GGPlot 绘图
1 | p <- ggplot(data=mtcars, aes(x=wt, y=mpg)) |
color:点、线、填充区域着色fill:对填充区域着色,如:条形、密度区域alpha:颜色透明度,0~1逐渐不透明linetype:图案线条- 1:实线
- 2:虚线
- 3:点
- 4:点破折号
- 5:长破折号
- 6:双破折号
size:点尺寸、线宽度shape:点形状- 1:开放的方形
1 | p <- ggplot(data=mtcars, aes(x=wt, y=mpg)) |
color:点、线、填充区域着色fill:对填充区域着色,如:条形、密度区域alpha:颜色透明度,0~1逐渐不透明linetype:图案线条size:点尺寸、线宽度shape:点形状1 | png( |
parpar函数设置对整个工作空间图像设置均有效
1 | opar <- par() |
1 | par( |
1 | par( |
1 | par( |
1 | par( |
1 | par( |
titletitle函数可以为图形添加标题、坐标轴标签
1 | title( |
axis创建自定义坐标轴
1 | axis( |
minor.tick次要刻度线
1 | library(Hmisc) |
abline添加参考线
1 | abline( |
legend添加图例
1 | legend( |
mtext、textmtext:向图形四个边界之一添加文本text:向绘图区域内部添加文本1 | text( |
par1 | par( |
layout1 | layout( |
1 | barplot( |
1 | H <- c(7, 12, 28, 3, 41) |
1 | colors <- c("green", "orange", "brown") |
1 | pie( |
1 | x <- c(21, 62, 10, 53) |
1 | library(plotrix) |
1 | hist( |
1 | v <- c(9,13,21,8,36,22,12,41,31,33,19) |
#注释行,但是R没有
多行注释语法if(FALSE)语句进行“注释”1 | if(FALSE) { |
1 | getwd() |
1 | var.1 = c(0, 1, 2, 3) |
ls函数可以搜索当前工作空间中所有可用变量
1 | ls( |
rm函数可以删除变量
1 | rm(var.3) |
edit1 | mydata <- data.frame( |
read.table1 | DF <- read.table( |
说明:从带分隔符的文本文件中导入数据
参数
header:第一行是否包含变量名sep:分隔符,默认数个空格、tab、回车、换行row.names:指定行标记符col.names:指定DF对象列名na.strings:表示缺失值的字符串向量,其包含字符串
读取时转为NAcolClasses:设置DF对象每列数据模式quote:字符串划定界限,默认"'StringAsFactor:标记字符向量是否转换为factorcolClasses优先级更高text:读取、处理的字符串,而不是file1 | print() |
class函数就是返回数据模式(类型)只需要1byte存储
TRUE/TFALSE/F占用2-4byte
2L、0L可进一步分
float占用4bytedouble占用8byteR中数值型数据默认为double
12.3、4comlplex:3+2iR中'、"对中的任何值视为字符串
'、"必须在开头、结尾成对存在'、"结尾的字符串中,只能插入对方paste连接多个字符串
1 | Chars = paste( |
format将数字、字符串格式为特定样式
1 | Chars = format( |
nchar计算包括空格在内的字符串长度
1 | int = nchar( |
toupper、tolower改变字符串大小写
1 | chars = toupper( |
substring获取字符串子串
1 | chars = substring( |
print这样的泛型函数表明如何处理
此对象raw:v <- charToRaw("Hello")(byte类型)用于存储数值型、字符型、逻辑型数据的一维数组
1 | apple <- c("red", "green", "yellow") |
1 | rep(start: end, each=repeat_time) |
1 | a[1] |
二维数组:组织具有相同存储类型的一组变量
1 | mtx <- matrix( |
1 | dim(mtx) |
1 |
类似于矩阵,但是维度可以大于2
1 | arr <- array( |
数据帧是表、二维数组类似结构
1 | df <- data.frame( |
1 | str(emp.data) |
1 | emp.data.cols <- data.frame( |
