C++ 程序结构
- C++ 是面向对象和过程的范式的集合
Comment
注释:被编译器忽略的文本
/**/:允许多行注释//:单行注释
Library
库:提前编写的能执行有用操作工具集合
库引入
#include <>:头文件是C++标准中的系统库#include ".h":其他库、自行编写的头文件
Namespace
命名空间:被切分为代码段的结构,为确保定义在大系统中各部分 程序的元素名称(如:变量名、函数名等)不会相互混淆
std:C++标准库的命名空间
- 需要告诉编译器定义所属的命名空间才能引用头文件中的名称
函数
为方便理解,大多数程序被划分为几个较小的易于理解的函数
- Prototype:函数原型,函数定义的首行加上分号结尾组成
- 主程序:每个C++程序必须有
main函数,指明程序计算 的开始点,main函数结束时,程序执行也随之结束
Variable
变量:一个命名的、能够存储特定类型值的一块内存区域
在变量生存期内,所有变量的名字、类型都是不改变的, 而变量的值一般会随着程序运行发生改变
可以将变量视为盒子
- 变量名:作为和盒子的标签在盒子外
- 变量值:在盒子里物品
C++/C中变量的解释是由变量类型而不是值决定, 存储值一样,可能会有不同的处理方式
- 引用、指针都存储地址,但是引用可以直接作为变量使用, 指针则需要解引用
- initializer:初始化,初始值作为声明的一部分
- 变量类型、修饰符参见cs_cppc/basics/mem_ctl
Scope
变量作用域
Local Variable
局部变量:声明在函数体内,作用域可以扩展到其 声明所在块
- 函数被调用时:为每个局部变量分配在整个函数调用时期 的存储空间
- 函数返回时:所有局部变量消亡
- 局部变量一般存储在函数栈中
Global Variable
全局变量:声明在函数定义外,作用域为其声明所在文件
- 生命期为程序运行的整个运行期,可用于存储函数调用的值
- 可以被程序中任意函数操作,难以避免函数间相互干扰
- 除声明全局常量外,不采用全局变量易于管理程序
- 全局变量一般存储在静态区中
Declare
声明:主要功能是将变量的名字和变量包含值类型相关联
- 在使用变量之前必须声明
- 变量声明在程序中的位置决定了变量的scope
- 事实上,函数、类等都可以提前声明,有些时候必须如此,以 使用forward reference(前向引用,定义之前声明指向其的 指针)
Identifier
标识符:变量、函数、类型、常量等名字的统称
- 必须以字母、
_开始 - 所有字符必须是字母、数字、
_,不允许空格或其他特殊字符 - 不能包含保留字
- 标识符中大小写字母是不同的
- 标识符可以取任意长度,但是C++编译器不会考虑任何超过31个 字符的两个名字是否相同
Shadowing
遮蔽:程序代码内层块中变量隐藏外层块中同名变量的行为
隐式类型转换
数值类型转换
提升型转换:通常不会造成数值差异
- 小整数
char、short转换到int float转换到double
- 小整数
可能存在转换误差的转换
- 负数转换为无符号类型:二进制位不变,即为负数对应补码 正数
- 其他类型转换为bool类型
- 浮点数转换为整数:截断,若出现数值溢出,则出现未定义 行为
指针类型转换
- 空指针
void *、任意指针类型类型之间相互转换 - 衍生类指针转换为基类指针,同时不改变
const、volatile属性 - C风格数组隐式把数组转换为指向第一个元素的指针
- 容易出现错误
1
2
3char * s = "Help" + 3;
# ”Help"被转换为指向数组指针,向后移3位
# `s`指向最后元素`p`
- 容易出现错误
强制类型转换
- 上行转换:派生类指针、引用转换为基类表示
- 下行转换:基类指针、引用转化为派生类表示
const_cast
const_cast:去掉原有类型的const、volatile属性,将常量
指针、引用转换为非常量
- 常量指针转化为非常量指针,仍来指向原来对象
- 常量引用转换为非常量引用,仍然指向原来对象
- 一般用于修改指针,如
const char *p- 要求期望去常量目标非常量,否则为未定义行为
1 | int ary[4] = {1, 2, 3, 4}; |
未定义行例
堆区常量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int con_cast(){
const int * c_val_ptr = new const int(1);
// 常量值,非常量指针
int vec_before[*c_val_ptr];
// 常量声明数组
int & ptr_val = const_cast<int &>(*c_val_ptr);
ptr_val += 1;
// 可以正常给值加1
// 未定义行为?堆区不存在常量?
