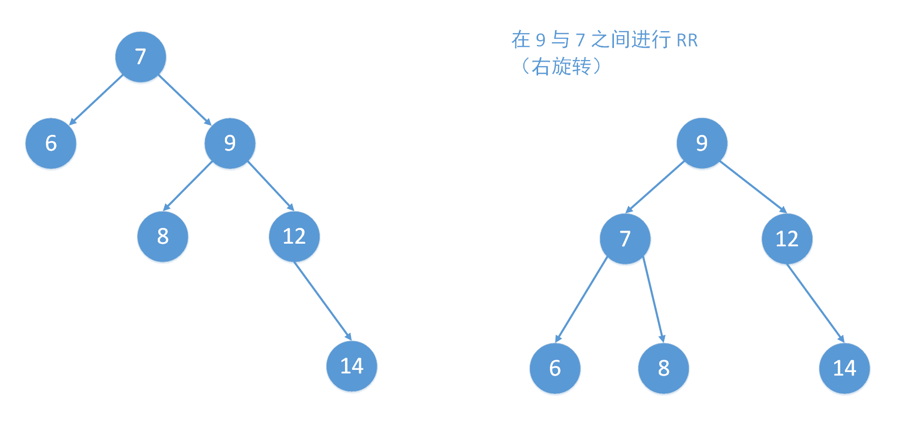
RR
插入T右儿子R的右子树R:平衡因子全+
即T到最底层叶节点(只可能有一个)的路径为RR(中间省略)
L-rotation:左单转,对T做一次左旋即可平衡
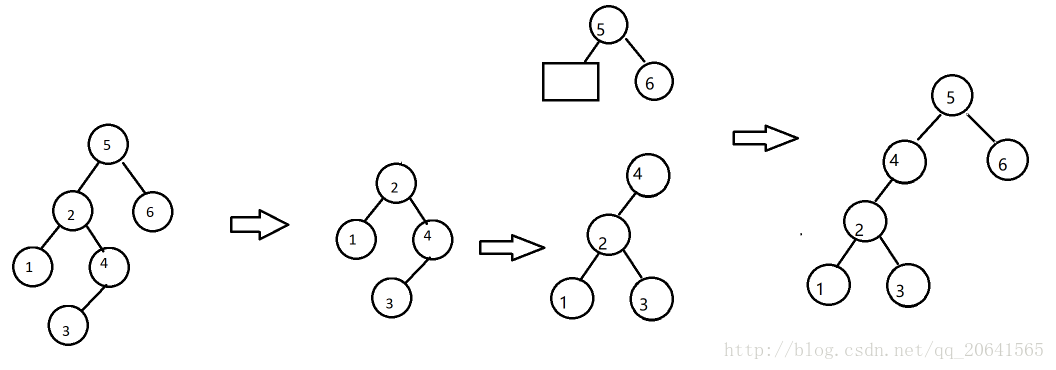
LR
插入T左儿子L的右子树R:平衡因子-+
即T到最底层叶节点(只可能有一个)的路径为LR(中间省略)
LR-rotation:左右双转
先对左儿子L做一次左旋,变成LL模式
在LL模式下,再对T做一次右旋
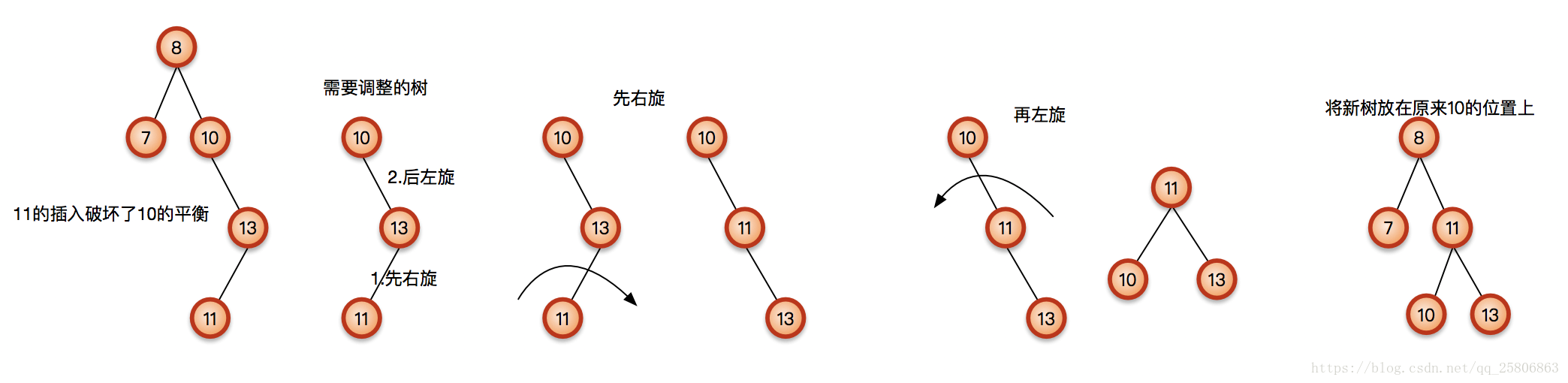
RL
插入T右儿子R的左子树L:平衡因子+-
即T到最底层叶节点(只可能有一个)的路径为RL(中间省略)
RL-rotation:右左双转
先对右儿子R做一次右旋,变成RR模式
在RR模式下,再对T做一次左旋
实现
删除节点
在AVL树中删除键相对而言比较困难,但也是对数级的
实现
Red-Black Tree
红黑树:能够容忍同一节点的一棵子树高度是另一棵的2倍
Splay Tree
分裂树:
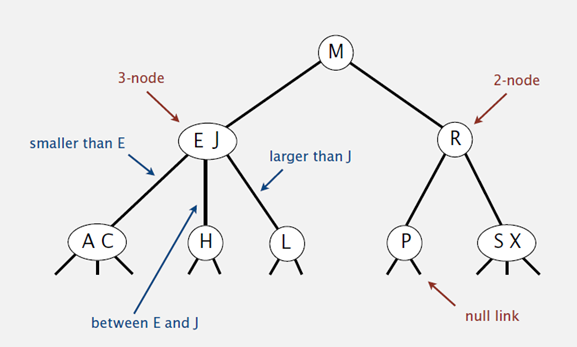
2-3树
2-3树:可以包含两种类型的节点2节点、3节点,树的所有叶子节点
必须位于同一层
2-3树的高度即决定其查找、插入、删除效率
节点数为n的2-3数高度h满足
$log_3(n+1)-1 \leq h \leq log_2(n+1) - 1$
classReader: asyncdefreadline(self): pass def__aiter__(self): return self asyncdef__anext__(self): val = await self.readline() if val == "b": raise StopAsyncIteration return val
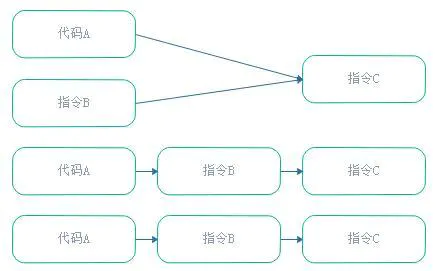
