查找
总述
在给定的集合、多重集(允许多个元素具有相同的值)中找给定值 (查找键,search key)
- 顺序搜索
- 折半查找:效率高但应用受限
- 将原集合用另一种形式表示以方便查找
评价
没有任何一种查找算法在任何情况下都是最优的
- 有些算法速度快,但是需要较多存储空间
- 有些算法速度快,但是只适合有序数组
查找算法没有稳定性问题,但会发生其他问题
如果应用里的数据相对于查找次数频繁变化,查找问题必须结合 添加、删除一起考虑
必须仔细选择数据结构、算法,以便在各种操作的需求间达到 平衡
无序线性表查找
顺序查找
算法
- 将给定列表中连续元素和给定元素查找键进行比较
- 直到遇到匹配元素:成功查找
- 匹配之前遍历完整个列表:失败查找
1 | SequentialSearch(A[0..n-1], K) |
改进
- 将查找键添加找列表末尾,查找一定会成功,循环时将不必每次 检查是否到列表末尾
- 如果给定数组有序:遇到等于(查找成功)、大于(查找失败) 查找键元素,算法即可停止
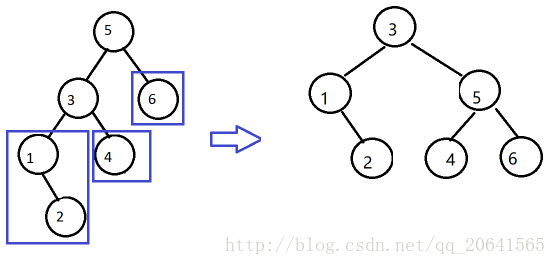
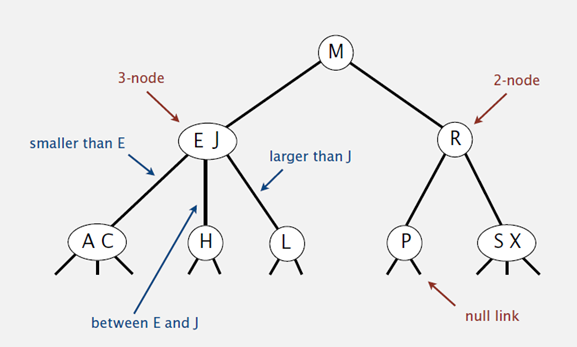
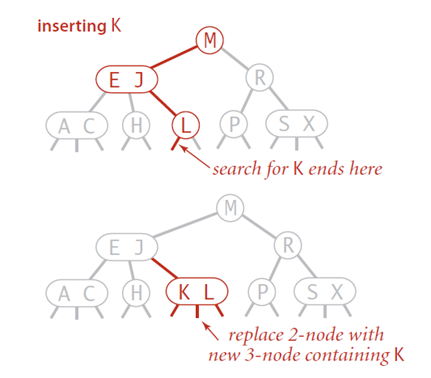
二叉查找树
算法
- 对数组构建二叉查找树
- 在二叉查找树上进行查找
特点
算法效率:参见二叉查找树
构建二叉查找树(插入)和查找操作基本相同,效率特性也相同
减可变规模 + 输入增强
预排序查找
对线性表预排序,有序表中查找速度快得多
算法
1 | PreorderSearch(A[0..n-1]) |
特点
算法时间效率:取决于排序算法
- 查找算法在最差情况下总运行时间$\in \Theta(nlogn)$
- 如果需要在统一列表上进行多次查找,预排序才值得
这种预排序思想可以用于众数、检验惟一性等, 此时算法执行时间都取决于排序算法 (优于蛮力法$\in \Theta(n^2)$)
变治法(输入增强)
预排序检验唯一性
1 | PresortElementUniqueness(A[0..n-1]) |
预排序求众数
1 | PresortMode(A[0..n-1]) |
有序顺序表查找
有序顺序表的查找关键是利用有序减规模
但关键不是有序,而是减规模,即使顺序表不是完全有序, 信息足够减规模即可
折半查找/二分查找
二分查找:利用数组的有序性,通过对查找区间中间元素进行判断, 缩小查找区间至一般大小
依赖数据结构,需能够快速找到中间元素,如数组、二叉搜索树
一般模板:比较中间元素和目标的大小关系、讨论
1
2
3
4
5
6
7
8
9left, right = ...