rbind结合两个DF对象行
1 | city <- c("Tampa", "Seattle", "Hartford", "Denver") |
merge根据两DF列进行merge
1 | lirary(MASS) |
melt、cast1 | library(MASS) |
attach、detach1 | attach(emp.data) |
with1 | with(emp.data, { |
分类变量、有序变量在R中称为因子,其决定了数据的分析方式、 如何进行视觉呈现
1 | fctr <- factor( |
factor以整形向量的形式存储类别值1~k,k为定性(分类、有序)变量中
唯一值个数levels指定顺序一些对象、成分的有序集合
1 |
|
算术操作符作用与向量的每个元素
1 | v <- c(2, 5.5, 6) |
比较两个向量的相应元素,返回布尔值向量
1 | v <- c(2, 5.5, 6, 9) |
只适用于逻辑、数字、复杂类型向量,所有大于1的数字被认为是
逻辑值TRUE
1 | v <- c(3, 1, TRUE, 2+3i) |
1 | t <- 2: 8 |
1 | if |
1 | repeat |
1 | func_name <- function( |
1 | print(seq(32, 44)) |
1 | new.function_1 <- fucntion(){ |
1 | new.function <- function(a, b){ |
R语言包是R函数、编译代码、样本数据的集合
library的目录下1 | .libPaths() |
直接从CRAN安装
1 | install.package("pkg_name") |
手动安装包:从https://cran.r-project.org/web/packages/available_packages_by_name.html 中下载包,将zip文件保存
1 | install.package(/path/to/pkg.zip, repos=NULL, type="source") |
1 | library("pkg_name", |
算法:一系列解决问题的明确指令,即对于符合一定规范的 输入,能够在有限时间内获得要求的输出
确定算法:利用问题解析性质,产生确定的有限、无限序列使其收敛 于全局最优解
依某确定性策略搜索局部极小,试图跳跃已获得的局部极小而 达到某个全局最优点
能充分利用问题解析性质,从计算效率高
不确定算法,包括两个阶段,将判定问题的实例l作为其输入
- 猜测(非确定)阶段:生成任意串S作为l候选解
- 验证(确定)阶段:把l、S作为输入,,若S是l解输出是, 否则返回否或无法停止
当选仅当对问题每个真实例,不确定算法会在某次执行中 返回是时,称算法能求解此问题
即要求不确定算法对某个解至少能够猜中一次、验证正确性, 同时不应该将错误答案判定为是
Nondeterministic Polynominal Algorithm:验证阶段时间 效率是多项式级的不确定算法
几乎所有算法,对规模更大的输入需要运行更长时间,因此使用 输入规模作为参数很有价值
在有些情况下,选择不同的参数表示输入规模有差别
选择输入规模的度量单位还受到算法的操作细节影响
和数字特性相关的算法,倾向于使用$n$的二进制位数 $b=\lfloor {log_{2}^{n}} \rfloor + 1$
有些算法的运行时间不仅取决于输入规模,还取决于特定输入的细节
使用时间标准的度量算法程序运行时间缺陷
找到basic operation并计算其运行次数
时间估计
小规模输入运行时间差别不足以将高效算法与低效算法相区别, 对大规模输入忽略乘法常量,仅关注执行次数的order of growth 及其常数倍,即算法的渐进效率
按照算法渐进效率进行分类的方法缺乏使用价值,因为没有指定 乘法常量的值
但是对于实际类型输入,除了少数算法,乘法常量之间不会相差 悬殊,作为规律,即使是中等规模的输入,属于较优渐进 效率类型的算法也会比来自较差类型的算法效果好
对数函数:增长慢,以至于可以认为,对数级操作次数的算法能 瞬间完成任何实际规模输入
对于足够大的n,$t(n)$的上界由$g(n)$的常数倍确定,则 $t(n) \in O(g(n))$
即存在大于0的常数$c$、非负整数$n_{0}$,使得
增长次数小于等于$g(n) n \rightarrow \infty$ (及常数倍)的函数集合
对于足够大的n,$t(n)$的下界由$g(n)$的常数倍确定,则 $t(n) \in \Omega(g(n))$
即存在大于0的常数$c$、非负整数$n_{0}$,使得
增长次数大于等于$g(n) n \rightarrow \infty$ (及常数倍)的函数集合
对于足够大的n,$t(n)$的上、下界由$g(n)$的常数倍确定,则 $t(n) \in \Theta(g(n))$