int vec_after[*c_val_ptr];
// 常量生命数组
cout << sizeof(vec_before) << endl <<
sizeof(vec_after) << after;
// 二者长度均为`8`,即常量在`vec_before`创建前已处理
cout << *c_val_ptr << endl << ptr_val << endl
<< c_val_ptr << endl << &ptr_val;
// 地址、值均相同
}栈区常量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int con_cast(){
const int c_val= 1;
// 常量值
int vec_before[c_val];
// 常量声明数组
int & ptr_val = const_cast<int &>(&c_val);
ptr_val += 1;
// 可以正常给值加1
int vec_after[c_val];
// 常量生命数组
cout << sizeof(vec_before) << endl <<
sizeof(vec_after) << after;
// 二者长度均为`4`,即常量值已处理,但没有改变
cout << c_val << endl << ptr_val << endl
<< &c_val<< endl << &ptr_val;
// 地址保持相同、但二者值不同
}
- 以上代码在g++4.8.5中测试
static_cast
static_cast:静态类型转换,无条件转换
类层次中基类、派生类之间指针、引用转换
- 上行转换:派生类完全包含基类所有成员,安全
- 下行转换:派生类包含独有成员,没有动态类型检查,对象 为派生类实例时转换不安全
- 基类、派生类之间转换建议使用
dynamic_cast
基本类型转换:安全性需要开发者维护
int、char、enum、float之间相互转换- 空指针转换为目标类型指针:不安全
- 任何类型表达式转换为
void类型
- 不能进行无关类型指针(无继承关系、float与int等)之间 转换,而C风格强转可以
- 不能转换掉原有类型的
const、volatile、__unaligned属性- 静态是相对于动态而言,只在编译时检查,编译时已经确定转换 方式,没有运行时类型检查保证转换安全性
1 | float f_pi = 3.141592f |
- 和C风格强转效果基本一致(使用范围较小),同样没有运行时 类型检查保证转换安全性,有安全隐患
- C++中所有隐式转换都是使用
static_cast实现
dynamic_cast
dynamic_cast:指针、引用动态类型转换,有条件转换
安全的基类、派生类之间转换
- 转型对象为指针:转型失败返回
NULL - 转型对象为引用:转型失败抛出异常
- 转型对象为指针:转型失败返回
动用runtime type information进行类型安全检查,会有效率 损失
- 依赖虚函数表将基类指针转换为子类指针???
- 检查对象实例类型,保证转换是安全的,不会出现 子类指针指向父类对象
1 | class Base{ |
- 涉及面向对象的多态性、程序运行时的状态,主要是用于虚类 类型上行转换
- 同编译器的属性设置有关,所以不能完全使用C语言的强制转换 替代,常用、不可缺少
reinterpret_cast
reinterpret_cast:仅仅是重新解释给出对象的比特模型
,没有对值进行二进制转换
- 用于任意指针、引用之间的转换
- 指针、足够大的整数(无符号)之间的转换
1 | int * ptr = new int(233); |
- 处理无关类型转换,通常为位运算提供较低层次重新解释
- 难以保证移植性
C风格
1 | Typename b = (Typename) a; |
- 没有运行时类型检查保证转换安全性,可能有安全隐患
Data Type
数据类型:从形式上看,数据类型有两个属性定义
- domain:值集,该类型值的集合
