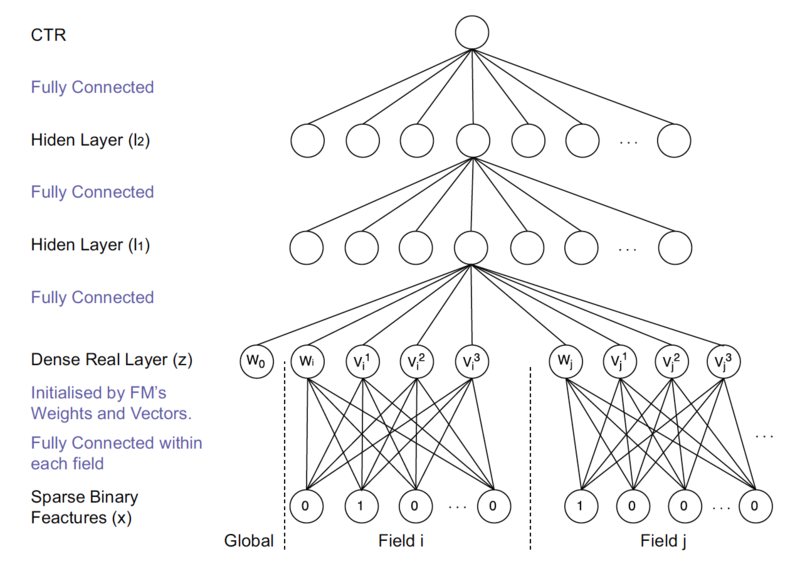
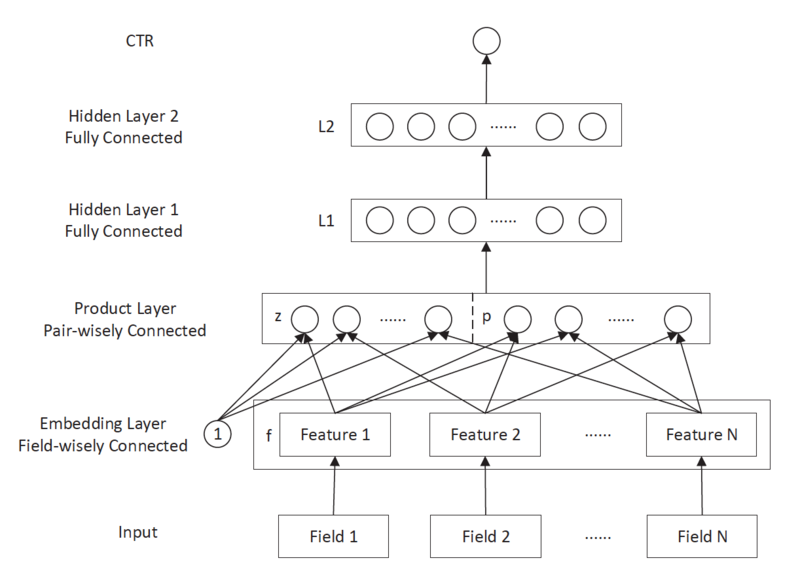
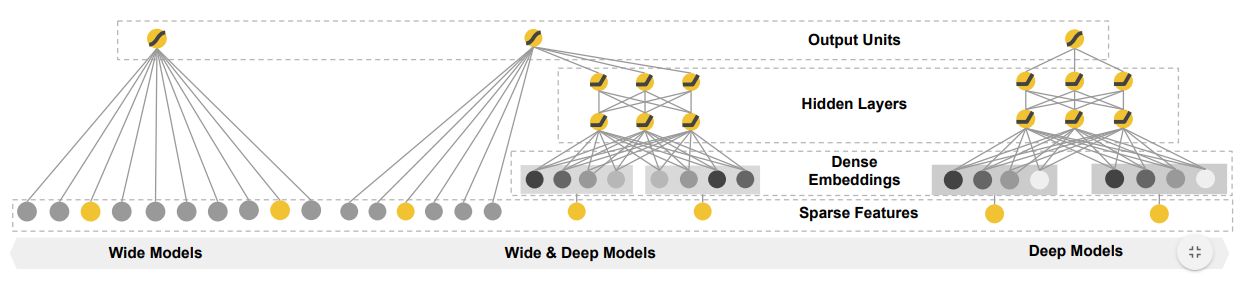
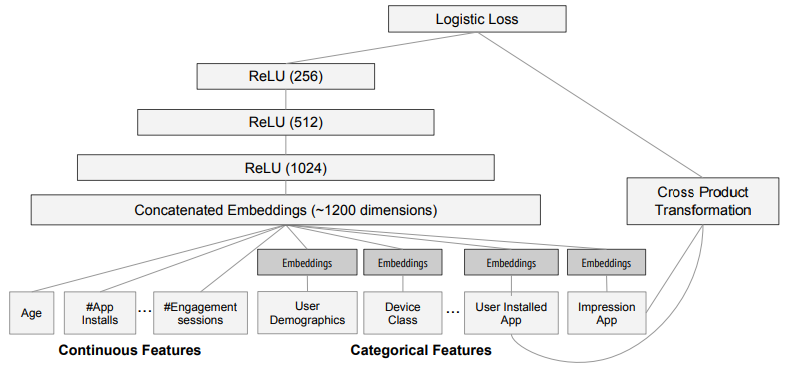
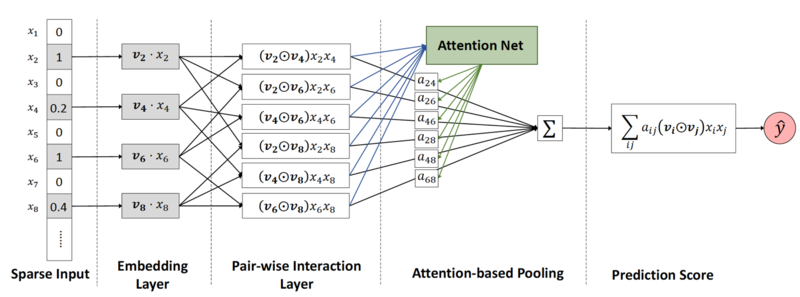
Knapsack(Ws[1..n], Vs[1..n], W) // 动态规划求解背包问题 // 输入:Ws[1..n]物品重量、Vs[1..n]物品价值,W背包承重 // 输出:背包能够装载的最大价值 for i = 0 to n do F[i, 0] = 0 for j = 0 to W do F[0, j] = 0 for i = 1 to n do if j >= Ws[i]: F[i, j] = max(F[i-1, j], Vs[i] + F[i-1, j-Ws[i]) // 这里用于比较的F值,在之前的循环中已经确定 else F[i, j] = F[i-1, j] return F[n, W]
算法特点
算法效率
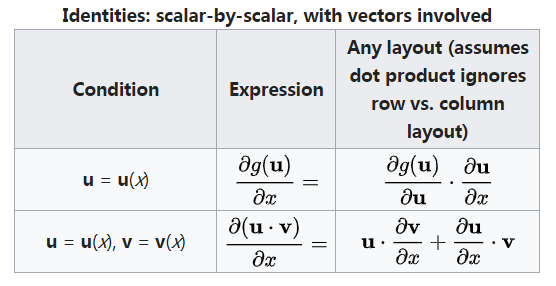