即存在大于0的常数$c{1}, c{2}$、非负整数$n_{0}$,使得
增长次数等于$g(n) n \rightarrow \infty$(及常数倍) 的函数集合
利用极限比较增长次数:比直接利用定义判断算法的增长次数方便, 可以使用微积分技术计算极限
| 类型 | 名称 | 注释 |
|---|---|---|
| $1$ | 常量 | 很少,效率最高 |
| $log_{n}$ | 对数 | 算法的每次循环都会消去问题规模的常数因子,对数算法不可能关注输入的每个部分 |
| $n$ | 线性 | 能关注输入每个部分的算法至少是线性运行时间 |
| $nlog_{n}$ | 线性对数 | 许多分治算法都属于此类型 |
| $n^{2}$ | 平方 | 包含两重嵌套循环的典型效率 |
| $n^{3}$ | 立方 | 包含三重嵌套循环的典型效率 |
| $2^{n}$ | 指数 | 求n个元素的所有子集 |
| $n!$ | 阶乘 | n个元素集合的全排列 |
用一个方程把squence的generic term和一个或多个其他项相关联, 并提供第一个项或前几项的精确值
method of forward substituion:从序列初始项开始,使用 递推方程生成给面若干项,从中找出能用闭合公式表示的模式
method of backward subsitution:从序列末尾开始,把序列 通项$x(n)$表示为$x(n-i)$的函数,使得i是初始条件之一, 再求和公式得到递推式的解
second-order linear recurrence with constant coefficients :求解characteristic equation得到特征根得到通解
减一法:利用规模为n、n-1的给定实例之间的关系求解问题
减常因子法:把规模为n的实例化简为规模为n/b的实例求解问题
分治法:将给定实例划分为若干较小实例,对每个实例递归求解,如有必要, 再将较小实例的接合并为给定实例的一个解
eventually nondecreaing:$f(n)$在自然数上非负,若 $\exists n{0}, \forall n{2} > n{1} \geqslant n{0}, f(n{2}) > f(n{1})$, 则为最终非递减
smooth:$f(n)$在自然数上非负、最终非递减,若 $f(2n) \in \Theta(f(n))$,则平滑
$T(n)$最终非递减,$f(n)$平滑,若$n=b^{k}(b>2)$时有 $T(n) \in \Theta(f(n))$,则$T(n) \in \Theta(f(n))$
$T(n)$最终非递减,满足递推式
若$f(n) \in \Theta(n^{d}), d \geqslant 0$,则
确定已知、未知算法效率极限
算法下界是问题可能具有的最佳效率
可以用于评价某问题具体算法效率
寻找问题的更优算法时,可以根据算法下界确定期望获得的改进
平凡下界:任何算法只要要“读取”所有要处理的项、“写”全部 输出,对其计数即可得到平凡下界
往往过小,用处不大
确定问题中所有算法都必须要处理的输入也是个障碍
例
生成n个不同项所有排列的算法$\in \Omega(n!)$,且下界 是紧密的,因为好的排列算法在每个排列上时间为常数
计算n次多项式值算法至少必须要处理所有系数,否则改变 任意系数多项式值改变,任何算法$\in \Omega(n)$
计算两个n阶方阵乘积算法$\in Omega(n^2)$,因为任何 算法必须处理矩阵中$2n^2$个元素
信息论下界:试图通过算法必须处理的信息量(比特数)建立 效率下界
例
敌手下界:敌手基于恶意、一致的逻辑,迫使算法尽可能多执行, 从而确定的为了保证算法正确性的下界
- 恶意使得它不断把算法推向最消耗时间的路径
- 一致要求它必须和已经做出的选择保持一致(按照一定规则)
例
猜整数中,敌手把1~n个数字作为可选对象,每次做出判断 后,敌手保留数字较多集合,使得最消耗时间、不违背之前 选择
两个有序列表${a_i}, {b_j}$归并排序中,敌手使用规则: 当前仅当i < j时,对$a_i < b_j$返回真(设置列表值大小 可以达到),则任何算法必须比较2n-1次,否则交换未比较 元素归并错误
问题Q下界已知,考虑将问题Q转换为下界未知问题P,得到P下界
- 应该表明任意Q问题实例可以转换为P问题
- 即问题Q应该是问题P的子集,正确的算法至少应该能解决Q问题
许多问题复杂性不清楚,而对问题复杂度的直观判断和问题表现 形式相关,并不可靠
常在问题化简中使用的已知下界问题
|问题|下界|紧密性| |——-|——-|——-| |排序|$\Omega(nlogn)$|是| |有序数组查找|$\Omega(logn)$|是| |元素惟一性|$\Omega(nlogn)$|是| |n位整数乘法|$\Omega(n)$|未知| |n阶方程点乘|$\Omega(n^2)$|未知|
例
欧几里得最小生成树:使用元素唯一性问题作为下界已知 问题
