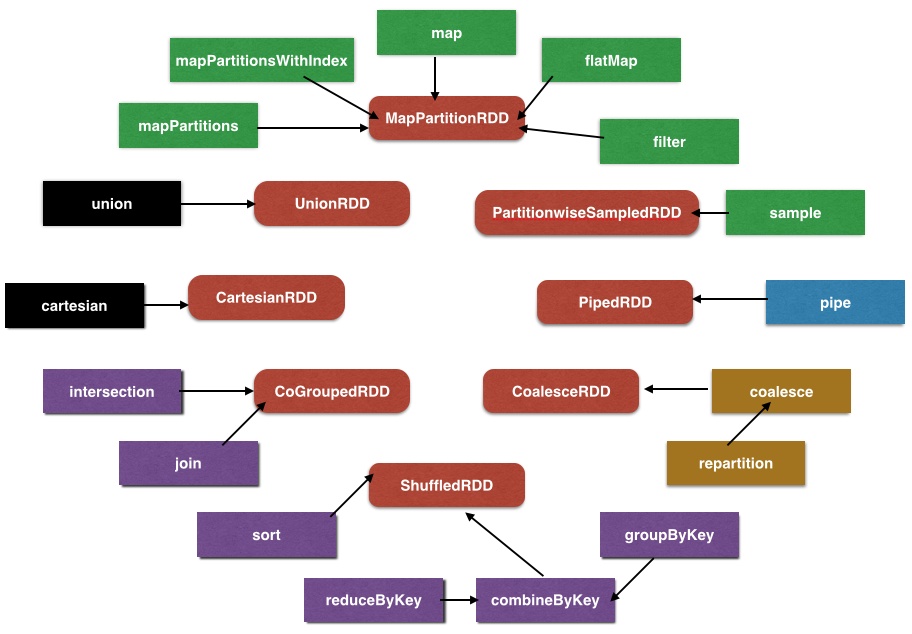
Spark Core
Spark特性
数据处理速度快
得益于Spark的内存处理技术、DAG执行引擎
内存计算
Spark尽量把数据(中间结果等)驻留在内存中,必要时才写入 磁盘,避免I/O操作,提高处理效率
支持保存部分数据在内存中,剩下部分保存在磁盘中
数据完全驻留于内存时,数据处理达到hadoop系统的 几十~上百倍,数据存在磁盘上时,处理速度能够达到hadoop的 10倍左右
DAG执行引擎
Spark执行任务前,根据任务之间依赖关系生成DAG图,优化数据 处理流程(减少任务数量)、减少I/O操作
除了简单的map、reduce,Spark提供了超过80个数据处理的 Operator Primitives
对于数据查询操作,Spark采用Lazy Evaluation方式执行, 帮助优化器对整个数据处力工作流进行优化
易用性/API支持
Spark使用Scala编写,经过编译后在JVM上运行
支持各种编程语言,提供了简洁、一致的编程接口
- Scala
- Java
- Python
- Clojure
- R
通用性
Spark是通用平台,支持以DAG(有向无环图)形式表达的复杂 数据处理流程,能够对数据进行复杂的处理操作,而不用将复杂 任务分解成一系列MapReduce作业
Spark生态圈DBAS(Berkely Data Analysis Stack)包含组件, 支持批处理、流数据处理、图数据处理、机器学习
兼容性
DataStorage
- 一般使用HDFS、Amazon S3等分布式系统存储数据
- 支持Hive、Hbase、Cassandra等数据源
- 支持Flume、Kafka、Twitter等流式数据
Resource Management
- 能以YARN、Mesos等分布式资源管理框架为资源管理器
- 也可以使用自身资源的管理器以Standalone Mode独立运行
使用支持
- 可以使用shell程序,交互式的对数据进行查询
- 支持流处理、批处理
数据类型、计算表达能力
- Spark可以管理各种类型的数据集:文本
Spark架构
核心组件
- Spark Streaming、Spark SQL、Spark GraphX、 Spark MLLib为BDAS所包含的组件
Spark Streaming:提供对实时数据流高吞吐、高容错、可 扩展的流式处理系统
- 采用Micro Batch数据处理方式,实现更细粒度资源分配, 实现动态负载均衡
