NDArray标量
NDArray标量类型
numpy中定义了24种新python类型(NDArray标量类型)
- 类型描述符主要基于CPython中C语言可用的类型
标量具有和
ndarray相同的属性和方法- 数组标量不可变,故属性不可设置
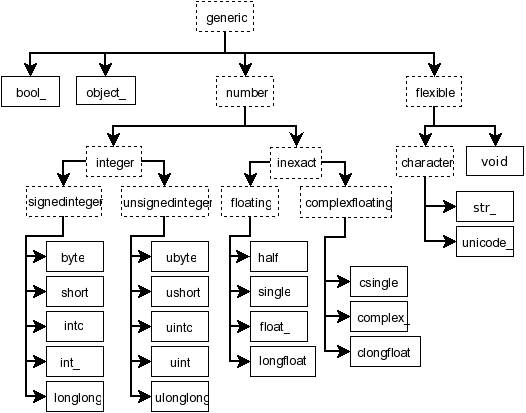
内置标量类型
| Routine | Desc |
|---|---|
iinfo(int_type) |
整数类型的取值范围等信息 |
finfo(float_type) |
浮点类型的取值范围等信息 |
Python关联
| NumPy类型 | Python类型 | 64位NumPy定长类型 | Desc |
|---|---|---|---|
int_ |
继承自int(Python2) |
int64 |
|
float_ |
继承自float |
float64 |
|
complex_ |
继承自complex |
complex128 |
|
bytes_ |
继承自bytes |
S#"/"a#" |
Python字节串 |
unicode_ |
继承自str |
"U#" |
Python字符串 |
void |
"V#" |
Python缓冲类型 | |
object_ |
继承自object(Python3) |
"O" |
Python对象引用 |
np.bool_类似Python中bool类型,但不继承它- Python中
bool类型不允许被继承 np.bool_大小和bool类型大小不同
- Python中
np.int_不继承自int,因为后者宽度不再固定- NumPy中数组没有真正
np.int类型,因为宽度不再固定, 各产品
- NumPy中数组没有真正
bytes_、unicode_、void是可灵活配置宽度的类型- 在指定长度后不能更改,赋长于指定长度的值会被截断
unicode_:强调内容为字符串bytes_:强调内容为字节串void:类型强调内容为二进制内容,但不是字节串
object_存储的是python对象的引用而不对象本身- 其中引用不必是相同的python类型
- 兜底类型
- Python基本类型等在NumPy命名空间下都有同名别名,如:
np.unicode == np.str == str- NumPy数组中数据类型无法被真正设置为
int类型,为保证数组 中元素宽度一致性,必然无法被设置为非定长类型
C类型关联
- NumPy支持的原始类型和C中原始类型紧密相关
| NumPy类型 | C类型 | 64位定长别名 | Desc | 单字符代码 | 定长字符串代码 |
|---|---|---|---|---|---|
bool_ |
bool |
bool8 |
存储为字节的bool值 | "?" |
无 |
byte |
signed char |
int8 |
"b" |
"i1" |
|
short |
short |
int16 |
"h" |
"i2" |
|
intc |
int |
int32 |
"i" |
"i4" |
|
int_ |
long |
int64 |
"l" |
"i8" |
|
longlong |
long long |
无 | "q" |
无 | |
ubyte |
unsigned char |
uint8 |
"B" |
"u1" |
|
ushort |
unsigned short |
uint16 |
"H" |
"u2" |
|
uintc |
unsigned int |
uint32 |
"I" |
"u4" |
|
uint |
usigned long |
uint64 |
"L" |
"u8" |
|
ulonglong |
unsigned long long |
无 | "Q" |
无 | |
half |
无 | float16 |
半精度浮点:1+5+10 | "e" |
"f2" |
single |
float |
float32 |
单精度浮点,通常为:1+8+23 | "f4" |
|
double |
double |
float64 |
双精度浮点,通常为:1+11+52 | "d" |
"f8" |
longdouble/longfloat |
long double |
float128 |
平台定义的扩展精度浮点 | "g" |
"f16" |
csingle |
float complex |
complex64 |
两个单精度浮点 | "F" |
"c8" |
cdouble/cfloat |
double complex |
complex128 |
两个双精度浮点 | "D" |
"c16" |
clongdouble/clongfloat |
long duoble complex |
complex256 |
两个扩展精度浮点 | "G" |
"c32" |
float complex、double complex类型定义在complex.h中- C中的定长类型别名定义在
stdint.h中
其他类型
| Python类型 | Desc | 单字符代码 | 定长字符串代码 |
|---|---|---|---|
timedelta64 |
时间增量 | "m" |
"m8" |
datetime64 |
日期时间 | "M" |
"M8" |
属性、索引、方法
数组标量属性基本同