任意矩阵A、B乘法:使用方阵乘法作为下界已知问题
将A、B化成对称方阵进行计算
乘积AB可以方便提取,而翻倍的矩阵乘法不会影响复杂性
可以使用(二叉)决策树研究基于比较的算法性能
每个非叶子节点代表一次键值比较
叶子节点个数大于等于输出,不同叶子节点可以产生相同输出
对于特定规模为n的输入,算法操作沿着决策树一条从根到叶子 节点完成,所以最坏情况下比较次数等于算法决策树高度
如果树具有由输出数量确定叶子,则树必须由足够高度容纳叶子 ,即对于任何具有$l$个叶子,树高度 $h \leqslant \lceil log_2 l \rceil$,这也就是 信息论下界
任意n个元素列表排序输出数量等于$n!$,所以任何基于比较的排序 算法的二叉树高度,即最坏情况下比较次数
归并排序、堆排序在最坏情况下大约必须要做$nlog_2n$次比较 ,所以其渐进效率最优
也说明渐进下界$\lceil log_2n! \rceil$是紧密的 ,不能继续改进
但这个只是基于二叉决策树的渐进下界,对于具体值估计 可能不准
如$\lceil log_2 12! \rceil = 29$,而事实证明 12个元素排序30次比较是必要、充分的
也可以使用决策树分析基于比较的排序算法的平均性能,即 决策树叶子节点平均深度
基于排序的所有输出都不特殊的标准假设,可以证明平均 比较次数下界$C_{avg}(n) \geqslant log_2n!$
这个平均是建立在所有输出都不特殊假设上,所以这个其实 应该是不同算法平均比较次数下界的上界
对于单独排序算法,平均效率会明显好于最差效率
有序线性表查找最主要算法是折半查找,其在最坏情况下下效率 $C{worst}^{bs} = \lfloor log_2n \rfloor + 1 = \lceil log(n+1) \rceil$
折半查找使用的三路比较(小于、等于、大于),可以使用 三叉查找树表示
三叉查找树会有2n+1个节点:n个查找成功节点、n+1个查找 失败节点
所以在最坏情况下,比较次数下界 $C_{worst}(n) \geqslant \lceil log_3{2n+1} \rceil$ 小于折半查找最坏情况下比较次数(渐进)
然而,事实上可以删除三叉查找树中间子树(等于分支),得到 一棵二叉树
非叶子节点同样表示三路比较,只是同时作为查找成功终点
可以得到一个新的下界 $C_{worst}(n) \geqslant \lceil log_2{n+1} \rceil$
更复杂的分析表明,标准查找假设下,折半查找平均情况比较 次数是最少的
如果算法的最差时间效率$\in O(p(n))$,$p(n)$为问题输入 规模n的多项式函数,则称算法能在多项式时间内对问题求解
Tractable:易解的,可以在多项式时间内求解的问题
Intractable:难解的,不能在多项式内求解的问题
使用多项式函数理由
无法保证在合理时间内对难解问题所有实例求解,除非问题实例 非常小
对实用类型的算法而言,其多项式次数很少大于3,虽然多项式 次数相差很大时运行时间也会有巨大差别
多项式函数具有方便的特性
多项式类型可以发展出Computational Complexity利用
判定问题:寻求一种可行的、机械的算法,能够对某类问题在有穷 步骤内确定是否具有某性质
Undecidable问题:不可判定问题,不能使用任何算法求解的 判定问题
Decidable问题:可判定问题,能用算法求解的问题
可判定、难解问题存在,但非常少
很多判定问题(或者可以转化为等价判定问题),既没有 找到多项式类型算法,也没有证明这样算法不存在,即无法 判断是否难解
Polynomial类型问题
非正式定义:易解的问题,即能够在多项式时间内求解的 问题(计算机范畴)
正式定义:能够用确定性算法在多项式时间内求解的 判定问题
多项式时间内求解:排除难解问题
判定问题:很多重要问题可以化简为更容易研究的判断问题 ,虽然原始表达形式不是判定问题
Nondeterministic Polynomial类型问题:可以用不确定多项式 算法求解的判定问题
NP问题虽然计算上对问题求解困难,但是在计算上判定待定结 是否解决问题是简单的:可以在多项式时间内完成
大多数判断问题都是属于NP类型的
$P \subseteq NP$:如果问题属于P,在不确定算法验证 阶段忽略猜测
还包括以下没有找到多项式算法、也没有证明算法不存在 的组合优化问题的判定版本
$P \overset ? = NP$:P和NP问题是否一致,计算机科学理论 中最重要的未解之谜
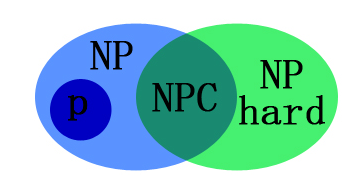
NP Complete问题
- 属于NP问题种,和该类型其他问题难度一致
- 证明问题属于NP问题比较简单
- NP中其他任何问题(已知或未知)可以在多项式时间内化简为 NPC问题
直接证明任何NP问题都可以在多项式时间内化简为当前问题 比较困难
常常利用多项式规约特性,证明某个确定NPC问题可以 多项式规约为当前问题
