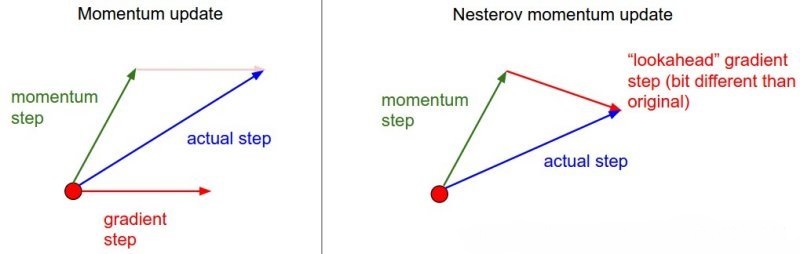
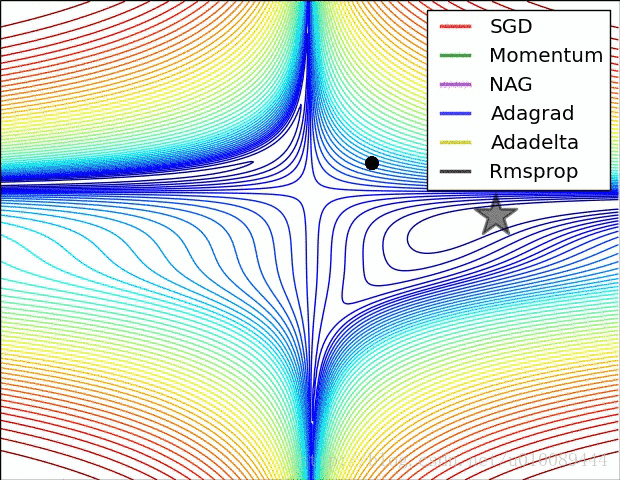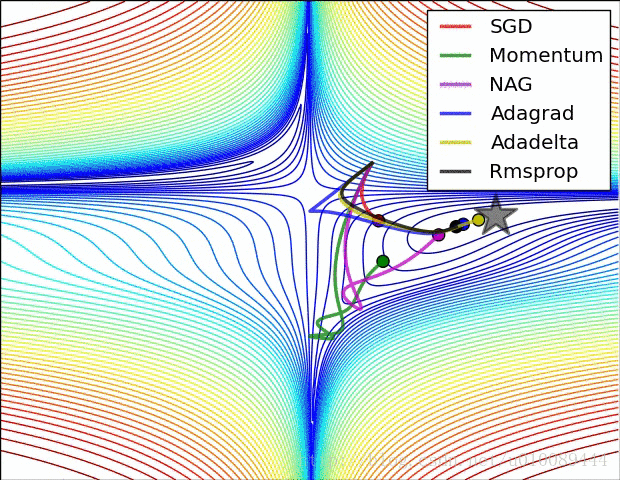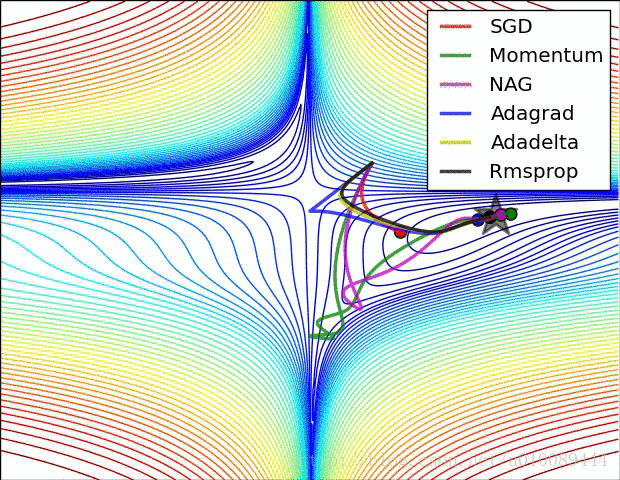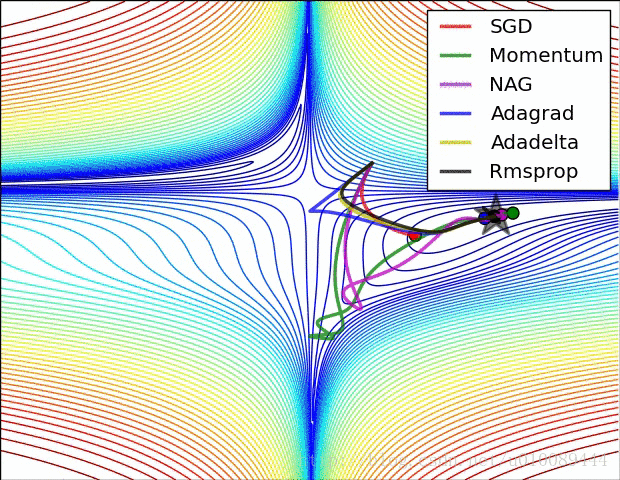
Kernel Function
Kernel Function
- 对输入空间 $X$ (欧式空间 $R^n$ 的子集或离散集合)、特征空间 $H$ ,若存在从映射 $$
\phi(x): X \rightarrow H$$ 则称 $K(x,z)$ 为核函数、 $\phi(x)$ 为映射函数,其中 $\phi(x) \phi(z)$ 表示内积K(x,z) = \phi(x) \phi(z)
- 特征空间 $H$ 一般为无穷维
- 特征空间必须为希尔伯特空间(内积完备空间)
映射函数 $\phi$
映射函数 $\phi$:输入空间 $R^n$ 到特征空间的映射 $H$ 的映射
对于给定的核 $K(x,z)$ ,映射函数取法不唯一,映射目标的特征空间可以不同,同一特征空间也可以取不同映射,如:
对核函数 $K(x, y) = (x y)^2$ ,输入空间为 $R^2$ ,有
若特征空间为$R^3$,取映射
或取映射
若特征空间为$R^4$,取映射
核函数 $K(x,z)$
Kernel Trick 核技巧:利用核函数简化映射函数 $\phi(x)$ 映射、内积的计算技巧
- 避免实际计算映射函数
- 避免高维向量空间向量的存储
核函数即在核技巧中应用的函数
- 实务中往往寻找到的合适的核函数即可,不关心对应的映射函数
- 单个核函数可以对应多个映射、特征空间
核技巧常被用于分类器中
- 根据 Cover’s 定理,核技巧可用于非线性分类问题,如在 SVM 中常用
- 核函数的作用范围:梯度变化较大的区域
- 梯度变化小的区域,核函数值变化不大,所以没有区分能力
- Cover’s 定理可以简单表述为:非线性分类问题映射到高维空间后更有可能线性可分
正定核函数
- 设 $X \subset R^n$,$K(x,z)$ 是定义在 $X X$的对称函数,若 $\forall x_i \in \mathcal{X}, i=1,2,…,m$,$K(x,z)$ 对应的 Gram* 矩阵 $$
$$ 是半正定矩阵,则称 $K(x,z)$ 为正定核G = [K(x_i, x_j)]_{m*m}
- 可用于指导构造核函数
