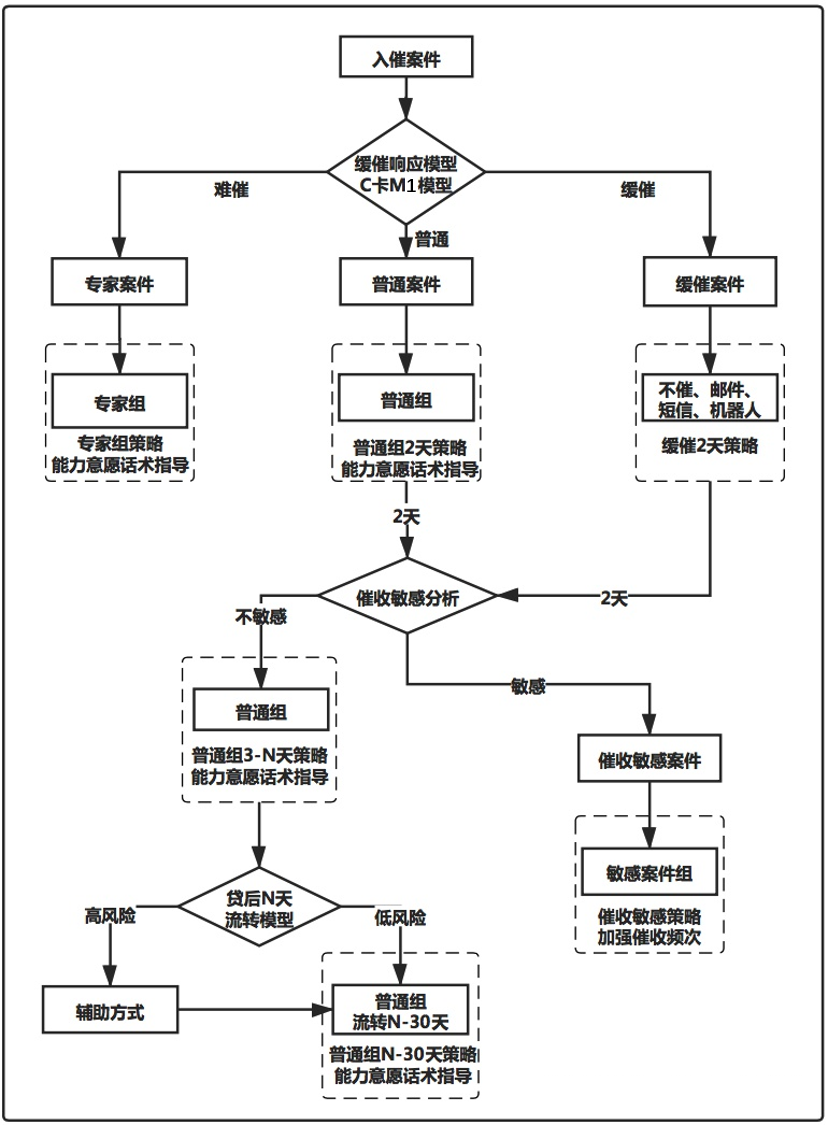
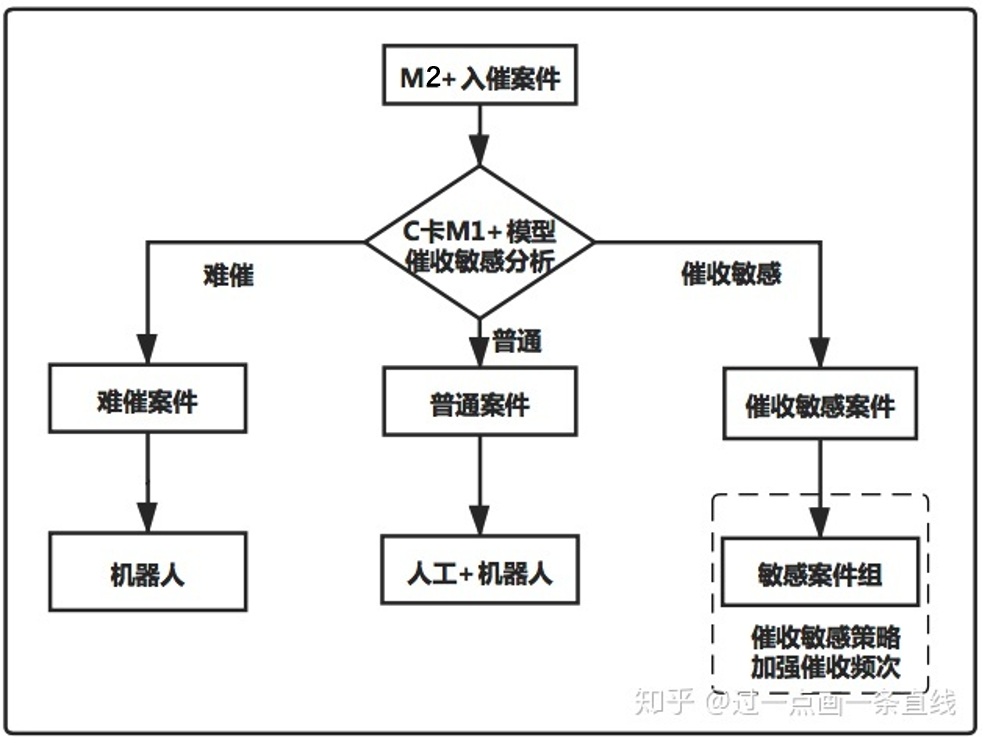
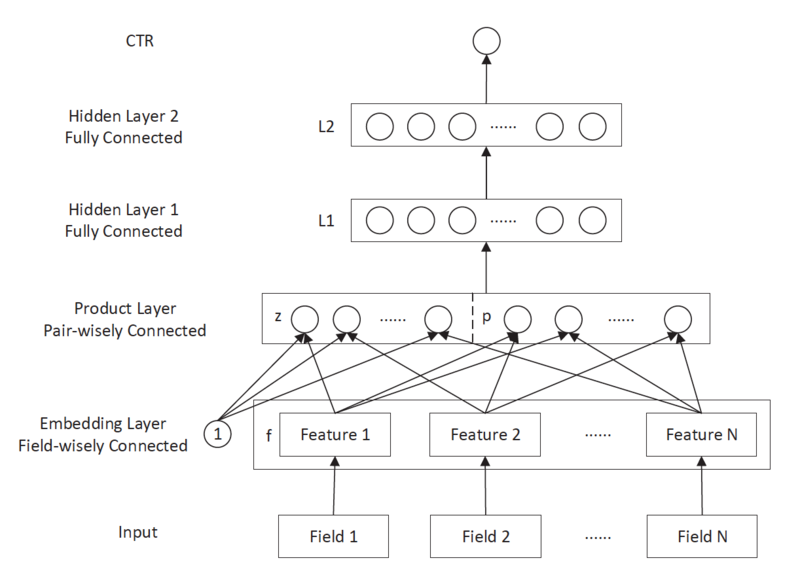
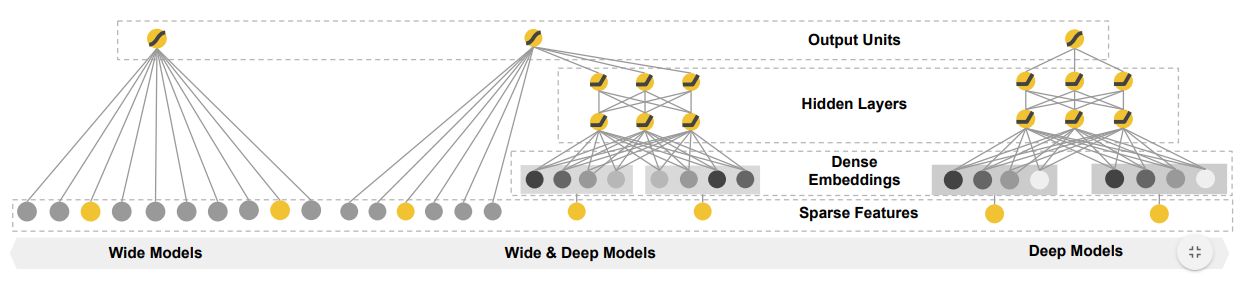
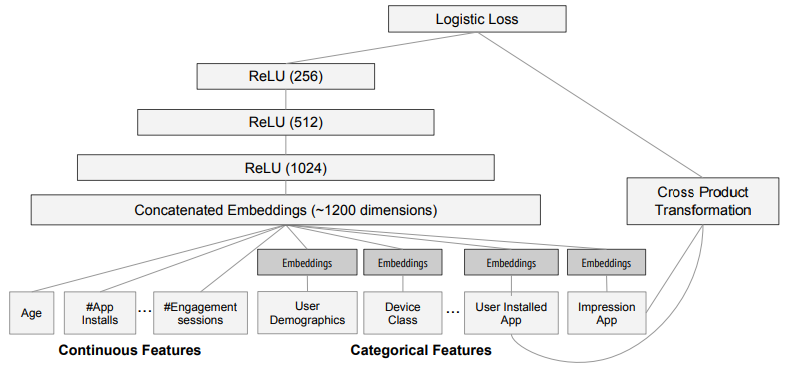
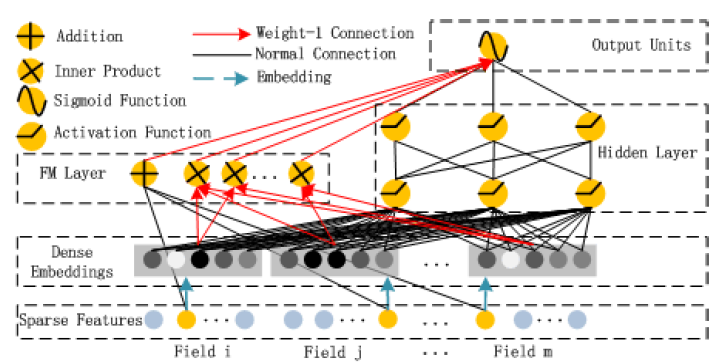
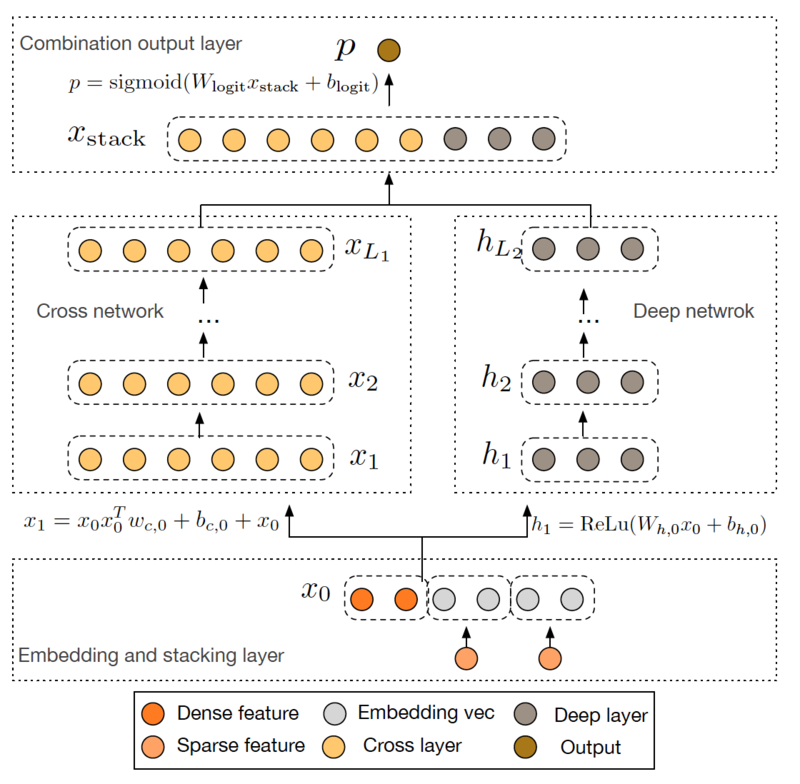
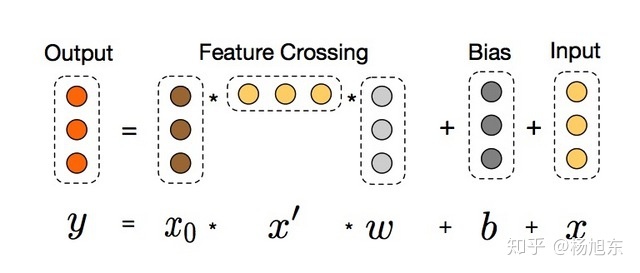
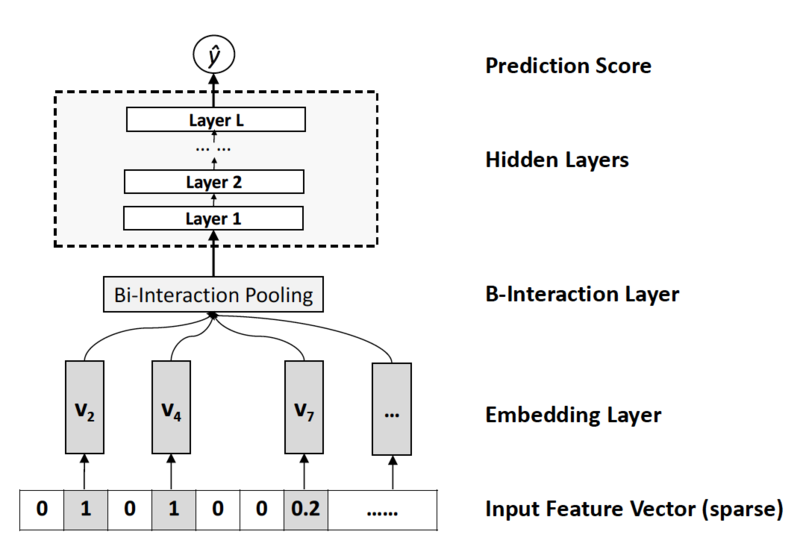
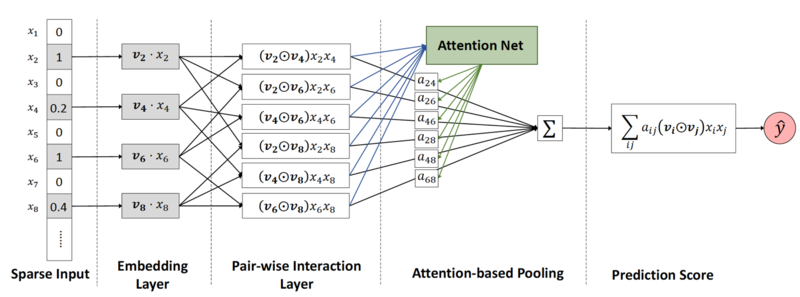