- 可以对多种数据源(Kafka、Flume、Twitter、ZeroMQ),进行 包括map、reduce、join等复杂操作
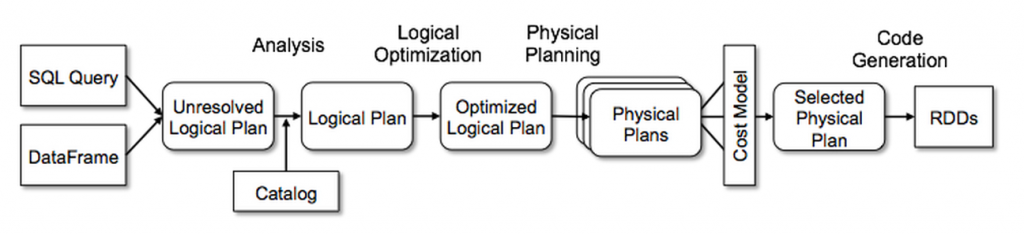
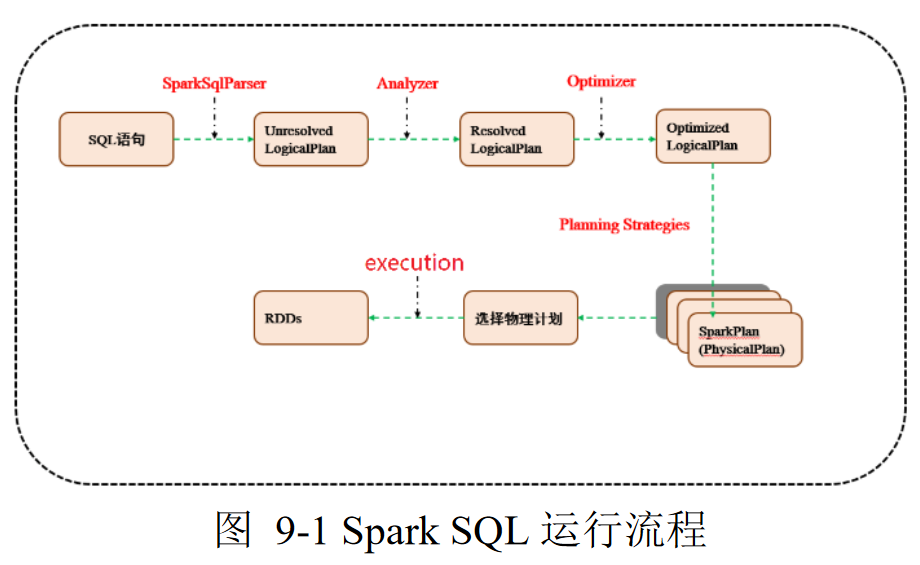
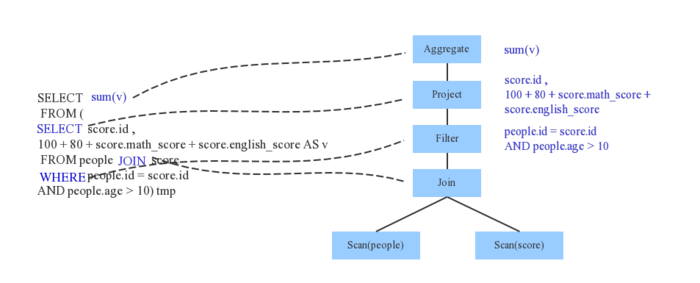
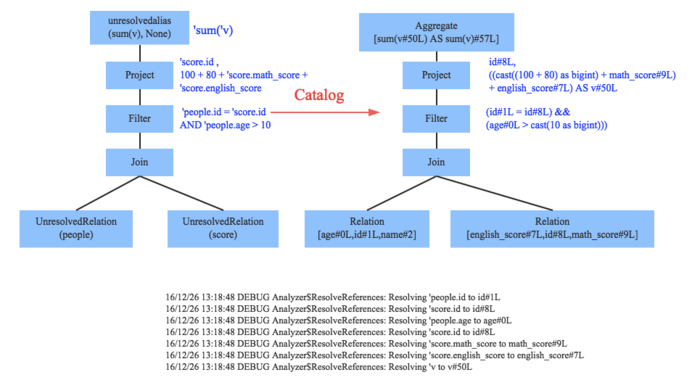
Spark SQL:结构化数据查询模块
- 通过JDBC API暴露Spark数据集,让客户程序可以在其上 直接执行SQL查询
- 可以连接传统的BI、可视化工具至数据集
- 前身Shark即为Hive on Spark,后出于维护、优化、 性能考虑放弃
Spark GraphX:图数据的并行处理模块
- 扩展RDD为Resilient Distributed Property Graph, 将属性赋予各个节点、边的有向图
- 可利用此模块对图数据进行ExploratoryAnalysis、Iterative Graph Computation
Spark MLLib:可扩展的机器学习模块
- 大数据平台使得在全量数据上进行学习成为可能
- 实现包括以下算法
- Classification
- Regression
- Clustering
- Collaborative Filtering
- Dimensionality Reduction
周围组件
BlinkDB:近似查询处理引擎
- 可以在大规模数据集上,交互式执行SQL查询
- 允许用户在查询精度、响应时间之间做出折中
- 用户可以指定查询响应时间、查询结果精度要求之一
- BlinkDB在Data Sample上执行查询,获得近似结果
- 查询结果会给Error Bar标签,帮助决策
Tachyon:基于内存的分布式文件系统
- 支持不同处理框架
- 可在不同计算框架之间实现可靠的文件共享
- 支持不同的上层查询处理框架,可以以极高的速度对集群 内存中的文件进行访问
- 将workset文件缓存在内存中,避免对磁盘的存取,如果数据集 不断被扫描、处理,数据处理速度将极大提升
- 支持不同处理框架
Spark实体
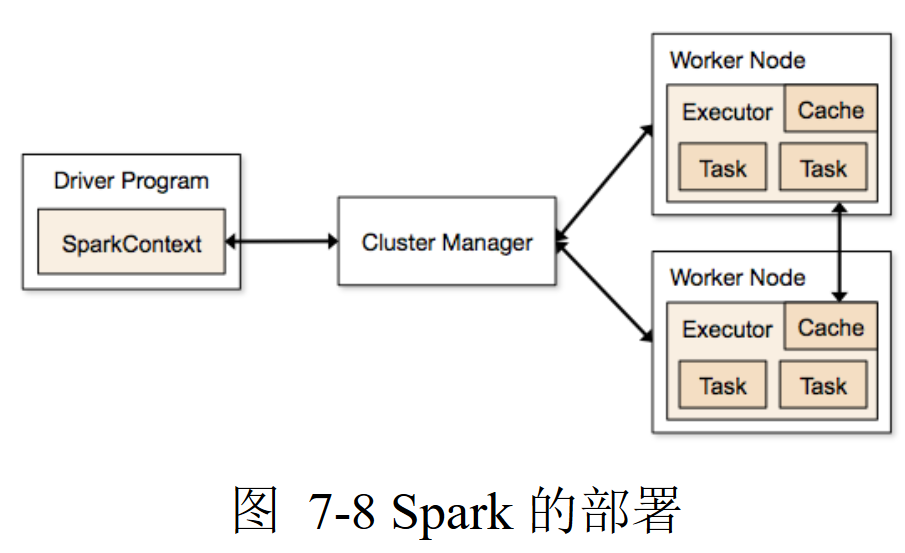
Spark Context:负责和CM的交互、协调应用
- 所有的Spark应用作为独立进程运行,由各自的SC协调
- SC向CM申请在集群中worker创建executor执行应用
