常用定理
Lucas 定理
- $p < 10^5$:必须为素数
Holder 定理
$|x|^{*}_p = |x|_q$
- $\frac 1 p + \frac 1 q = 1$
RBF 径向基函数:取值仅依赖到原点距离的实值函数,即 $\phi(x) = \phi(|x|)$
径向基函数最初用于解决多变量插值问题
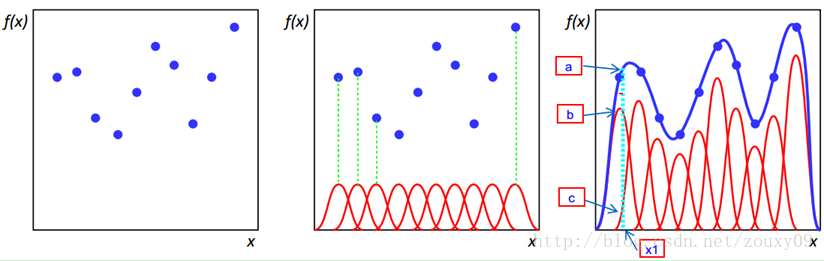
- 定义 $r=|x-x_i|$
高斯函数
Multiquadric 多二次函数:
Inverse Quadric 逆二次函数:
Polyharmonic Spline 多重调和样条:
Thin Plate Spline 薄板样条(多重调和样条特例):
- $Phi(x)$:凸函数
布雷格曼散度:穷尽所有关于“正常距离”的定义
特点
| Domain | $\Phi(x)$ | $D_{\Phi}(x,y)$ | Divergence | ||||
|---|---|---|---|---|---|---|---|
| $R$ | $x^2$ | $(x-y)^2$ | Squared Loss | ||||
| $R_{+}$ | $xlogx$ | $xlog(\frac x y) - (x-y)$ | |||||
| $[0,1]$ | $xlogx + (1-x)log(1-x)$ | $xlog(\frac x y) + (1-x)log(\frac {1-x} {1-y})$ | Logistic Loss | ||||
| $R_{++}$ | $-logx$ | $\frac x y - log(\frac x y) - 1$ | Itakura-Saito Distance | ||||
| $R$ | $e^x$ | $e^x - e^y - (x-y)e^y$ | |||||
| $R^d$ | $\ | x\ | $ | $\ | x-y\ | $ | Squared Euclidean Distance |
| $R^d$ | $x^TAx$ | $(x-y)^T A (x-y)$ | Mahalanobis Distance | ||||
| d-Simplex | $\sum_{j=1}^d x_j log_2 x_j$ | $\sum_{j=1}^d x_j log_2 log(\frac {x_j} {y_j})$ | KL-divergence | ||||
| $R_{+}^d$ | $\sum_{j=1}^d x_j log x_j$ | $\sum{j=1}^d x_j log(\frac {x_j} {y_j}) - \sum{j=1}^d (x_j - y_j)$ | Genelized I-divergence |
- 正常距离:对满足任意概率分布的点,点平均值点(期望点)应该是空间中距离所有点平均距离最小的点
- 布雷格曼散度对一般概率分布均成立,而其本身限定由凸函数生成
- 和 Jensen 不等式有关?凸函数隐含部分对期望的度量
- http://www.jmlr.org/papers/volume6/banerjee05b/banerjee05b.pdf
闵科夫斯基距离:向量空间 $\mathcal{L_p}$ 范数
表示一组距离族
闵氏距离缺陷
马氏距离:表示数据的协方差距离
- $\Sigma$:总体协方差矩阵
兰氏距离:Lance and Williams Distance,堪培拉距离
汉明距离:差别
- $v_i \in {0, 1}$:虚拟变量
- $p$:虚拟变量数量
- 以上汉明距离空间嵌入对曼哈顿距离是保距的
Jaccard 系数:度量两个集合的相似度,值越大相似度越高
- $S_1, S_2$:待度量相似度的两个集合
余弦相似度
- $x_1, x_2$:向量
- $T={(x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n)}$:样本点集
- $wx + b = 0$:超平面
函数间隔可以表示分类的正确性、确信度
点集与超平面的函数间隔取点间隔最小值 $\hat{T} = \min_{i=1,2,\cdots,n} \hat{\gamma_i}$
超平面参数 $w, b$ 成比例改变时,平面未变化,但是函数间隔成比例变化