while condition(search_space is not NULL):
mid = (left + right) // 2
if nums[mid] == target:
// do something
elif nums[mid] > target:
// do something
elif nums[mid] < target:
// do somthing- 函数独立时,找到
target可在循环内直接返回 - 函数体嵌入其他部分时,为方便找到
target应break, 此时涉及跳出循环时target可能存在的位置- 找到
target中途break - 未找到
target直到循环终止条件
- 找到
- 函数独立时,找到
基本版
1 | BinarySearchEndReturnV1(nums[0..n-1], target): |
输入判断:无需判断输入列表是否为空
- 终止条件保证不会进入,即不会越界
初始条件:
left, right = 0, n-1- 左、右均未检查、需检查
- 即代码中查找区间为闭区间$[left, right]$,此时 搜索区间非空
中点选择:
mid = (left + right) // 2- 向下取整
- 对此版本无影响,
left、right总是移动,不会死循环
循环条件:
left <= right- 搜索区间为闭区间,则相应检查条件为
left <= right, 否则有元素未被检查 - 在循环内
left、right可能重合
- 搜索区间为闭区间,则相应检查条件为
更新方式:
left=mid+1, right=mid-1- 为保证搜索区间始终为闭区间,需剔除
mid
- 为保证搜索区间始终为闭区间,需剔除
终止情况:
right=left-1、mid=left/right- 循环条件、循环内部
+1保证:上轮循环left==right - 越界终止情况:左、右指针均剔除
mid,两侧均可能越界mid=right=n-1, left=nmid=left=0, right=-1
- 循环条件、循环内部
target位置- 若存在
target:必然在mid处,循环结束只需判断mid - 若不存在
targettarget位于[right, left]间left=mid+1=right+1表示小于target元素数量
- 若存在
- 需要和左右邻居(查找结束后)、
left、right比较 情况下,容易考虑失误,不适合扩展使用
高级版1
1 | BinarySearchV2(nums[0..n-1], target): |
输入判断:无需判断输入列表是否为空
- 终止条件保证不会进入,即不会越界
初始条件:
left, right = 0, n- 左未检查、需检查,右无需检查
- 即代码中查找区间为左闭右开区间$[left, right)$
中点选择:
mid = (left + right) // 2- 向下取整
- 此处必须选择向下取整,否则
left=right-1时进入死循环 - 即:循环内检查所有元素,取整一侧指针必须移动
循环条件:
left < right- 搜索区间为左闭右开区间,则检查条件为
left < right, 此时搜索区间非空 - 在循环内
left、right不会重合
- 搜索区间为左闭右开区间,则检查条件为
更新方式:
left=mid+1, right=mid- 为保证搜索区间始终为左闭右开区间
- 移动左指针时需剔除
mid - 移动右指针时无需剔除
mid
- 移动左指针时需剔除
- 为保证搜索区间始终为左闭右开区间
终止情况:
right=left、mid=left/left-1- 循环条件、循环内部
+1保证:上轮循环left+1=mid=right-1left=mid=right-1
- 越界终止情况:仅左指针剔除
mid,仅可能右侧越界left=right=n=mid+1
- 循环条件、循环内部
target位置- 若存在
target:必然在mid处,循环结束只需判断mid - 若不存在
targetleft=mid=right:循环过程中target可能已不在 搜索区间中,最终位于(mid-1, mid)mid+1=left=right:(mid, left)left表示小于target元素数量
- 若存在
高级版2
1 | BainarySearchEndReturnV3(nums[0..n-1], target): |
输入判断:无需判断输入列表是否为空
- 终止条件保证不会进入,即不会越界
初始条件:
left, right = -1, n-1- 左无需检查,右未检查、需检查
- 即代码中查找区间为左开右闭区间$(left, right]$
中点选择:
mid = (left + right + 1) // 2- 向上取整
- 此处必须选择向上取整,否则
left=right-1时进入死循环 (或放宽循环条件,添加尾判断) - 即:循环内检查所有元素,取整一侧指针必须移动
循环条件:
left < right- 搜索区间为左开右闭区间,则检查条件为
left < right, 此时搜索区间非空 - 在循环内
left、right不会重合
- 搜索区间为左开右闭区间,则检查条件为
更新方式:
left=mid, right=mid+1- 为保证搜索区间始终为左闭右开区间
- 移动右指针时需剔除