判定问题相互转换例
NPC问题案例
CNF-Satisfied Problem:合取范式可满足性问题,首个 被发现NPC问题
前面提到的著名NP问题都是NPC问题
仅仅得到一个NPC问题的多项式确定算法,所有NP问题可以 在多项式时间内求解
则$P = NP$
即对于所有类型判定问题而言,检验待定解、在多项式时间 内求解在复杂性商没有本质区别
而NPC问题可以被其他NP问题转换而来意味着,NPC问题目前不 存在对所有实例通用的多项式时间算法
NP-Hard问题:所有NP问题都可以通过多项式规约到其
不满足NPC问题第一个条件,可以不是NP问题
其范围包含NPC问题,前述组合优化问题最优版本也是NP-Hard
可以理解为:至少和NPC问题一样困难的问题
判定问题$D_1$可以多项式规约为判定问题$D_2$,条件是存在 函数t可以把$D_1$的实例转换为$D_2$的实例,满足
t把$D_1$所有真实例映射为$D_2$真实例,把$D_1$所有假实例 映射为$D_2$假实例
t可以用多项式算法计算
合取范式满足性问题:能否设置合取范式类型的布尔表达式中布尔 变量值,使得整个表达式值为真
1 | keras.layers.convolutional.Conv1D( |
一维卷积层(即时域卷积)
说明
input_shape参数
filters:卷积核的数目(即输出的维度)
kernel_size:整数或由单个整数构成的list/tuple,
卷积核的空域或时域窗长度
strides:整数或由单个整数构成的list/tuple,为卷积
步长
padding:补0策略
activation:激活函数
dilation_rate:整数或由单个整数构成的list/tuple,
指定dilated convolution中的膨胀比例
use_bias:布尔值,是否使用偏置项
kernel_initializer:权值初始化方法
bias_initializer:偏置初始化方法
kernel_regularizer:施加在权重上的正则项,为
Regularizer对象
bias_regularizer:施加在偏置向量上的正则项
activity_regularizer:施加在输出上的正则项
kernel_constraints:施加在权重上的约束项
bias_constraints:施加在偏置上的约束项
输入:形如(batch, steps, input_dim)的3D张量
输出:形如(batch, new_steps, filters)的3D张量
steps的值会改变1 | keras.layers.convolutional.Conv2D( |
二维卷积层,即对图像的空域卷积
说明
参数
filters:卷积核的数目(即输出的维度)
kernel_size:单个整数或由两个整数构成的list/tuple,
卷积核的宽度和长度
strides:单个整数或由两个整数构成的list/tuple,
卷积的步长
padding:补0策略
activation:激活函数
dilation_rate:单个或两个整数构成的list/tuple,
指定dilated convolution中的膨胀比例
输入:(batch, channels, rows, cols)
(”channels_first”)4D张量
输出:(batch, filters, new_rows, new_cols)
(”channels_first”)4D张量
1 | keras.layers.convolutional.SeparableConv2D( |
该层是在深度方向上的可分离卷积。
说明
参数
depth_multiplier:按深度卷积的步骤中,每个输入通道
使用(产生)多少个输出通道
depthwise_regularizer:按深度卷积的权重上的正则项
pointwise_regularizer:按点卷积的权重上的正则项
depthwise_constraint:按深度卷积权重上的约束项
pointwise_constraint:在按点卷积权重的约束项
输入:(batch, channels, rows, cols)4DT
(”channels_first”)
输出:(batch, filters, new_rows, new_cols)4DTK
(”channels_first”)
1 | keras.layers.convolutional.Conv2DTranspose( |
该层是反卷积操作(转置卷积)
说明
参数
output_padding:指定输出的长、宽paddingstride输入:(batch, rows, cols, channels)4DT
(”channels_last”)
输出:(batch, new_rows, new_cols, filters)4DT
(”channels_last”)
1 | keras.layers.convolutional.Conv3D( |