几何间隔一般是样本点到超平面的 signed distance
几何间隔相当于使用 $|w|$ 对函数间隔作规范化
点集与超平面的几何间隔取点间隔最小值 $\hat{T} = \min_{i=1,2,\cdots,n} \hat{\gamma_i}$
(字符串)编辑距离:两个字符串转换需要进行插入、删除、替换操作的次数
- hash:散列/哈希,将任意类型值转换为关键码值
- hash function:哈希/散列函数,从任何数据中创建小的数字“指纹”的方法
- hash value:哈希值,哈希函数产生关键码值
- collision:冲突,不同两个数据得到相同哈希值
Data Independent Hashing:数据无关哈希,无监督,哈希函数基于某种概率理论
Data Dependent Hashing:数据依赖哈希,有监督,通过学习数据集的分布从而给出较好划分的哈希函数
简单哈希函数主要用于提升查找效率(构建哈希表)
复杂哈希函数主要用于信息提取
直接寻址法:取关键字、或其某个线性函数值 $hash(key) = (a * key + b) \% prime$
数字分析法:寻找、利用数据规律构造冲突几率较小者
平方取中法:取关键字平方后中间几位
折叠法:将关键字分割为位数相同部分,取其叠加和
随机数法:以关键字作为随机数种子生成随机值
- 常用于之前哈希结果再次映射为更小范围的最终哈希值
加法哈希:将输入元素相加得到哈希值
标准加法哈希
1 | AddingHash(input): |
位运算哈希:利用位运算(移位、异或等)充分混合输入元素
标准旋转哈希
1 | RotationHash(input): |
变形 1
1 | hash = (hash<< 5) ^ (hash >> 27) ^ ele |
变形2
1 | hash += ele |
变形3
1 | if (ele & 1) == 0: |
变形4
1 | hash += (hash << 5) + ele |
变形5
1 | hash = ele + (hash << 6) + (hash >> 16) - hash |
变形6
1 | hash ^= (hash << 5) + ele + (hash >> 2) |
乘法哈希:利用乘法的不相关性
平方取头尾随机数生成法:效果不好
Bernstein 算法
1 | Bernstein(input): |
- 其他常用乘数:31、131、1313、13131、131313
32位 FNV 算法
1 | M_SHIFT = |
改进的 FNV 算法
1 | FNVHash_2(input): |
乘数不固定
1 | RSHash(input): |
- 除法也类似乘法具有不相关性,但太慢
两步随机数
1 | main_rand_seq = randint(k) |
- 全域哈希:键集合 $U$ 包含 $n$ 个键、哈希函数族 $H$ 中哈希函数 $h_i: U \rightarrow 0..m$,若 $H$ 满足以下则为全域哈希 $$
$$\forall x \neq y \in U, | \{h|h \in H, h(x) = h(y) \} | = \frac {|H|} m
- $|H|$:哈希函数集合 $H$ 中函数数量
全域哈希 $H$ 中任选哈希函数 $h_i$,对任意键 $x \neq y \in U$ 冲突概率小于 $\frac 1 m$
全域哈希 $H$ 中任选哈希函数 $hi$,对任意键 $x \in U$,与其冲突键数目期望为 $\frac n m$,即 $E{[collision_x]}=\frac n m$
- $C_x$:任选哈希函数,与 $x$ 冲突的键数量
- $C_{xy} = \left { \begin{matrix} 1, & h_i(x) = h_i(y) \ 0, & otherwise \end{matrix} \right.$:指示 $x,y$ 是否冲突的指示变量
- 以下构造 $[0,p-1] \rightarrow [0,m-1]$ 全域哈希
$p$ 为足够大素数使得所有键值 $\in [0,p-1]$
记哈希函数
则以下哈希函数族即为全域哈希
LSH:局部敏感哈希
- $(r_1,r_2,P_1,P_2)-sensitive$ 哈希函数族 $H$ 需满足如下条件 $$ \begin{align*}