- set of operation:操作集,定义类型的行为
- C++每个数据值都有其相应数据类型
- Primitive Type:基本类型,类型系统整体的建筑块
- 整型
- 浮点型
- 布尔型
- 字符
- 枚举类型
Integer
C++定义了3种整数类型:short、int、long
- 由值域大小相互区别
值域
C++中没有指定3种类型确切值域,其取决于机器、编译器,但是 设计者可以更确切的定义各整形值域
short、int、long类型内存不减int类型最大值至少$2^{15}-1$long类型最大值至少$2^{31}-1$
一般的
short:2bytesint:4byteslong/long long:8bytes
- 若希望明确值域,尝试
<cstdint>中自定义类型
unsigned
各整形均可以在其类型之前加上关键字
unsigned,构建新的 非负整形无符号整型可以提供有符号整型两倍正值域
16进制、8进制等都是无符号输出格式,有符号整形会被 隐式转换位无符号(若传入)
表示
- 整形常量一般写成十进制数字
- 数字以
0开始:编译器将其视为八进制数字 - 数字以
0x开始:编译器将其视为16进制数字 - 数字
L结尾:显式指明整数常量的类型为long(表达式中) - 数字
U结尾:整形常数被认为时无符号整数(表达式中)
Float-Point
C++中定义了3种浮点类型:float、double、long double
值域
C++同样没由指定这些类型的确切表示
float、double、long double占用内存不减、精度 不减
表示
- 通常使用带有小数点的十进制数字
- 支持科学计数法风格:浮点数乘以十的整数幂
Bool
布尔类型:具有合法常量值true、false的数据类型
Char
C++中表示字符的预定义基本类型:char
- C++标准库定义
wchar_t类型表示宽字符以扩展ASCII编码范围
值域
出现在屏幕、键盘上的字母、数字、空格、标点、回车等字符集合
- 在机器内部,这些字符被表示成计算机赋给每个字符的数字代码
- 多数C++实现中,表示字符的代码系统为ASCII
表示
'':单引号括起的一个字符表示字符常量escape sequence:转移序列,以\开始的多个字符表示 特殊字符
对比整形
整形没有1byte大小类型,很多情况下使用
char类型存储 整数值以节省空间但C/C++某些
[unsigned ]char、整形处理有区别
输入、输出
对
[unsigned ]char类型总是输出字符,而不是数字串- 输出流:关于整形的流操纵符对
[unsigned ]char无效, 即使是无符号类型 - 格式化输出:指定输出格式得到数字串,包含隐式类型转换
- 输出流:关于整形的流操纵符对
String
字符串:字符序列
- C风格的字符串就是以
\0结尾的字符数组
\0:null character,空字符,对应ASCII码为0
表示
"":双引号括起的字符序列表示字符串常量- 允许使用转移序列表示字符串中特殊字符
- 两个、两个以上字符串连续出现在程序中,编译器会自动将其 连接(即可以将字符串分行书写)
Enumerated
枚举类型:通过列举值域中元素定义的新的数据类型
1 | enum typename { namelist }; |
值域
- 默认的,编译器按照常量名顺序,从0开始给每个常量赋值
- 允许给每个枚举类型常量显式的赋值
- 若只给部分常量名赋值,则编译器自动给未赋值常量赋最后一个 常量值后继整数值
复合类型
基于已存在的类型创建的新类型
表达式
C++中表达式由项、操作符构成
- term:项,代表单个数据的值,必须是常量、变量、函数调用
- operator:操作符,代表计算操作的字符(短字符序列)
- binary operator:二元操作符,要求两个操作数
- unary operator:一元操作符,要求一个操作数
- full expression:完整表达式,不是其他表达式子表达式 的表达式
表达式求值顺序
C++没有规定表达式求值顺序(表达式求值顺序是指CPU计算 表达式的顺序,不同于优先级、结合律)