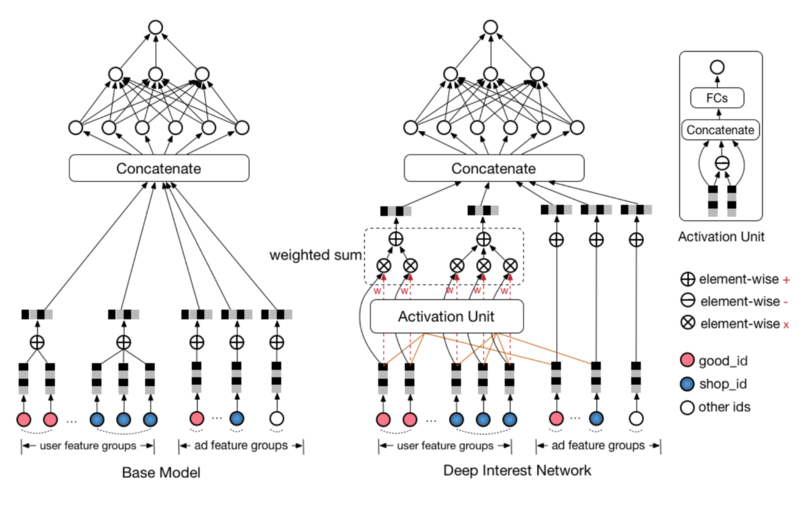
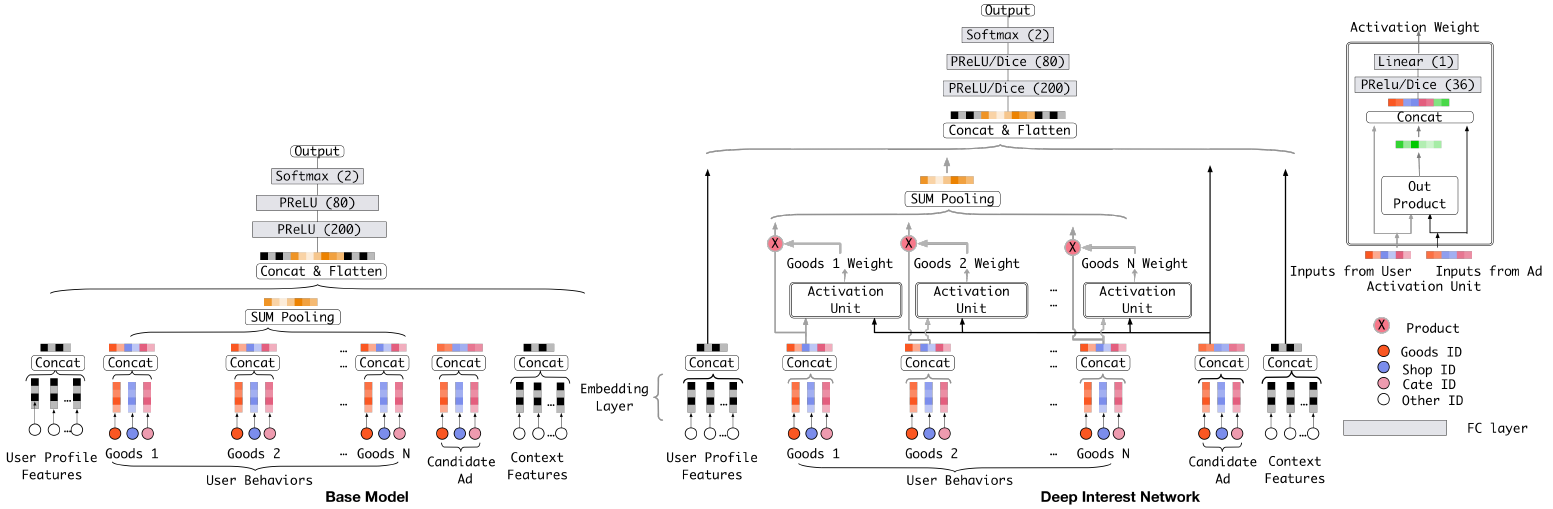
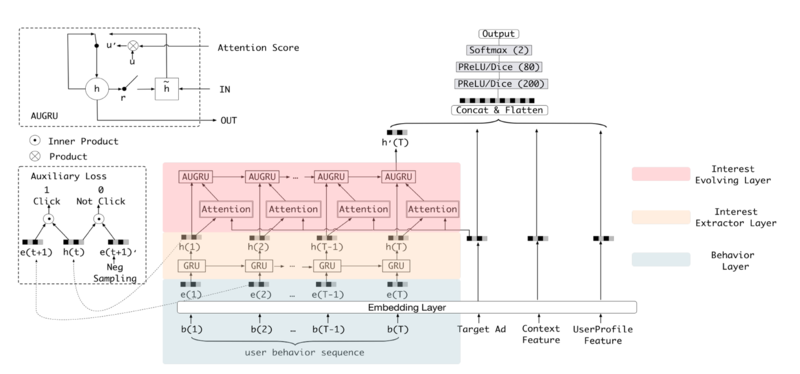
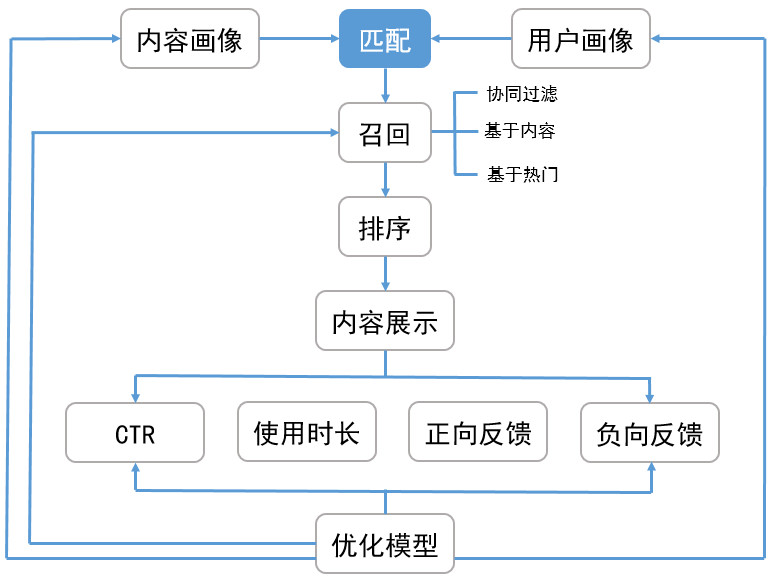
风险控制
欺诈风险
- 欺诈:以故意欺瞒事实而诱使对方发生错误认识的故意行为,通常目的是使欺诈者获利
- 欺诈的行为要素
- 使人发生错误认识为目的
- 故意行为
- 欺诈可以分为
- 冒用:冒用他人身份,通过生物信息技术等容易发现
- 伪装:伪造部分信息,相对而言更难识别
- 金融领域“资金就是生产资料”使得欺诈者的非法获利更容易
- 欺诈的行为要素
欺诈事件
- 白户:账户信息缺失,没有足够数据对借款人进行风险评估
- 内部白户:新注册、无申贷历史记录
- 外部白户:人行征信、三方征信无覆盖