三维卷积对三维的输入(视频)进行滑动窗卷积
(batch, channels, conv_dim1, conv_dim2, conv_dim3)
5D张量(”channnels_first”)1 | keras.layers.convolutional.Cropping1D( |
在时间轴上对1D输入(即时间序列)进行裁剪
参数
cropping:指定在序列的首尾要裁剪掉多少个元素输入:(batch, axis_to_crop, features)的3DT
输出:(batch, cropped_axis, features)的3DT
1 | keras.layers.convolutional.Cropping2D( |
对2D输入(图像)进行裁剪
说明
参数
cropping:长为2的整数tuple,分别为宽和高方向上头部
与尾部需要裁剪掉的元素数输入:(batch, rows, cols, channels)4DT(”channels_last”)
输出:(batch, cropped_rows, cropped_cols, channels)
1 | # Crop the input 2D images or feature maps |
1 | keras.layers.convolutional.Cropping3D( |
对3D输入(空间、时空)进行裁剪
参数
cropping:长为3的整数tuple,分别为三个方向上头部
与尾部需要裁剪掉的元素数输入:(batch, depth, first_axis_to_crop, second_axis_to_crop, third_axis_to_crop)
(”channels_first”)
输出:(batch, depth, first_cropped_axis, second_cropped_axis, third_cropped_axis)
1 | keras.layers.convolutional.UpSampling1D( |
在时间轴上,将每个时间步重复size次
参数
size:轴上采样因子输入:(batch, steps, features)的3D张量
输出:(batch, upsampled_steps, feature)的3D张量
1 | keras.layers.convolutional.UpSampling2D( |
将数据的行和列分别重复size[0]和size[1]次
参数
size:分别为行和列上采样因子输入:(batch, channels, rows, cols)的4D张量
(”channels_first”)
输出:(batch, channels, upsampled_rows, upsampled_cols)
1 | keras.layers.convolutional.UpSampling3D( |
将数据的三个维度上分别重复size次
说明
参数
size:代表在三个维度上的上采样因子输入:(batch, dim1, dim2, dim3, channels)5DT
(”channels_last”)
输出:(batch, upsampled_dim1, upsampled_dim2, upsampled_dim3, channels)
1 | keras.layers.convolutional.ZeroPadding1D( |
对1D输入的首尾端(如时域序列)填充0
说明
参数
padding:整数,在axis 1起始和结束处填充0数目输入:(batch, axis_to_pad, features)3DT
输出:(batch, paded_axis, features)3DT
1 | keras.layers.convolutional.ZeroPadding2D( |
对2D输入(如图片)的边界填充0
说明
参数
padding:在要填充的轴的起始和结束处填充0的数目1 | keras.layers.convolutional.ZeroPadding3D( |
将数据的三个维度上填充0
结束处填充0的数目
1 | keras.layers.convolutional.ZeroPadding3D( |
将数据的三个维度上填充0
?时可用
所有的Keras层对象都有如下方法:
layer.get_weights():返回层的权重NDA
layer.set_weights(weights):从NDA中将权重加载到该层中
,要求NDA的形状与layer.get_weights()的形状相同
layer.get_config():返回当前层配置信息的字典,层也可以
借由配置信息重构
layer.from_config(config):根据config配置信息重构层
1 | layer = Dense(32) |
1 | from keras import layers |
如果层仅有一个计算节点(即该层不是共享层),则可以通过下列 方法获得
