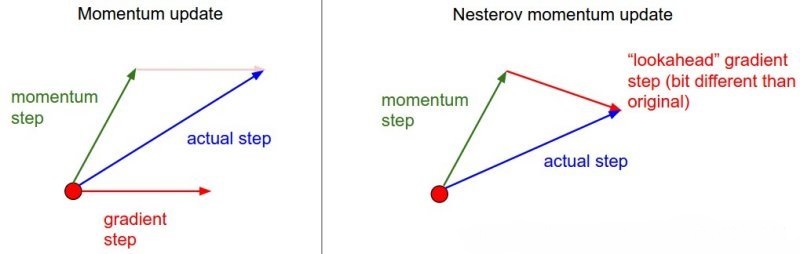
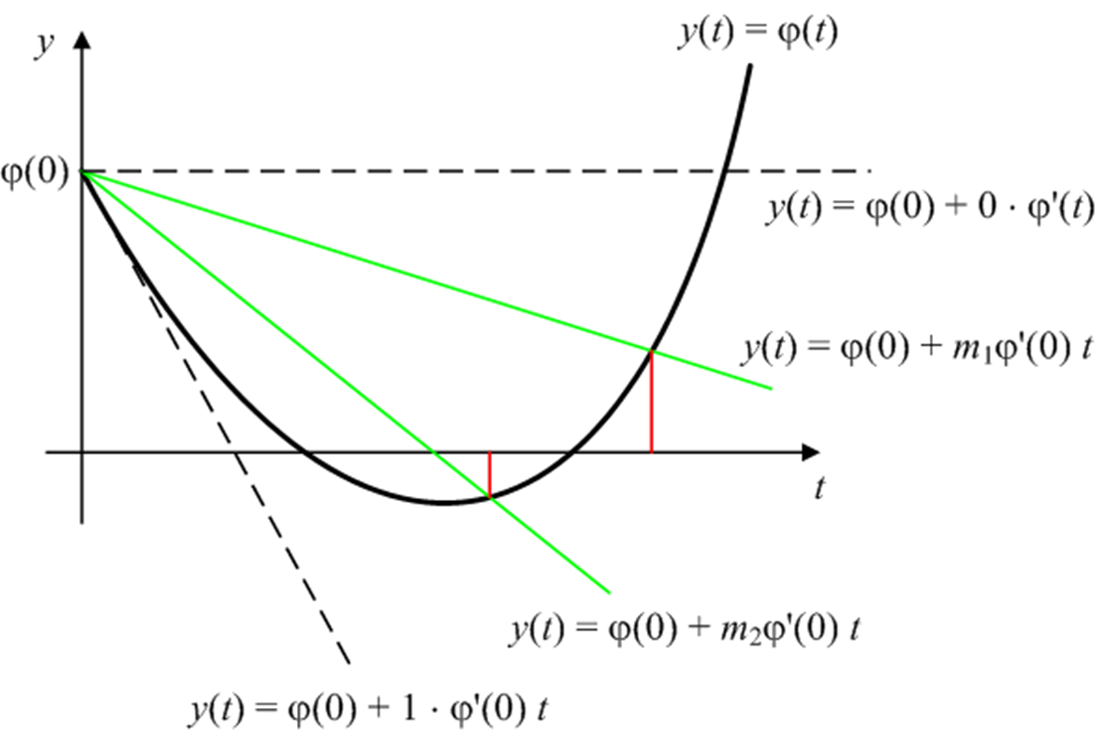
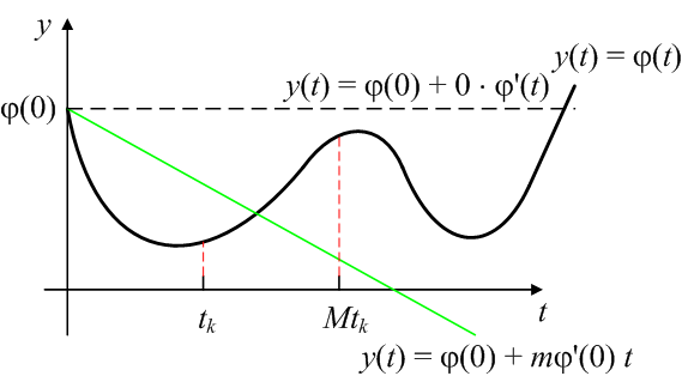
次梯度
次梯度
次梯度:实变量凸函数 $f$ 在点 $x_0$ 的次梯度 $c$ 满足
可证明凸函数 $f$ 在 $x_0$ 处所有次梯度的集合 $\partial f(x)$ 是非空凸紧集
$\partial f(x) = [a, b]$,其中$a, b$为单侧极限
- 凸函数均指下凸函数,梯度不减
次梯度性质
运算性质
数乘性质
加法性质
仿射性质:$f$为凸函数
最优化性质
凸函数 $f$ 在点 $x_0$ 可导,当且仅当次梯度仅包含一个点,即该点导数
点 $x_0$ 是凸函数 $f$ 最小值,当且仅当次微分中包含 0 (此性质为“可导函数极小点导数为 0 ”推广)
负次梯度方向不一定是下降方向
次梯度求解
- 逐点(分段)极值的函数求次梯度
- 求出该点相应极值函数
- 求出对应梯度即为次梯度
Pointwise Maximum
逐点最大函数:目标函数为
- $I(x)$:保存 $x$ 处取值最大的函数下标
弱结果:$I(x)$ 中随机抽取,以 $f_i(x)$ 在该处梯度作为次梯度
强结果
- 先求支撑平面,再求所有支撑平面的凸包
- 可导情况实际上是不可导的特殊情况
分段函数
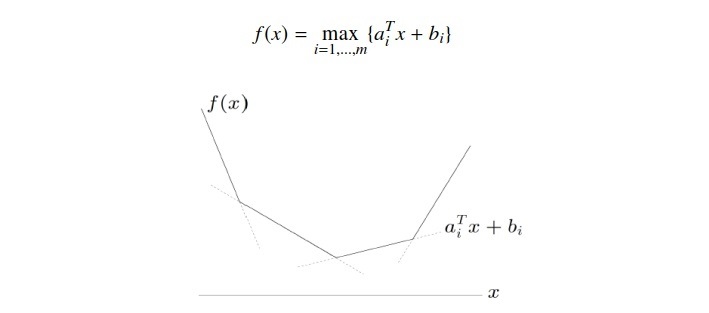
折点处
非折点处
$L_1$范数

PointWise Supremum
逐点上确界:目标函数为
弱结果:可行梯度为
强结果
最大特征值
- $A_n$:对称矩阵
