Spark Streaming
Spark Streaming
Spark Streaming:提供对实时数据流高吞吐、高容错、可扩展的 流式处理系统
可以对多种数据源(Kafka、Flume、Twitter、ZeroMQ),进行 包括map、reduce、join等复杂操作
采用Micro Batch数据处理方式,实现更细粒度资源分配,实现 动态负载均衡
- 离散化数据流为为小的RDDs得到DStream交由Spark引擎处理
- 数据存储在内存实现数据流处理、批处理、交互式一体化
- 故障节点任务将均匀分散至集群中,实现更快的故障恢复
streaming.StreamingContext
1 | import org.apache.spark.streaming.StreamingContext |
1 | import org.apache.spark.{SparkContext, SparkConf} |
Discreted Stream
DStream:代表持续性的数据流,是Spark Streaming的基础抽象
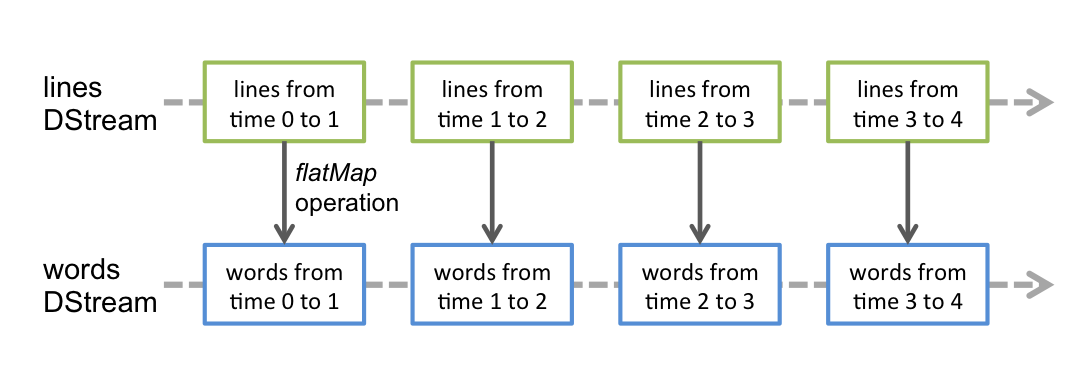
可从外部输入源、已有DStream转换得到
- 可在流应用中并行创建多个输入DStream接收多个数据流
在内部实现
- DStream由时间上连续的RDD表示,每个RDD包含特定时间 间隔内的数据流
- 对DStream中各种操作也是映射到内部RDD上分别进行
(部分如
transform等则以RDD为基本单元)- 转换操作仍然得到DStream
- 最终结果也是以批量方式生成的batch
- 对DStream操作参见tools/spark/spark_rdd
(大部分)输入流DStream和一个Receiver对象相关联
Recevier对象作为长期任务运行,会占用独立计算核, 若分配核数量不够,系统将只能接收数据而不能处理- reliable receiver:可靠的receiver正确应答可靠源, 数据收到、且被正确复制至Spark
- unreliable receiver:不可靠recevier不支持应答
Basic Sources
基本源:在StreamingContext中直接可用
- 套接字连接
- Akka中Actor
- RDD队列数据流
1 | // 套接字连接TCP源获取数据 |
文件系统
1 | // 文件流获取数据 |
文件系统:StreamingContext将监控目标目录,处理目录下任何
文件(不包括嵌套目录)
- 文件须具有相同数据格式
- 文件需要直接位于目标目录下
- 已处理文件追加数据不被处理
- 文件流无需运行
receiver
Advanced Sources
高级源:需要额外的依赖
- Flume
- Kinesis
Kafka
1 | // 创建多个Kafka输入流 |
性能调优
减少批数据处理时间
- 创建多个receiver接收输入流,提高数据接受并行水平
- 提高数据处理并行水平
- 减少输入数据序列化、RDD数据序列化成本
- 减少任务启动开支
设置正确的批容量,保证系统能正常、稳定处理数据
内存调优,调整内存使用、应用的垃圾回收行为
Checkpoint
1 | // 设置checkpoint存储信息目录 |
为保证流应用程序全天运行,需要checkpoint足够信息到容错 存储系统,使得系统能从程序逻辑无关错误中恢复
- metadata checkpointing:流计算的定义信息,用于恢复 worker节点故障
- configuration:streaming程序配置
- DStream operation:streaming程序操作集合
- imcomplete batches:操作队列中未完成批
- data checkpointing:中间生成的RDD,在有状态的转换 操作中必须,避免RDD依赖链无限增长
需要开启checkpoint场合
- 使用有状态转换操作:
updateStateByKey、reduceByKeyAndWindow等 - 从程序的driver故障中恢复
- 使用有状态转换操作:
1 | def functionToCreateContext(): StreamingContext = { |