layer.inputlayer.outputlayer.input_shapelayer.output_shape如果该层有多个计算节点(参考层计算节点和共享层)
layer.get_input_at(node_index)layer.get_output_at(node_index)layer.get_input_shape_at(node_index)layer.get_output_shape_at(node_index)batch_size
None表示(batch_size,...)time_step
input_shape是Layer的初始化参数,所有Layer子类都具有
如果Layer是首层,需要传递该参数指明输入数据形状,否则 无需传递该参数
input_dim等参数具有input_shape
部分功能None:表示该维度变长
channels/depth/features:时间、空间单位上独立的数据, 卷积应该在每个channal分别“独立”进行
1D:(batch, dim, channels)(channels_last)
2D:(batch, dim_1, dim_2, channels)
(channels_last)
3D:(batch, dim_1, dim_2, dim_3, channels)
(channels_last)
1 | keras.layers.LeakyReLU(alpha=0.3) |
带泄漏的修正线性单元。
返回值:当神经元未激活时,它仍可以赋予其一个很小的梯度
x < 0:alpha * xx >= 0:x输入尺寸
input_shape参数(整数元组,不包含样本数量的维度)输出尺寸:与输入相同
参数
alpha:float >= 0,负斜率系数。参考文献
1 | keras.layers.PReLU( |
参数化的修正线性单元。
返回值
x < 0:alpha * xx >= 0:x参数
alpha_initializer: 权重的初始化函数。alpha_regularizer: 权重的正则化方法。alpha_constraint: 权重的约束。shared_axes: 激活函数共享可学习参数的轴。
如果输入特征图来自输出形状为
(batch, height, width, channels)
的2D卷积层,而且你希望跨空间共享参数,以便每个滤波
器只有一组参数,可设置shared_axes=[1, 2]参考文献
1 | keras.layers.ELU(alpha=1.0) |
指数线性单元
返回值
x < 0:alpha * (exp(x) - 1.)x >= 0:x参数
alpha:负因子的尺度。参考文献
1 | keras.layers.ThresholdedReLU(theta=1.0) |
带阈值的修正线性单元。
返回值
x > theta:xx <= theta:0参数
theta:float >= 0激活的阈值位。参考文献
1 | keras.layers.Softmax(axis=-1) |
Softmax激活函数
axis: 整数,应用 softmax 标准化的轴。1 | keras.layers.ReLU(max_value=None) |
ReLU激活函数
max_value:浮点数,最大的输出值。常用层对应于core模块,core内部定义了一系列常用的网络层,包括 全连接、激活层等
1 | keras.layers.core.Dense( |
Dense就是常用的全连接层
用途:实现运算$output = activation(dot(input, kernel)+bias)$
activation:是逐元素计算的激活函数kernel:是本层的权值矩阵bias:为偏置向量,只有当use_bias=True才会添加参数
units:大于0的整数,代表该层的输出维度。
activation:激活函数
use_bias: 布尔值,是否使用偏置项
kernel_initializer:权值初始化方法
bias_initializer:偏置向量初始化方法
kernel_regularizer:施加在权重上的正则项,为
Regularizer对象
bias_regularizer:施加在偏置向量上的正则项,为
Regularizer对象
activity_regularizer:施加在输出上的正则项,为
Regularizer对象
kernel_constraints:施加在权重上的约束项,为
Constraints对象
bias_constraints:施加在偏置上的约束项,为
Constraints对象
输入
(batch_size, ..., input_dim)的NDT,最常见情况
为(batch_size, input_dim)的2DTkernel相匹配的大小输出
(batch_size, ..., units)的NDT,最常见的情况为
$(batch_size, units)$的2DT1 | keras.layers.core.Activation( |