ndarray数组标量类似0维数组一样支持索引
X[()]返回副本X[...]返回0维数组X[<field-name>]返回对应字段的数组标量
数组标量与
ndarray有完全相同的方法- 默认行为是在内部将标量转换维等效0维数组,并调用相应 数组方法
定义数组标量类型
- 从内置类型组合结构化类型
- 子类化
ndarray- 部分内部行为会由数组类型替代
- 完全自定义数据类型,在numpy中注册
- 只能使用numpy C-API在C中定义
数据类型相关函数
数据类型信息
| Function | Desc |
|---|---|
finfo(dtype) |
机器对浮点类型限制 |
iinfo(type) |
机器对整型限制 |
MachAr([float_conv,int_conv]) |
诊断机器参数 |
typename(char) |
对给定数据类型字符代码的说明 |
数据类型测试
| Function | Desc |
|---|---|
can_cast(from_,to[,casting]) |
是否可以类型转换 |
issctype(rep) |
rep(不能为可转换字符串)是否表示标量数据类型 |
issubdtype(arg1,arg2) |
arg1在数据类型层次中较低(即dtype的issubclass) |
issubsctype(arg1,arg2) |
同issubdtype,但支持包含dtype属性对象作为参数 |
issubclass_(arg1,arg2) |
同内置issubclass,但参数非类时仅返回False,而不是raise TypeError |
np.int64、np.int32在层次体系中不同、且层级一致,所以 会出现issubdtype(np.int64, int) -> True,其他情况为False通过
np.can_cast函数确定safely类型转换1
2
3
4
5
6
7
8
9
10
11def print_casting(ntypes):
print("X")
for char in ntypes:
print(char, end=" ")
print("")
for row in ntypes:
print(row, end=" ")
for col in ntypes:
print(int(np.can_cast(row, col)), end=" ")
print("")
print_casting(np.typecodes["All"])
数据类型确定
| Function | Params | ReturnType | ReturnDesc |
|---|---|---|---|
min_scalar_type(a) |
标量值 | dtype实例 | 满足要求最小类型 |
promote_types(type1,type2) |
dtype等 | dtype实例 | 可安全转换的最小类型 |
result_type(*array_and_dtypes) |
dtype等、标量值、数组 | dtype实例 | 应用promotion rules得到类型 |
find_common_type(array_types,scalar_types) |
dtype等列表 | dtype实例 | 综合考虑标量类型、数组类型 |
common_type(*arrays) |
数值型数组(有dtype属性) |
预定义类型 | 满足要求类型中、最高精度类型 |
maximum_sctype(t) |
dtype等、标量值、数组 | 预定义类型 | 满足要求类型中、最高精度类型 |
obj2sctype(rep[,default]) |
dtype等、标量值、数组 | 预定义类型 | 对象类型 |
sctype2char(sctype) |
dtype等、标量值、数组 | 类型字符代码 | 满足要求的最小类型 |
mintypecode(typechars[,typeset,default]) |
dtype等、标量值、数组 | 类型字符代码 | typeset中选择 |
- 除非标量和数组为不同体系内数据类型,否则标量不能up_cast 数组数据类型
- https://numpy.org/devdocs/reference/generated/numpy.issubdtype.html#numpy.issubdtype
- https://numpy.org/devdocs/reference/generated/numpy.issubsctype.html#numpy.issubsctype
- https://numpy.org/devdocs/reference/generated/numpy.find_common_type.html#numpy.find_common_type
- https://numpy.org/devdocs/reference/generated/numpy.result_type.html#numpy.result_type
- https://numpy.org/devdocs/reference/generated/numpy.common_type.html#numpy.common_type
数据类型类np.dtype
1 | class dtype(obj[,align,copy]) |
numpy.dtype类描述如何解释数组项对应内存块中字节- 数据大小