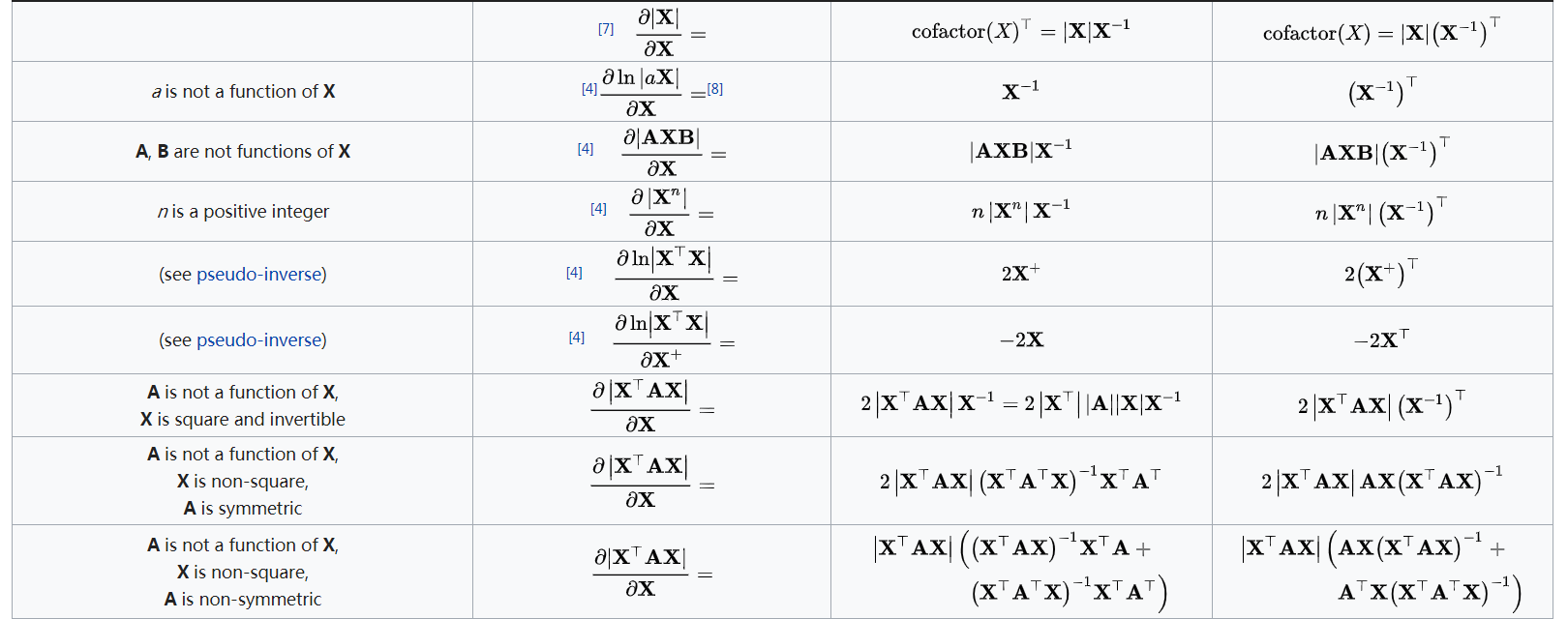
时间效率$\in \Theta(nW)$
空间效率$\in \Theta(nW)$
回溯求最优解组成效率$\in O(n)$
自顶向下动态规划
算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
MFKnapsack(i, j) // 背包问题的记忆功能方法 // 输入:i考虑的物品数量,j背包承重 // 输出:前i个物品的最优可行子集 // Ws[1..n]、Vs[1..n]、F[0..n, 0..W]作为全局变量 for i = 0 to n do F[i, 0] = 0 for j = 0 to W do F[0, j] = 0 if F[i, j] < 0 if j < Ws[i] value = MFKnapsack(i-1, j) else value = max(MFKnapsack(i-1, j), Vs[i] + MFKnapsack(i-1, j - Ws[i])) F[i, j] = value return F[i, j]
算法特点
算法效率
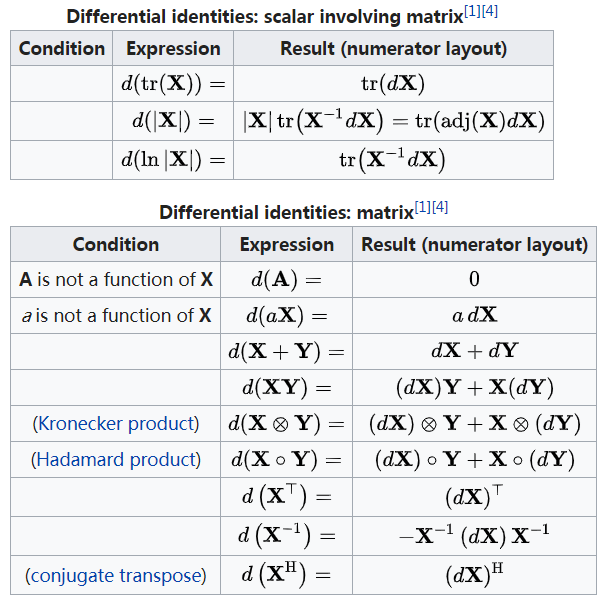