激活层对一个层的输出施加激活函数
参数
activation:将要使用的激活函数输入:任意,使用激活层作为第一层时,要指定input_shape
输出:与输入shape相同
1 | keras.layers.core.Dropout( |
为输入数据施加Dropout
说明
Dropout将在训练过程中每次更新参数时按一定概率rate
随机断开输入神经元
可以用于防止过拟合
参考文献:Dropout: A Simple Way to Prevent Neural Networks from Overfitting
参数
rate:0~1的浮点数,控制需要断开的神经元的比例
noise_shape:整数张量,为将要应用在输入上的二值
Dropout mask的shape
seed:整数,使用的随机数种子
输入
(batch_size, timesteps, features),希望在各个
时间步上Dropout mask都相同,则可传入
noise_shape=(batch_size, 1, features)1 | keras.layers.core.Flatten() |
Flatten层用来将输入“压平”,把多维的输入一维化
1 | model = Sequential() |
1 | keras.layers.core.Reshape( |
Reshape层用来将输入shape转换为特定的shape
参数
target_shape:目标shape,为整数的tuple,不包含样本
数目的维度(batch大小)-1表示推断该维度大小输入:输入的shape必须固定(和target_shape积相同)
输出:(batch_size, *target_shape)
例
1 | model = Sequential() |
1 | keras.layers.core.Permute( |
Permute层将输入的维度按照给定模式进行重排
说明
参数
dims:指定重排的模式,不包含样本数的维度(即下标
从1开始)输出shape
例
1 | model = Sequential() |
1 | keras.layers.core.RepeatVector( |
RepeatVector层将输入重复n次
参数
n:整数,重复的次数输入:形如(batch_size, features)的张量
输出:形如(bathc_size, n, features)的张量
例
1 | model = Sequential() |
1 | keras.layers.core.Lambda( |
对上一层的输出施以任何Theano/TensorFlow表达式
参数
function:要实现的函数,该函数仅接受一个变量,即
上一层的输出
output_shape:函数应该返回的值的shape,可以是一个
tuple,也可以是一个根据输入shape计算输出shape的函数
mask: 掩膜
arguments:可选,字典,用来记录向函数中传递的其他
关键字参数
输出:output_shape参数指定的输出shape,使用TF时可自动
推断
例
1 | model.add(Lambda(lambda x: x ** 2)) |
1 | # add a layer that returns the concatenation |
1 | keras.layers.core.ActivityRegularization( |
经过本层的数据不会有任何变化,但会基于其激活值更新损失函数值
l1:1范数正则因子(正浮点数)l2:2范数正则因子(正浮点数)1 | keras.layers.core.Masking(mask_value=0.0) |
使用给定的值对输入的序列信号进行“屏蔽”
说明
mask_value,则该时间步将在模型接下来的所有层
(只要支持masking)被跳过(屏蔽)。输入:形如(samples,timesteps,features)的张量
x[:,3,:] = 0., x[:,5,:] = 0.mask_value=0.的Masking层1 | model = Sequential() |
.`的Masking层
1
2
3model = Sequential()
model.add(Masking(mask_value=0., input_shape=(timesteps, features)))
model.add(LSTM(32))
```
LocallyConnnected和Conv差不多,只是Conv每层共享卷积核, 这里不同位置卷积核独立
1 | keras.layers.local.LocallyConnected1D( |
类似于Conv1D,单卷积核权重不共享
1 | keras.layers.local.LocallyConnected2D( |
类似Conv2D,区别是不进行权值共享
1 | model = Sequential() |