\end{align*}$$Pr_{H}[h(v) = h(q)] \geq P_1, & \forall q \in B(v, r_1) \\ Pr_{H}[h(v) = h(q)] \geq P_2, & \forall q \notin B(v, r_2) \\
- $h \in H$
- $r_1 < r_2, P_1 > P_2$:函数族有效的条件
- $B(v, r)$:点 $v$ 的 $r$ 邻域
- $r_1, r_2$:距离,强调比例时会表示为 $r_1 = R, r_2 = cR$

相似目标更有可能映射到相同哈希桶中
可视为降维查找方法
- 期望放大局部敏感哈希函数族 $Pr_1, Pr_2$ 之间差距
增加哈希值长度(级联哈希函数中基本哈希函数数量) $k$
- 级联哈希函数返回向量,需要对其再做哈希映射为标量,方便查找
增加级联哈希函数数量(哈希表数量) $L$
考虑哈希函数族 $H = { h_1, h_2, \cdots, h_m }$
从 $H$ 中随机的选择哈希函数 $h_i$
考虑 $M * N$ 矩阵 $A$,元素为 0、1
用 Jaccard 系数代表集合间相似距离,用于搜索近邻
对矩阵 $A$ 进行 行随机重排 $\pi$,定义 Min-hashing 如下
- $C$:列,表示带比较集合
- $\min \pi(C)$:$\pi$ 重排矩阵中 $C$ 列中首个 1 所在行数
则不同列(集合) Min-hashing 相等概率等于二者 Jaccard 系数
- $a$:列 $C_1, C_2$ 取值均为 1 的行数
- $b$:列 $C_1, C_2$ 中仅有一者取值为 1 的行数
- 根据 Min-hashing 定义,不同列均取 0 行被忽略
数据量过大时,对行随机重排仍然非常耗时,考虑使用哈希函数模拟行随机重排
为减少遍历数据次数,考虑使用迭代方法求解
1 | for i from 0 to N-1: |
- $D$:原始数据特征矩阵
- $DD$:$Min-hashing* 签名矩阵
- $N$:特征数量,原始特征矩阵行数
- $M$:集合数量,原始特征矩阵列数
- $K$:模拟的随机重排次数,Min-hashing 签名矩阵行数
- $h_k,k=1,…,K$:$K$ 个模拟随机重排的哈希函数,如 $h(x) = (2x + 7) mod N$
$E^2LSH$:欧式局部LSH,LSH Based-on P-stable Distribution
$E^2LSH$ 特点
- $v$:$n$ 维特征向量
- $a = (X_1,X_2,\cdots,X_n)$:其中分量为独立同 p-stable 分布的随机变量
- $b \in [0, r]$:均匀分布随机变量
- 考虑$|v_1 - v_2|_p = c$的两个样本碰撞概率
显然,仅在 $|av1 - av_2| \leq r$ 时,才存在合适的 $b$ 使得 $h{a,b}(v1) = h{a,b}(v_2)$
若 $(k-1)r \leq av_1 \leq av_2 < kr$,即两个样本与 $a$ 内积在同一分段内
若 $(k-1)r \leq av_1 \leq kr \leq av_2$,即两个样本 $a$ 在相邻分段内
考虑 $av_2 - av_1$ 分布为 $cX$,则两样本碰撞概率为
- $c = |v_1 - v_2|_p$:特征向量之间$L_p$范数距离
- $t = a(v_1 - v_2)$
- $f$:p稳定分布的概率密度函数
$p=1$ 柯西分布
$p=2$ 正态分布
$r$ 最优值取决于数据集、查询点
若要求近邻 $v \in B(q,R)$以不小于$1-\sigma$ 概率碰撞,则有
则可取
$k$ 最优值是使得 $T_g + T_c$ 最小者
哈希表数量 $L$ 较多时,所有碰撞样本数量可能非常大,考虑只选择 $3L$ 个样本点
此时每个哈希键位长 $k$、哈希表数量 $L$ 保证以下条件,则算法正确
与 $q$ 距离大于 $r_2$、可能和 $q$ 碰撞的点的数量小于 $3L$
可以证明,$k, L$ 取以下值时,以上两个条件以常数概率成立 (此性质是局部敏感函数性质,不要求是 $E^2LSH$)
$\rho$ 对算法效率起决定性作用,且有以下定理