- 检验具体函数是否为正定核函数不容易
- 正定核具有优秀性质
- SVM 中正定核能保证优化问题为凸二次规划,即二次规划中矩阵 $G$ 为正定矩阵
欧式空间核函数
Linear Kernel
线性核:最简单的核函数
- 特点
- 适用线性核的核算法通常同普通算法结果相同
- KPCA 使用线性核等同于普通 PCA
- 适用线性核的核算法通常同普通算法结果相同
Polynomial Kernel
多项式核:non-stational kernel
Gaussian Kernel
高斯核:radial basis kernel,经典的稳健径向基核
- $\sigma$:带通,取值关于核函数效果,影响高斯分布形状
- 高估:分布过于集中,靠近边缘非常平缓,表现类似像线性一样,非线性能力失效
- 低估:分布过于平缓,失去正则化能力,决策边界对噪声高度敏感
特点
- 对数据中噪声有较好的抗干扰能力
对应映射:省略分母
即高斯核能够把数据映射至无穷维
应用场合
SVM:高斯radial basis function分类器
Exponential Kernel
指数核:高斯核变种,仅去掉范数的平方,也是径向基核
- 降低了对参数的依赖性
- 适用范围相对狭窄
Laplacian Kernel
拉普拉斯核:完全等同于的指数核,只是对参数$\sigma$改变敏感 性稍低,也是径向基核
ANOVA Kernel
方差核:径向基核
- 在多维回归问题中效果很好
Hyperbolic Tangent/Sigmoid/Multilayer Perceptron Kernel
Sigmoid核:来自神经网络领域,被用作人工神经元的激活函数
条件正定,但是实际应用中效果不错
参数
- $\alpha$:通常设置为$1/N$,N是数据维度
- 使用Sigmoid核的SVM等同于两层感知机神经网络
Ration Quadratic Kernel
二次有理核:替代高斯核,计算耗时较小
Multiquadric Kernel
多元二次核:适用范围同二次有理核,是非正定核
Inverse Multiquadric Kernel
逆多元二次核:和高斯核一样,产生满秩核矩阵,产生无穷维的 特征空间
Circular Kernel
环形核:从统计角度考虑的核,各向同性稳定核,在$R^2$上正定
Spherical Kernel
类似环形核,在$R^3$上正定
Wave Kernel
波动核
- 适用于语音处理场景
Triangular/Power Kernel
三角核/幂核:量纲不变核,条件正定
Log Kernel
对数核:在图像分隔上经常被使用,条件正定