- sequenced before:若A按顺序先于B,A中任何计算都 先于B中任何计算
- sequenced after:若A按顺序后于B,A中任何计算都晚于 B中任何计算
- unsequenced:若A与B无顺序,则A、B中计算发生顺序 不确定,并且可能交叉
- indeterminately sequenced:若A与B顺序不确定,则 A、B计算发生顺序不确定,但不能交叉
- 对无顺序、顺序不确定求值,不要求两次不同求值使用相同顺序
完整表达式的求值、副作用先于下个完整表达式的求值、 副作用
表达式中不同子表达式的求值无顺序
- 除非特殊说明,运算符的不同操作数求值是无顺序的
- 运算操作数值计算先于运算符结果值计算
对同一简单对象
- 两个不同副作用无顺序,则为无定义行为
- 副作用与需要此对象值的计算无顺序,则为无定义行为
1
2
3int i = 0;
i++ + i++; // 两`i++`对i`均副作用、无顺序,未定义行为
i + i++; // `i++`副作用、`+`计算无顺序,未定义行为函数调用时:不仅限于显示函数调用,包括运算符重载、构造、 析构、类型转换函数
实参求值、副作用先于函数体任何语句、表达式求值
函数不同实参求值、副作用无顺序
1
2
3int func(int, int);
int i = 0;
func(i++, i++); // 参数计算`i++`对`i`均有副作用,无定义行为主调函数中任何既不先于、也不后于被调函数的求值,其 与被调用函数都是顺序未指定,即主调函数中任何求值 与被掉函数不交叉
1
2
3
4int foo(int);
int i = 0, j = 0, k = 0;
(i++ + k) + foo(j++);
(i++ + k) + foo(i++);不同形参初始化是顺序未指定
自增、自减
- 后缀形式:
i++、i--- 值计算先于对变量的修改
- 与其顺序未指定函数调用不能插入值计算、变量修改 之间
- 前缀形式:
++i、--i- 返回被更新之后的操作数(左值)
i非布尔值时,++i、--i等价于i+=1、i-=1
- 后缀形式:
new- 内存分配函数与初始化参数求值顺序未指定
- 新建对象初始化先于
new表达式计算
逻辑与
&&、或||为短路求值- 左操作数计算先于右操作数计算
- 左操作数为
false、true时,右操作数不会被求值
?:中三个操作数只有两个会被求值- 第一个操作数求值先于后两个操作数求值
- 第一个操作数值为
true时,第二个操作数被求值,否则 第三个操作数被求值
赋值运算符
=- 左、右操作数求值先于赋值操作
- 赋值操作先于赋值表达式值计算
- 赋值表达式返回其左操作数的左值,此时左操作数必然被 赋值
复合赋值运算符
e1 op= e2:+=、-=等- 求值包括
e1 op e2、结果赋给e1、返回e1 - 任何函数调用不能插入以上步骤
- 求值包括
逗号
,运算符(注意区分逗号分隔符)- 左操作数值被丢弃
- 左操作数值计算、副作用先于右操作数值计算、副作用
- 被重载后的逗号运算符将生成函数调用,对操作数求值遵循 函数实参求值顺序
序列初始化:对
{}存在的多个初始化参数求值- 初始化参数值计算、副作用先于被逗号分隔的后初始化值 计算、副作用
- 即使初始化参数引起函数调用,列表每个值作为函数参数, 求值顺序仍然被保留
优先级、结合律
precedence:优先级,默认情况下(无括号)操作符在运算中 结合的方法
associativity:结合律,相同优先级的运算符运算顺序, 也即左右操作数的运算顺序
- left-associative:左结合的,优先计算操作符左侧 表达式,大部分操作符时左结合的
- right-assiciative:右结合的
| 优先级递减 | 结合性 | ||
|---|---|---|---|
()、[]、->、. |
左 | ||
一元操作符:-、+、--、++、!、&、*、~、(类型)、sizeof |
右 | ||
*、/、% |
左 | ||
+、- |
左 | ||
>>、<<(右、左移位) |