Driver:执行应用主函数、创建Spark Context的节点
Worker:数据处理的节点
Cluster Manager:为每个driver中的应用分配资源
- 以下3种资源管理器,在sceduling、security、monitoring
有所不同,根据需要选择不同的CM
- Standalone
- Mesos
- YARN
- CM对Spark是agnostic
- 以下3种资源管理器,在sceduling、security、monitoring
有所不同,根据需要选择不同的CM
Spark Context
spark.SparkContext
1 | class SparkConf{ |
SparkContext是Spark应用执行环境封装,任何应用都需要、 也只能拥有一个活动实例,有些shell可能默认已经实例化
1 | import org.apache.spark.{SparkConf, SparkContext} |
Share Variable
共享变量:可以是一个值、也可以是一个数据集,Spark提供了两种 共享变量
Broadcast Variable
广播变量:缓存在各个节点上,而不随着计算任务调度的发送变量 拷贝,可以避免大量的数据移动
1 | val broadcastVal = sc.breadcast(Array(1,2,3)) |
Accumulator
收集变量/累加器:用于实现计数器、计算总和
集群上各个任务可以向变量执行增加操作,但是不能读取值, 只有Driver Program(客户程序)可以读取
累加符合结合律,所以集群对收集变量的累加没有顺序要求, 能够高效应用于并行环境
Spark原生支持数值类型累加器,可以自定义类型累加器
1 | // 创建数值类型累加器 |
数据源
1 | // 按行读取文本文件 |
slices:切片数目,缺省为每个文件块创建切片,不能设置 小于文件块数目的切片值
Spark基于文件的方法,原生支持
- 文件目录
- 压缩文件:
gz 简单通配符
|通配符|含义| |——-|——-| |
[]:范围| |[^]|范围补集| |?|单个字符| |*|0、多个字符| |{}|整体或选择|
Spark Session
SparkSession:Spark2.0中新入口,封装有SparkConf、
SparkContext、SQLContext、HiveContext等接口
1 | val warehouseLocation = "file:${system:user.dir}/spark-warehouse" |