- 数据内存顺序:little-endian、big-endian
- 数据类型
- 结构化数据
- 各字段名称
- 各字段数据类型
- 字段占用的内存数据块
- 子数组
- 形状
- 数据类型
- 结构化数据
需
numpy.dtype实例作为参数的场合,大部分场景可用等价、 可转换为dtype实例的其他值代替- python、numpy中预定义的标量类型、泛型类型
- 创建
dtype实例类型的字符串、字典、列表 - 包含
dtype属性的类、实例
数据类型元素
类型类
NumPy内置类型
- 24中内置数组标量类型
泛型类型
|Generic类型|转换后类型| |——-|——-| |
number,inexact,floating|float_| |complexfloating|complex_| |integer,signedinteger|int_| |unsignedinteger|uint| |character|string| |generic,flexible|void|
python内置类型,等效于相应数组标量
- 转换规则同NumPy内置数组标量类型
None:缺省值,转换为float_|Python内置类型|转换后类型| |——-|——-| |
int|int_| |bool|bool_| |float|float_| |complex|complex_| |bytes|bytes_| |str|unicode_| |unicode|unicode_| |buffer|void| |Others|object_|
带有
.dtype属性的类型:直接访问、使用该属性- 该属性需返回可转换为
dtype对象的内容
- 该属性需返回可转换为
可转换类型的字符串
numpy.sctypeDict.keys()中字符串Array-protocal类型字符串,详细参见NumPy数组标量类型
- 首个字符指定数据类型
- 支持指定字节数的字符可在之后指定项目占用字节数
- 定长类型只能指定满足平台要求的字节数
- 非定长类型可以指定任意字节数
|代码|类型| |——-|——-| |
'?'|boolean| |'b'|(signed) byte,等价于'i1'| |'B'|unsigned byte,等价于'u1'| |'i'|(signed) integer| |'u'|unsigned integer| |'f'|floating-point| |'c'|complex-floating point| |'m'|timedelta| |'M'|datetime| |'O'|(Python) objects| |'S'/'a'|zero-terminated bytes (not recommended)| |'U'|Unicode string| |'V'|raw data (void)|
结构化数据类型
| Function | Desc |
|---|---|
format_parser(formats,names,titles[,aligned,byteorder]) |
创建数据类型 |
dtype(obj[,align,copy]) |
结构化数据类型
- 包含一个或多个数据类型字段,每个字段有可用于访问的 名称
- 父数据类型应有足够大小包含所有字段
- 父数据类型几乎总是基于
void类型
仅包含不具名、单个基本类型时,数组结构会穿透
- 字段不会被隐式分配名称
- 子数组shape会被添加至数组shape
参数格式
可转换数据类型的字符串指定类型、shape
- 依次包含四个部分
- 字段shape
- 字节序描述符:
<、>、| - 基本类型描述符
- 数据类型占用字节数
- 对非变长数据类型,需按特定类型设置
- 对变长数据类型,指字段包含的数量
- 逗号作为分隔符,分隔多个字段
- 各字段名称只能为默认字段名称
- 对变长类型,仅设置shape时,会将其视为bytes长度
1
dt = np.dtype("i4, (2,3)f8, f4")
- 依次包含四个部分
元组指定字段类型、shape
- 元组中各元素指定各字段名、数据类型、shape:
(<field_name>, <dtype>, <shape>)- 若名称为
''空字符串,则分配标准字段名称
- 若名称为
- 可在列表中多个元组指定多个字段
[(<field_name>, <dtype>, <shape>),...] - 数据类型
dtype可以嵌套其他数据类型- 可转换类型字符串
- 元组/列表
1
2
3dt = np.dtype(("U10", (2,2)))
dt = np.dtype(("i4, (2,3)f8, f4", (2,3))
dt = np.dtype([("big", ">i4"), ("little", "<i4")])- 元组中各元素指定各字段名、数据类型、shape:
字典元素为名称、类型、shape列表
- 类似
format_parser函数,字典各键值对分别指定名称 列表、类型列表等:{"names":...,"formats":...,"offsets":...,"titles":...,"itemsize":...}"name"、"formats"为必须"itemsize"指定总大小,必须足够大
- 分别指定各字段:
"field_1":..., "field_2":...- 不鼓励,容易与上一种方法冲突
1
2
3