左 | ||
<、<=、>、>= |
左 | ||
==、!= |
左 | ||
& |
左 | ||
^ |
左 | ||
| ` | ` | 左 | |
&& |
左 | ||
| ` | ` | 左 | |
?: |
右 | ||
=、op= |
右 |
- 操作符只是语言的语法,其行为只是人为赋予的规则,其行为 可能符合逻辑,也可能不符合逻辑
混合类型
对于具有不同操作数的操作符,编译器会将操作数转化为其中精度 最高的类型,计算结果也为精度最高的类型,保证计算结果尽可能 精确
整数除法、求余
- 两个整数除法运算:结果为整数,余数(小数)被舍去
- 含负数操作数的除法、求余:依赖硬件特征
- 求余一般返回同余正值
Type Cast
(值/静态)类型转换:将一种类型明确的转换为另一种类型
1 | type(expr) |
转换目标类型精度增加不丢失信息,否则可能会丢失信息
符号整形转换无符号整形:依赖硬件特征,一般
- 符号位置于最高位
- 数值位根据精度
- 同精度:不变,即包括符号位在内无改变
- 低精度向高精度:高位用符号位补齐
- 高精度向低精度:截断、保留低位
无符号整形转符号整形
- 同精度、高精度向低精度:截断、保留低位
- 低精度向高精度:高位补0
- 即:有符号转为其他类型(有符号、无符号),优先保留符号位
赋值操作
C++中,对变量的赋值是一种内置的表达式结构
赋值操作符
=要求其左操作数必须是可变的,通常是变量名首先计算赋值操作符右边表达式值,再赋给左边的变量
- 右操作数可能需要进行类型转换以使其与左操作数的类型 相匹配
赋值操作默认(未重载)是通过将源对象所有变量域(栈中 数据),复制到目标对象相应变量域实现的
返回值
C++赋值表达式返回右边表达式的值
- 可以被组合进更大表达式中(但会影响阅读)
- multiple assignment:多重赋值,可以方便给多个变量赋 相同值
Shorthand Assignment
将赋值操作符、二元操作符相结合产生形式
1 | var op= expr; |
自增、自减
对变量进行+1、-1的更高级别的缩写形式
1 | x++; |
布尔运算
Relational Operator
关系操作符
==:等于,容易犯错!=:不等于>:大于<:小于>=:大于等于<=:小于等于
Logical Operator
逻辑操作符:采用布尔类型操作数,组合形成新的布尔值
!:逻辑非&&:逻辑与||:逻辑或
Short-Circuit Evaluation
短路求值:得到结果时就立刻结束计算表达式
- 依赖于:3种逻辑操作符优先级均不同,逻辑运算表达式总是 从左到右计算的
?:
三目操作符,需要3个操作数
1 | (condition) ? expr_1 : expr_2 |
Bitwise Operator
位运算符:读取任意标量类型值,将其翻译成与底层硬件相应的 比特序列表示
&、|、^:位逻辑与、或、异或~:位逻辑非>>、<<:右、左移位- 无符号数:字尾被移动比特数消失,另一端补0
- 有符号数:行为依赖于硬件特征,一般保证乘除特性
- 右移:补1
- 左移:补0
语句
simple statement:简单语句,执行某些动作
- 表达式加分号组成
control statement:控制语句,控制程序流程
- 控制语句典型地应用在一条单一语句中
Block
块:{}括起指明一组语句序列是连贯单元的一部分
- 编译器会将整个块当作一条语句对待,也被称为 compound statement
- 常用于使用特定控制语句控制一组语句
Conditional Execution
条件执行:根据检测条件控制程序后续执行
if
1 | if (condition) statement |
if中控制语句可以是一条简单语句,也可以是一个语句块
switch
1 | switch (e){ |
程序计算控制表达式
e的值,将结果同c1、c2相比较case后的常量必须是标量类型,即底层采用整数表示 的类型,如:整形、字符、枚举类型
如果常量同控制表达式值相匹配,则跳转至相应
case子句执行- 执行到子句中