A computer program or routine is described as reentrant
if it can be safely executed concorrently; that is, the
routine can be re-entered while it is already running
for each row R1 in the outer table: for each row R2 in the inner table: if R1 join with R2: return (R1, R2)
外部循环逐行消耗外部输入表,当其数据量很大时可以并行扫描
内表
内表被外表驱动:内部循环为每个外部行执行,在内表中搜索
匹配行
基于块嵌套循环联接算法
每次IO申请以“块”为单位尽量读入多个页面
改进获取元组的方式
1 2 3 4 5 6 7 8 9 10
for each chunk c1 of t1 if c1 not in memory: read chunk c1 to memory for each row r1 in chunk c1: for each chunk c2 of t2: if c2 not in memory: read chunk c2 into memory for each row r2 in c2: if r1 join with r2: return(R1, R2)
内存循环最后一个块使用后作为下次循环循环使用的第一个块
可以节省一次IO
索引嵌套循环联接算法
索引嵌套循环连结:在内表中搜索时使用索引,可以加快联接
速度
临时索引嵌套循环连结:为查询临时生成索引作为查询计划的
一部分,查询完成后立刻将索引破坏
(Sort)Merge Join
排序归并联接算法
适合场景
联接字段已经排序,如B+树索引
inner、left outer、left semi、left anti semi、
right outer、right semi、right anti semi join、union