4dt = np.dtype({
"names": ['r', 'g', 'b', 'a'],
"formats": ["u1", "u1", "u1", "u1"]
})- 类似
解释基数据类型为结构化数据类型:
(<base_dtype>, <new_dtype>)- 此方式使得
union成为可能
1
dt = np.dtype(("i4", [("r", "I1"), ("g", "I1"), ("b", "I1"), ("a", "I1")]))
- 此方式使得
属性
描述数据类型
|属性|描述| |——-|——-| |
.type|用于实例化此数据类型的数组标量类型| |.kind|内置类型字符码| |.char|内置类型字符码| |.num|内置类型唯一编号| |.str|类型标识字符串|数据大小
|属性|描述| |——-|——-| |
.name|数据类型位宽名称| |.itemsize|元素大小|字节顺序
|属性|描述| |——-|——-| |
.byteorder|指示字节顺序|字段描述
|属性|描述| |——-|——-| |
.fields|命名字段字典| |.names|字典名称列表|数组类型(非结构化)描述
|属性|描述| |——-|——-| |
.subtype|(item_dtype,shape)| |.shape||附加信息
|属性|描述| |——-|——-| |
.hasobject|是否包含任何引用计数对象| |.flags|数据类型解释标志| |.isbuiltin|与内置数据类型相关| |.isnative|字节顺序是否为平台原生| |.descr|__array_interface__数据类型说明| |.alignment|数据类型需要对齐的字节(编译器决定)| |.base|基本元素的dtype|
方法
更改字节顺序
|方法|描述| |——-|——-| |
.newbyteorder([new_order])|创建不同字节顺序数据类型|Pickle协议实现
|方法|描述| |——-|——-| |
.reduce()|pickle化| |.setstate()||
Datetime
- Numpy种时间相关数据类型
- 支持大量时间单位
- 基于POSIX时间存储日期时间
- 使用64位整形存储值,也由此决定了时间跨度
np.datetime64
np.datetime64表示单个时刻- 若两个日期时间具有不同单位,可能仍然代表相同时刻
- 从较大单位转换为较小单位是安全的投射
创建
创建规则
- 内部存储单元自动从字符串形式中选择单位
- 接受
"NAT"字符串,表示“非时间”值 - 可以强制使用特定单位
基本方法:ISO 8601格式的字符串
1
2np.datetime64("2020-05-23T14:23")
np.datetime64("2020-05-23T14:23", "D")从字符串创建日期时间数组
1
2
3np.array(["2020-01-23", "2020-04-23"], dtype="datetime64")
np.array(["2020-01-23", "2020-04-23"], dtype="datetime64[D]")
np.arange("2020-01-01", "2020-05-03", dtype="datetime64[D]")
np.datetime64为向后兼容,仍然支持解析时区
np.timedelta64
np.timedelta64:时间增量
np.timedelta64是对np.datetime64的补充,弥补Numpy对 物理量的支持
创建
创建规则
- 接受
"NAT"字符串,表示“非时间”值数字 - 可以强制使用特定单位
- 接受
直接从数字创建
1
np.timedelta64(100, "D")
从已有
np.timedelta64创建,指定单位- 注意,不能将月份及以上转换为日,因为不同时点进制不同
1
np.timedelta(a, "M")
运算
np.datetime64可以和np.timedelta64联合使用1
2np.datetime64("2020-05-14") - np.datetime64("2020-01-12")
np.datetime64("2020-05-14") + np.timedelta64(2, "D")
相关方法
| Function | Desc |
|---|---|
np.busdaycalendar(weekmask,holidays) |
返回存储有效工作日对象 |
np.busday_offset(date,offset[,roll,weekmask,holidays,busdaycal,out]) |
工作日offset |
np.is_busday(date[,weekmask,holidays,busdaycal,out]) |
判断是否是工作日 |
np.busday_count(begindates,enddates[,weekmask,holidays,busdaycal,out]) |
指定天数 |
np.datetime_as_string(arr[,unit,timezone,...]) |
转换为字符串数组 |
np.datetime_date(dtype,/) |
获取日期、时间类型步长信息 |
np.busday_offset中roll缺省为"raise",要求date本身为工作日