- 黑户:账户存在逾期、失信、欺诈记录
- 内部黑户:历史订单逾期
- 外部黑户:人行征信、三方征信黑
- 论坛、公开渠道监控
- 恶意欺诈:账户通过伪造资料、蓄意骗贷
- 伪造账单流水记录骗取更高额度
- 恶意欺诈账户可能涉及不良嗜好,如黄赌毒等
- 身份冒用:伪冒他人身份进行欺诈骗贷
- 熟人冒用
- 他人盗用
- 一般可通过信审、人脸识别、活体验证核验借款人身份
- 以贷养贷
- 放大共贷风险杠杆
- 可通过三方征信机构的多头借贷产品识别
- 中介欺诈:黑中介哄骗或招揽客户实施骗贷
- 黑中介利用风控漏洞大规模攻击,造成大量资损
- 传销:有组织的开展收费并发展多级下线,存在集中骗贷风险
- 存在老客拉新,从关系网络上具有明显星状结构
欺诈者身份
第一方欺诈:欺诈者用真实身份进行欺诈
- 严格来说不是欺诈,没有在身份信息上误导平台
- 应对措施
- 黑名单
第二方欺诈:企业、渠道内员工进行内部欺诈、内外勾结
- 即巴塞尔协议操作风险中的内部欺诈
- 应对措施
- 内控:权限获取合理、流程上风险分散、操做可追溯
第三方欺诈:非欺诈者自身、企业内部的第三方欺诈
- 名义借贷者身份信息通过黑色产业链购买、养号,作为黑产军团的一个链条
- 申请欺诈
- 账户盗用
- 资料造假
- 恶意违约
- 交易欺诈
- 账户冒险
- 养卡
- 套现
- 应对措施
- 对抗性强、低侵入、性价比各种能力和技术
- 社交网络发现
- 数据交叉对比
- 模型客户用户画像
获取非法收益的时间
First Payment Default 首轮欺诈
- 首期失联
Bust-out 余额欺诈
- 短时间将授信刷高再获利离场
收益来源环节
- 单个客户利润 = 贷款收益 - 资金成本 - 信用成本 - 获客成本
- 获客成本 - 税收成本
- 骗贷:信用成本中的风险成本
- 羊毛:获客成本中的补贴
- 刷量:获客成本中的广告费
- 虚假短信:运营费用中的短信流量费