相较于经典自底向上算法,时间效率提升常数因子,但是
效率仍然$\in \Theta(nW)$
相较于自底向上算法空间优化版版本而言,空间效率较低
分支界限法
不失一般性认为,物品按照价值重量比$v_i / w_i$降序排列,
可以简化问题
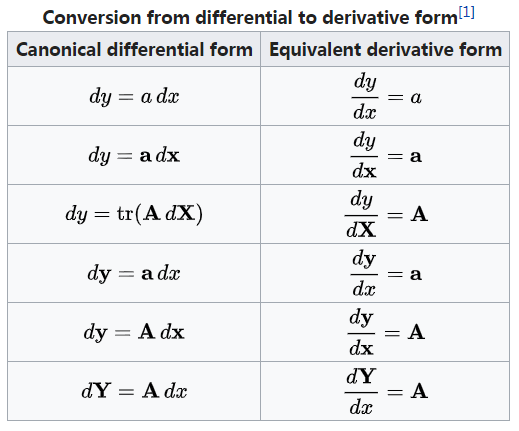
第i层节点上界可取$ub = v + (W - w)(v{i+1} / w{i+1})$
$v$:已选物品价值
$W - w$:背包剩余承重量
$v{i+1}/w{i+1}$:剩余物品单位单位最大价值
更紧密、复杂的上界
$ub = v + \sum{k=i+1}^K v_k + (W - \sum{k=1}^K w_k)v_K / w_K$
ChangeMaking(D[1..m], n) // 动态规划法求解找零问题,d_1 = 1 // 输入:正整数n,币值数组D[1..m] // 输出:总金额为n的最少硬币数目 F[0] = 0 for i = 1 to n do tmp = \infty j = 1 while j <= m and i >= D[j] do tmp = min(F[i-D[j], tmp) j += 1 F[i] = tmp + 1 return F[n]