mid - 移动左指针时无需剔除
mid
- 移动右指针时需剔除
- 为保证搜索区间始终为左闭右开区间
终止情况:
left=right、mid=left/left+1- 循环条件、循环内部
+1保证:上轮循环left+1=mid=right-1left+1=mid=right
- 越界终止情况:仅右指针剔除
mid,仅可能左侧越界left=right=-1=mid-1
- 循环条件、循环内部
target位置- 若存在
target:必然在mid处,循环结束只需判断mid - 若不存在
targetleft=mid=right:循环过程中target可能已不在 搜索区间中,最终位于(right, right+1)mid+1=left=right:(left, right)left+1表示小于target元素数量
- 若存在
高级版3
1 | BinarySearchEndReturnV2(nums[0..n-1], target): |
输入判断:无需判断输入列表是否为空
- 终止条件保证不会进入,即不会越界
初始条件:
left, right = -1, n- 左、右均无需检查
- 即代码中查找区间为开区间$(left, right)$
中点选择:
mid = (left + right) // 2- 向下取整、向上取整均可
循环条件:
left < right-1- 搜索区间为左开右闭区间,则检查条件为
left < right-1, 此时搜索区间非空 - 在循环内
left、right不会重合
- 搜索区间为左开右闭区间,则检查条件为
更新方式:
left=mid, right=mid- 循环终止条件足够宽泛,不会死循环
终止情况:
left=right-1、mid=right/right-1- 循环条件、循环内部
+1保证:上轮循环left+1=mid=right-1
- 越界终止情况:左右初始条件均越界,则左、右均可能越界
mid=left=n-1、right=nleft=-1、mid=right=0
- 循环条件、循环内部
target位置- 若存在
target:必然在mid处,循环结束只需判断mid - 若不存在
targettarget始终在搜索区间(left, right)内- 最终位于
(left, right)
- 若存在
高级版1-原
1 | BinarySearchKeep1(nums[0..n-1], target): |
- 初始条件:
left = 0, right = n-1- 终止情况:
left = right - 1- 指针移动:
left = mid, right= mid
关键特点
n>1时left、mid、right循环内不会重合mid可以left、right任意比较,无需顾忌重合- 需要和左右邻居、
left、right比较时适合使用 - 扩展使用需要进行真后处理,对
left、right进行判断
终止情况:
left = right - 1- 循环过程中会保证查找空间至少有3个元素,剩下两个 元素时,循环终止
- 循环终止后,
left、right不会越界,可以直接检查
target位置若存在
target,可能位于mid、left、rightmid:因为找到nums[mid]==target跳出left:left=0,循环中未检查right:right=n-1,循环中未检查
不存在
target,则target位于(left, right)之间适合访问目标在数组中索引、极其左右邻居
仅仅二分查找的话,后处理其实不能算是真正的后处理
nums[mid]都会被检查,普通left、right肯定不会 是target所在的位置真正处理的情况:
target在端点left=0, right=1终止循环,left=0未检查left=n-2, right=n-1终止循环,right=n-1未检查
即这个处理是可以放在循环之前进行处理
高级版2-原
1 | BinarySearchKeep0(nums[0..n-1], target): |
- 初始条件:
left = 0, right = n,保证n-1可以被正确处理- 终止情况:
left = right- 指针移动:
left = mid + 1, right = mid- 中点选择对此有影响,指针移动行为非对称,取
ceiling则 终止情况还有left = right + 1
关键特点
left、right循环内不会重合- 由于
floor的特性,mid可以right任意比较,无需 顾忌和right重合 - 需要和右邻居、
right比较时适合使用
终止情况:
left = right- 循环过程中会保证查找空间至少有2个元素,否则循环 终止
- 循环终止条件导致退出循环时,可能
left=right=n越界
target位置- 若存在
target,可能位于mid、left=right - 若不存在
target,则target位于(left-1, left) - 适合访问目标在数组中索引、及其直接右邻居
- 若存在
仅二分查找,甚至无需后处理
判断
nums长度在某些语言中也可以省略
高级版3-原
1 | BinarySearchNoKeep(nums[0..n-1], target): |
- 初始条件:
left = -1, right = n-1- 终止情况:
left = right、left = right + 1- 指针移动:
left = mid, right = mid - 1- 中点选择对此有影响,指针移动行为非对称,取
ceiling则 同高级版本2
终止条件:
left = right、left = right - 1循环过程中保证查找空间至少有3个元素,否则循环 终止
由于
floor特性,必须在left < right - 1时即终止 循环,否则可能死循环循环终止后,
left=right=-1可能越界
target位置- 若存在
target,可能位于mid、left=right - 若不存在
target,则target位于(left, left+1) - 适合访问目标在数组中索引、及其直接左邻居
- 若存在
此版本仅想实现二分查找必须后处理
终止条件的原因,最后一次
right=left + 1时未被检查 即退出循环可能在任何位置发生,不是端点问题
特点
前两个版本比较常用,最后两个版本逻辑类似
折半查找时间效率
- 最坏情况下:$\in \Theta(log n)$
- 平均情况下仅比最差稍好
就依赖键值比较的查找算法而言,折半查找已经是最优算法 ,但是插值算法、散列法等具有更优平均效率
减常因子因子法
插值查找
Interpolation Search:查找有序数组,在折半查找的基础上考虑 查找键的值
算法
假设数组值是线性递增,即数字值~索引为一条直线,则根据 直线方程,可以估计查找键K在A[l..r]所在的位置
若k == A[x],则算法停止,否则类似折半查找得到规模更小的 问题
特点
即使数组值不是线性递增,也不会影响算法正确性,只是每次 估计查找键位置不够准确,影响算法效率
统计考虑
- 折半插值类似于非参方法,只考虑秩(索引)方向
- 插值查找类似参数方法,构建了秩(索引)和数组值模型, 但是线性关系基于假设
- 如果模型错误可能会比折半查找效率更差,即在数据分布 分布偏差较大的情况下非参方法好于参数方法
所以是否可以考虑取样方法,先取5个点构建模型,然后估计
算法效率
- 对随机列表,算法比较次数小于$log_2log_n+1$
- 最差情况,比较次数为线性,没有折半查找稳定
- Robert Sedgewick的Algorithms中研究表明,对较小文件 折半查找更好,大文件、比较开销大插值查找更好
减可变规模
子串匹配
蛮力字符串匹配
算法
- 将pattern对齐文本前m个字符,从左向右匹配相应字符
- m个字符全部匹配,匹配成功,算法停止
- 遇到不匹配字符则
- 模式右移1位,然后从模式首个字符开始重复以上匹配
- 在n-m位置无法匹配成功,则无足够匹配字符,算法停止
1 | BruteForceStringMatch(T[0..n-1], P[0..m-1]) |
特点
- 最坏情况下,算法比较次数属于$O(nm)$
- 即在移动模式之前,算法需要做足m次比较
- 但是一般在自然语言中,算法平均效率比最差好得多
- 在随机文本中,有线性效率
Horspool算法
算法从右往左匹配,在任意位置匹配不成功时只考虑
同模式最后字符匹配的文本字符c,确定安全移动距离,在
不会错过匹配子串的情况下移动最长距离
- 如果
c在模式中出现,则模式移动到其最后c至同文本中c匹配 - 否则移动模式长度m
- 特别的,如果
c只在模式最后字符出现,则也应该移动m
算法
- 对给定长度m的模式及文本中用到的字母表,构造移动表
t - 将模式同文本开始对齐
- 重复以下过程直至发了了匹配子串或模式达到了文本字符外
- 从模式最后字符开始,比较模式、文本相应字符
- 若m个字符匹配,停止
- 遇到不匹配字符
c,若为当前文本中和模式最后匹配字符 对齐的字符,将模式移动t(c)个字符
1 | ShiftTable(P[0..m-1]) |
1 | HorspoolMatching(P[0..m-1], T[0..n-1]) |
特点
算法效率
- 最差情况下模式为相同字符,效率$\in O(nm)$
- 对随机文本效率$\in O(n)$
输入增强
Boyer-Moore算法
- 坏符号移动:模式、文本中相应不匹配字符确定的移动 (不是Horspool中简单根据最后字符确定移动)
- 好后缀移动:模式、文本匹配的后缀确定的移动
算法
- 对给定长度m的模式及文本用到的字母表,构造坏符号移动表
t - 对给定长度m的模式构造后缀移动表
- 将模式与文本开始处对齐
- 重复以下直到找到匹配子串或模式达到文本字符以外
- 从模式最后字符开始比较模式、文本相应字符
- 所有m个字符匹配,则停止
- 若
c是不匹配字符,移动坏符号表、后缀移动表决定的 距离较大者
1 | BadSymbolShift(P[0..m-1]) |
特点
算法效率
- 算法效率最差也是线性的
输入增强
KMP算法
算法从左往右匹配,失败时不回溯指针,利用已经得到的 部分匹配结果尽可能将模式滑动一段距离,从模式中间next 字符开始比较
算法
1 | KMPShift(P[0..m-1]) |
1 | KMPShiftVal(P[0..m-1]) |
1 | KMPMatching(P[0..m-1], T[0..n-1]) |
特点
算法效率
- 算法时间效率$\in O(m+n)$
文本指针不需要回溯,整个匹配过程只需要对文本扫描一次, 对流程处理十分有效,可以边读边匹配
输入增强