得利方、损失方
- C骗C:在互金领域不多
- 即使是P2P,也会有平台兜底
- B骗C
- C骗B
- B骗B
反欺诈
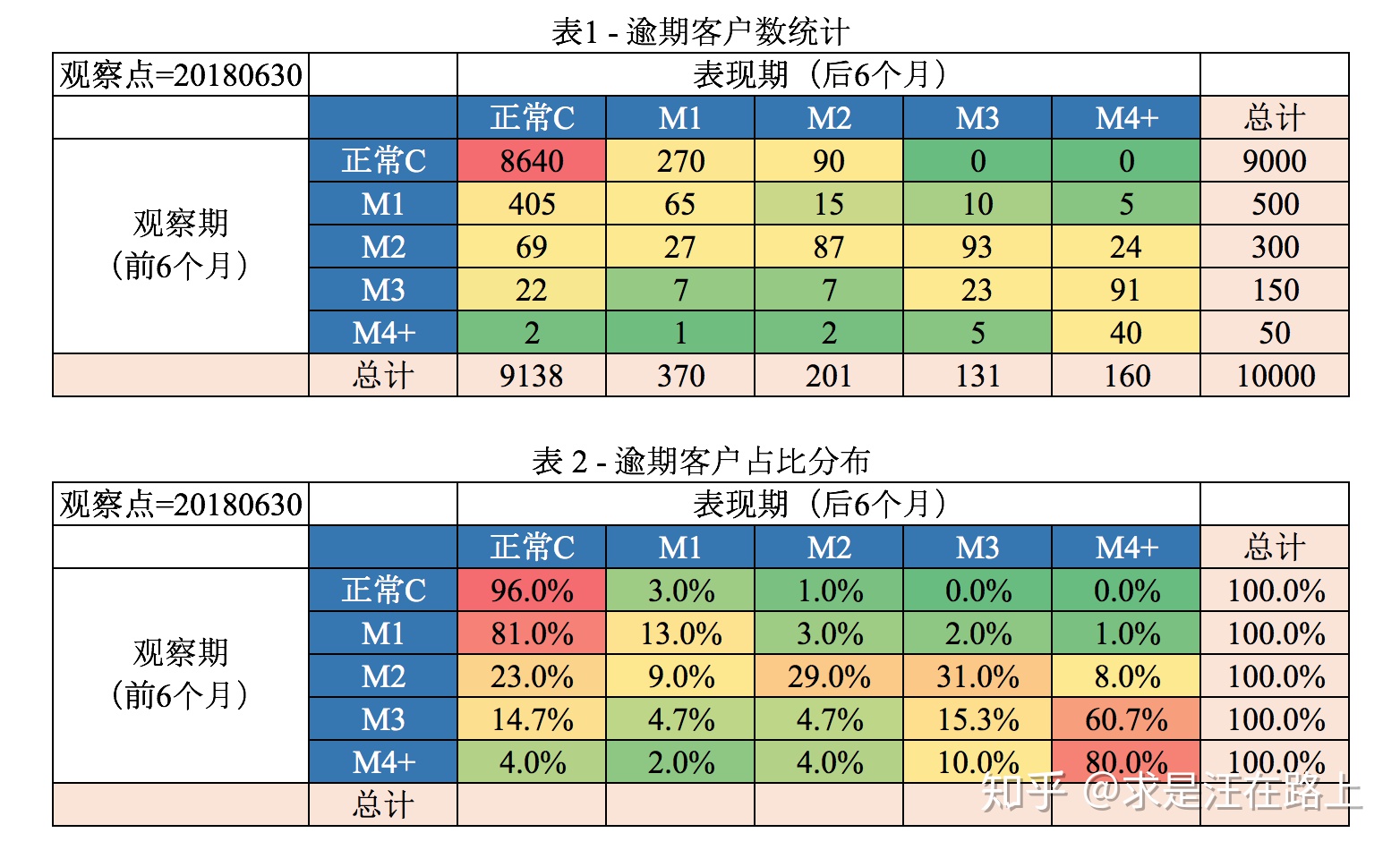
防范欺诈的重要障碍是欺诈难以标注,是通过贷后表现推断贷前 意图
- 一般只有真正联系到本人或失联,很难有足够证据证明是欺诈导致的逾期,而不是信用导致逾期
- 欺诈导致逾期往往有以下特征
- 首逾:最常作为欺诈指标
- 对第一方、第三方欺诈,往往会发生首逾
- 对第二方欺诈,考虑到内部人员的考核、规避等 原因,有可能会正常还款1到2期,此类欺诈较难认定
- 催收追回率更高
- 首逾:最常作为欺诈指标
反欺诈调研步骤
- 风险事件发现:具有敏锐的风险嗅觉,发现可疑事件
- 欺诈场景还原:广泛收集各渠道信息还原欺诈场景,调研分析背后可能原因
- 风险规则提炼:从欺诈场景中提炼相应专家规则,拦截欺诈