对确定 $\hat {x}$,$A(x)$ 最大特征值 $\lambda_{max}$、对应特征向量 $y$,则该点此梯度为
Pointwise Inferior
逐点下确界:目标函数为
- $h$:凸函数
弱结果:给定$x = \hat x$,可行次梯度为
复合函数
- $h$:凸、不降函数
- $f_i$:凸函数
弱结果:给定$x = \hat x$,可行次梯度为
- $z \in \partial h(f_1(\hat x), \cdots, f_k(\hat x))$
- $g_i \in \partial f_i(\hat x)$
证明
次梯度法
- $g^{(k)}$:函数$f$在$x^{(k)}$处次梯度
求解凸函数最优化的问题的一种迭代方法
相较于较内点法、牛顿法慢
- 应用范围更广泛:能够用于不可微目标函数,目标函数可微时,无约束问题次梯度与梯度下降法有同样搜索方向
- 空间复杂度更小
- 可以和分解技术结合,得到简单分配算法
- 通常不会产生稀疏解
步长选择
- 次梯度法选取步长方法很多,以下为保证收敛步长规则
- 恒定步长:$\alpha_k = \alpha$
- 恒定间隔:$\alpha_k = \gamma / |g^{(k)}|_2$
- 步长平方可加、步长不可加:$\sum{k=1}^{\infty} \alpha_k^2 < \infty, \sum{k=1}^{\infty} \alpha_k = \infty$
- 步长不可加、但递减:$lim_{k \rightarrow \infty} \alpha_k = 0$
- 间隔不可加、但递减:$lim_{k \rightarrow \gamma_k} \gamma_k = 0$