break时跳出switch语句 - 若子句中无
break,则接着执行之后case子句中语句, 直到遇到break/return跳出switch语句,这会带来很多 问题,除1
2
3
4case 1:
case 2:
statement
break;
- 执行到子句中
default可选,执行没有和控制表达式匹配值的操作- 除非确定列举了所有可能情况,否则增加
default子句是 好习惯
- 除非确定列举了所有可能情况,否则增加
Iterative Statement
迭代语句:以循环的方式多次执行程序中的一部分
while
一般模式
1 | while (condition-expression){ |
- 首先查看条件表达式值
- 若条件表达式值为
true,整个循环体被执行,然后返回到循环 开始检查条件表达式值 - 若条件表达式值为
false,则循环终止
- 每个循环周期,包括第一次循环,条件表达式都会被测试,且 仅在循环开始进行,循环中间条件表达式值改变不会被注意
Read-util-Sentinel Pattern
读直到信号量模式:使用break语句在循环中结束最内层循环
1 | while(true){ |
for
以特定的循环次数重复执行某个操作
基于条件的循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 一般模式
for (init; test; step){
statements
}
init;
while(test){
statements
step;
}
// 二者等价
// 常用模式
for(int var=start; var <= finish; var++){
// `var`:*index variable*
statement
}
// 循环`finish - start`次range-based for loop:基于范围的循环,C++11开始支持
1
2
3
4
5
6
7
8
9
10
11
12
13for(type var: collection){
statements
}
// `foreach.h`接口中的定义宏,提供类似功能
foreach(type var in collection){
}
// C++编译器通过迭代器,将基于范围的循环转换为传统循环
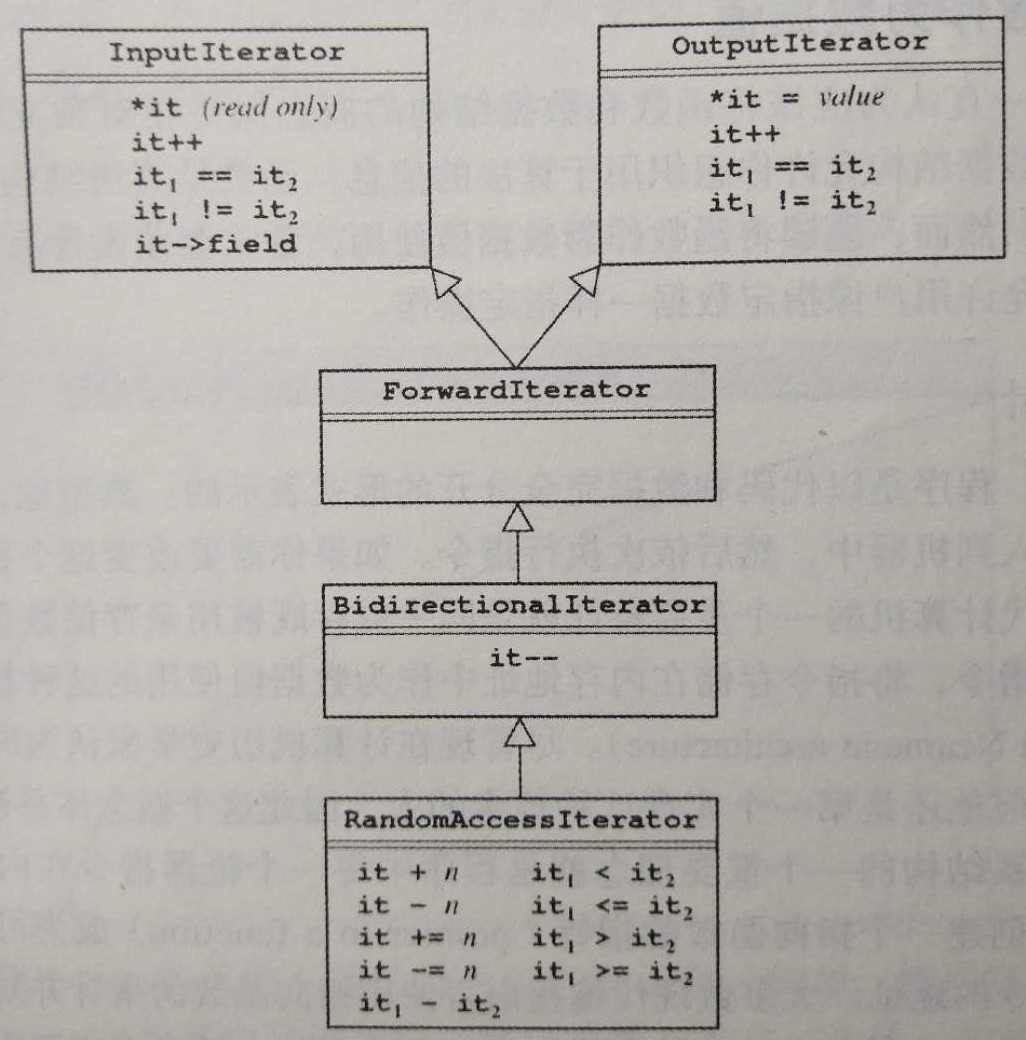
for(ctype::iterator it = collection.begin());
it != collection.end(); it++){
// `ctype`:集合类型
}
编译、汇编、执行
步骤
Preprocess
预处理:生成.i预处理文件
- 宏替换
- 注释的消除
- 寻找相关头文件/接口:除默认搜索路径,还可以通过环境变量
设置C_INCLUDE_PATH;C头文件搜索路径CPLUS_INCLUDE_PATH:C++头文件搜索路径CPATH:C/C++头文件搜索路径
1 | g++ -E src.cpp > src.i |
Compile
编译:将预处理后的文件编译为汇编语言,生成汇编文件.s
- 编译单位为文件
1 | g++ -S src.i -o src.s |
Assemble
汇编:生成目标机器代码,二进制.o中间目标文件
.o通常仅解析了文件内部变量、函数,对于引用变量函数 还未解析,需要将其他目标文件引入
1 | g++ -C src.s -o src.o |
- Windows下生成
.obj文件
Link
链接:链接目标代码,生成可执行程序
- gcc通过调用
ld进行链接 - 主要是链接函数、全局变量
- 链接器关注/链接二进制
.o中间目标文件 Library File:若源文件太多,编译生成的中间目标文件 过多,把中间目标文件打包得到.lib/.a文件
1 | g++ src.o -o a.out |
执行
序列点
- 对C/C++表达式,执行表达式有两个类型动作
- 计算某个值
- 产生副作用:访问
volatile对象、原子同步、修改文件