- 技术算法支持:搜集相应数据,根据数据类型和场景特点寻找合适算法识别欺诈
反欺诈除了常规的策略部署外,还需要考虑人性:延迟模型和规则的效用
- 抓大放小:允许小资损,随机抽取小比例的欺诈者通过
- 隐藏防控点,用于积累黑名单
- 迷惑欺诈团伙
- 虚假额度:设置虚假授信额度,但借口其他理由不放款
- 抓大放小:允许小资损,随机抽取小比例的欺诈者通过
调研欺诈风险渠道
- 实时大盘监控:适合识别黑中介风险、传销风险等团伙欺诈
- 设备聚集性风险 LBS、WIFI
- 地域欺诈风险,如朋克村
- 信审催收反馈
- 通过电话外呼、核验用户身份、咨询借款动机,根据用户反应发现身份伪冒
- 论坛舆情监控
- 对相关论坛、讨论组等检测仪监控,发现市场动向
- 理解欺诈人群的心理特征、社会身份
- 黑产卧底调研
- 线上加入相关社区,站在欺诈账户立场上,找寻风控系统弱点
- 线下去欺诈案件多发地,实地调研、学习黑产手法
反欺诈专家规则
针对网贷黑中介识别的风险规则
- 中介通讯录长常常会存储客户号码,并加以备注
- 因为需要联系客户,运营商数据中往往会留下痕迹
- 中介网贷申请手法更熟练,在申请页面停留时间短
- 使用网络可能包含“网贷”等敏感信息
- 人脸活体验证时存在照片翻拍、视频通话
对反欺诈规则同样可按照一般规则进行评价
- 规则欺诈命中次数、命中率
- 规则欺诈命中次数 = 命中触发报警之后被认定为欺诈次数
- 欺诈命中率 = 规则欺诈命中次数 / 规则报警次数
- 综合欺诈命中次数
- 综合欺诈次数 = 规则欺诈命中次数 + 逾期调查认定欺诈数
- 综合欺诈命中率
- 考虑到欺诈逾期特征,可以把首逾、催收回账户重点调查
- 规则欺诈命中次数、命中率
- 专家规则有高准确率的优点,但是覆盖的人群有限,性价比低,过多会导致规则集冗长,不利于维护
反欺诈算法
应用方向
- 辅助调查人员从单个案件的调查上升到对团体的调查,提高人工审核效率