Spline Kernel
样条核:以分段三次多项式形式给出
B-Spline Kernel
B-样条核:径向基核,通过递归形式给出
- $x_{+}^d$:截断幂函数
Bessel Kernel
Bessel核:在theory of function spaces of fractional smoothness 中非常有名
- $J$:第一类Bessel函数
Cauchy Kernel
柯西核:源自柯西分布,是长尾核,定义域广泛,可以用于原始维度 很高的数据
Chi-Square Kernel
卡方核:源自卡方分布
Histogram Intersection/Min Kernel
直方图交叉核:在图像分类中经常用到,适用于图像的直方图特征
Generalized Histogram Intersection
广义直方图交叉核:直方图交叉核的扩展,可以应用于更多领域
Bayesian Kernel
贝叶斯核:取决于建模的问题
Wavelet Kernel
波核:源自波理论
参数
- $c$:波的膨胀速率
- $a$:波的转化速率
- $h$:母波函数,可能的一个函数为
转化不变版本如下
离散数据核函数
String Kernel
字符串核函数:定义在字符串集合(离散数据集合)上的核函数
$[\phin(s)]_n = \sum{i:s(i)=u} \lambda^{l(i)}$:长度 大于等于n的字符串集合$S$到特征空间 $\mathcal{H} = R^{\sum^n}$的映射,目标特征空间每维对应 一个字符串$u \in \sum^n$
$\sum$:有限字符表
$\sum^n$:$\sum$中元素构成,长度为n的字符串集合
$u = s(i) = s(i1)s(i_2)\cdots s(i{|u|})$:字符串s的 子串u(其自身也可以用此方式表示)
$i =(i1, i_2, \cdots, i{|u|}), 1 \leq i1 < i_2 < … < i{|u|} \leq |s|$:序列指标
$l(i) = i_{|u|} - i_1 + 1 \geq |u|$:字符串长度,仅在 序列指标$i$连续时取等号($j$同)
$0 < \lambda \leq 1$:衰减参数
两个字符串s、t上的字符串核函数,是基于映射$\phi_n$的 特征空间中的内积
- 给出了字符串中长度为n的所有子串组成的特征向量的余弦 相似度
- 直观上,两字符串相同子串越多,其越相似,核函数值越大
- 核函数值可由动态规划快速计算(只需要计算两字符串公共 子序列即可)
应用场合
- 文本分类
- 信息检索
- 信物信息学