- 通过用户之间的关联关系,给调查人员提供更多分析线索
算法研究方向
- 基于社交网络的模型
- 基于通讯录、运营商数据,采用基于图的社区发现算法
- 基于无监督聚类的模型
- 知识图谱
- Embedding 特征构建
- 基于埋点行为数据,生成 Embedding 特征
- 文本分类
- 基于论坛文本、通讯录名称、WIFI 名称分类
- 基于社交网络的模型
First Payment Deliquency模型
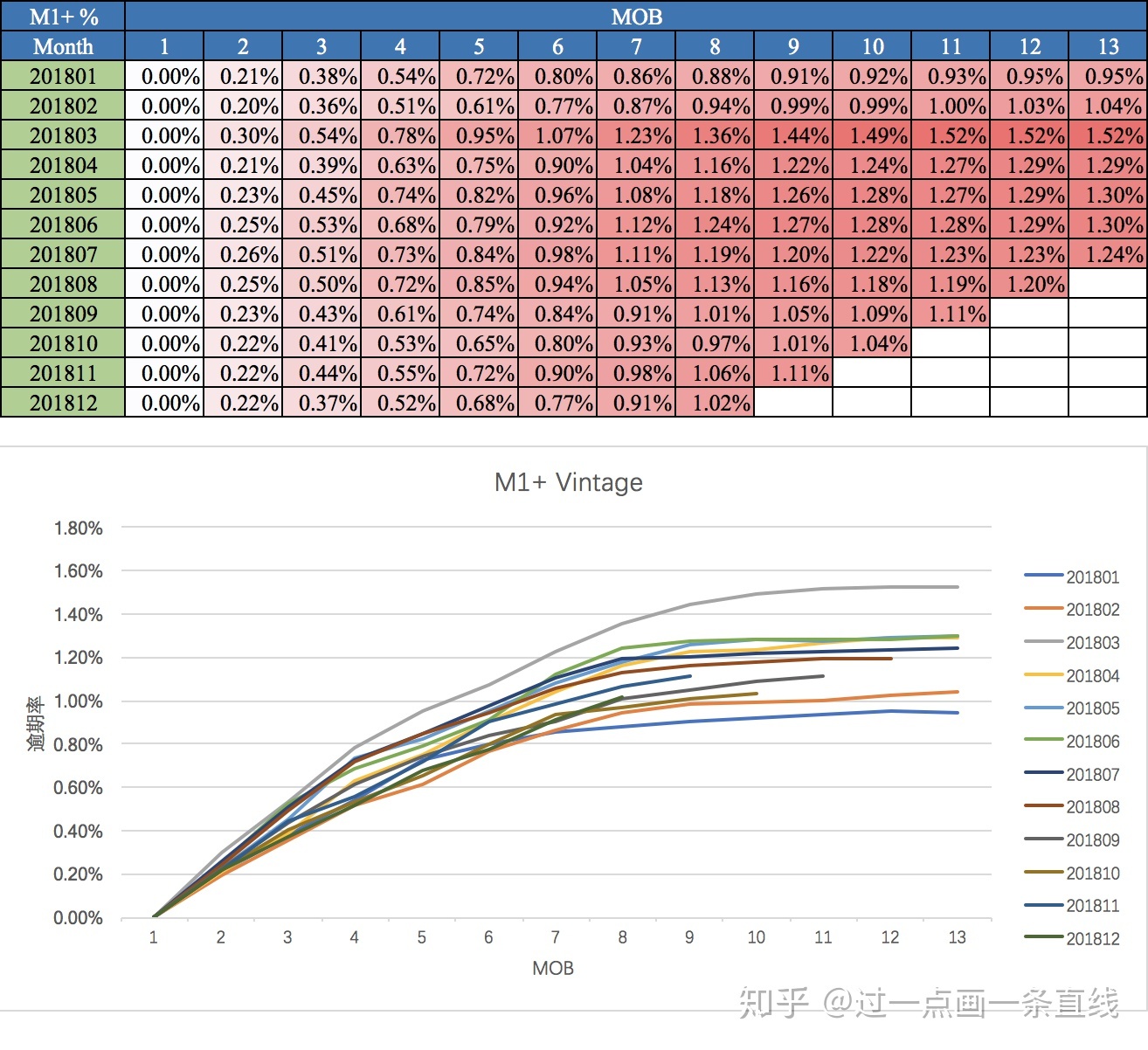
FPD 模型:以首逾作为目标变量建立模型
- 假设:欺诈者动机是骗钱,那么第一期就会逾期
- 入模变量一般是负面特征
- 安装负面 App 数量
- 历史逾期次数
基于欺诈的还款表现作为理论支撑,但是也存在一定缺陷
- 逾期标签存在滞后性,首逾标签存在至少一个月,不利于快速响应
- 放贷样本同总体有偏,在其上训练模型存在偏差,会低估风险