- 距离尺度 $D$ 下,若 $H$ 为 $(R,cR,p1,p_2)$-敏感哈希函数族,则存在适合 (R,c)-NN 的算法,其空间复杂度为 $O(dn + n^{1+\rho})$、查询时间为 $O(n^{\rho})$ 倍距离计算、哈希函数计算为 $O(n^{\rho} log{1/p_2}n)$, 其中 $\rho = \frac {ln 1/p_1} {ln 1/p_2}$
Scalable LSH:可扩展的 LSH
对动态变化的数据集,固定哈希编码的局部敏感哈希方法对数据 动态支持性有限,无法很好的适应数据集动态变化
在 $E^2LSH$ 基础上通过 动态增强哈希键长,增强哈希函数区分能力,实现可扩展 LSH
稳健优化:利用凸理论、对偶理论中概念,使得凸优化问题中的解 对参数的bounded uncertainty有限不确定性(波动)不敏感
稳健优化在机器学习涉及方面:不确定优化、过拟合
不确定性来源
过拟合判断依据
优化问题对问题参数的扰动非常敏感,以至于解经常不可行、次优
Stochastic Programming:使用概率描述参数不确定性,
稳健优化则假设问题参数在某个给定的先验范围内随意变动
不考虑参数的分布
利用概率论的理论,而不用付出计算上的代价
稳健优化易解性:在满足标准或一点违反 Slater-like regularity conditions情况下,求解稳健优化问题 等同于求解对以下凸集$\mathcal{X(U)}$的划分(求出凸集)
若存在高效算法能确定$x \in \mathcal{X(U)}$、或者能够提供 分离超平面,那么问题可以在多项式时间中求解
即使所有的约束函数$f_i$都是凸函数,此时$\mathcal{X(U)}$ 也是凸集,也有可能没有高效算法能够划分出$\mathcal{X(U)}$
然而在大部分情况下,稳健化后的问题都能高效求解下,和原 问题复杂度相当
- LP:Linear Program,线性规划
- SOCP:Second-Order Cone Program,二阶锥规划
- CQP:Convex Quadratic Program,凸二次规划
- SDP:Semidefinite Program,半定规划
- Polyhedra Uncertainty:多项式类型不确定
- Ellipsodial Uncertainty:椭圆类型不确定
- NP-hard:NP难问题,至少和NPC问题一样困难得问题
Linear Programs with Polyhedral Uncertainty
稳健优化的计算优势很大程度上来源于,其形式是固定的,不再 需要考虑概率分布,只需要考虑不确定集
计算优势使得,即使不确定性是随机、且分布已知,稳健优化 仍然具有吸引力
在一些概率假定下,稳健优化可以给出稳健化问题解的某些 概率保证,如:可行性保证(在给定约束下,解能以多大概率 不超过约束)
原子不确定集
即稳健优化在机器学习中处理不确定性(随机的、对抗性的)
稳健优化中在机器学习中应用
稳健学习在很多学习任务中都有提出
这里考虑经典的二分类软阈值SVM
椭圆不确定集:随机导致的
正则化项使用
概率解释:风险控制
多项式不确定:对抗删除数据(alpha go)
使用无效特征消去偏置
对max损失取对偶得到min带入得到SOCP
统一从稳健优化的角度解释学习算法中的优秀性质
指导寻找新的算法
大数定理、中心极限定理表明即使各个特征上随机不确定项 是独立的,其本身也会有强烈的耦合倾向,表现出相同特征 、像会相互影响一样
这促使寻找新的稳健算法,其中随机不确定项是耦合的
- 对输入空间 $X$ (欧式空间 $R^n$ 的子集或离散集合)、特征空间 $H$ ,若存在从映射 $$
\phi(x): X \rightarrow H$$ 则称 $K(x,z)$ 为核函数、 $\phi(x)$ 为映射函数,其中 $\phi(x) \phi(z)$ 表示内积K(x,z) = \phi(x) \phi(z)
映射函数 $\phi$:输入空间 $R^n$ 到特征空间的映射 $H$ 的映射
对于给定的核 $K(x,z)$ ,映射函数取法不唯一,映射目标的特征空间可以不同,同一特征空间也可以取不同映射,如:
对核函数 $K(x, y) = (x y)^2$ ,输入空间为 $R^2$ ,有
若特征空间为$R^3$,取映射
或取映射
若特征空间为$R^4$,取映射
Kernel Trick 核技巧:利用核函数简化映射函数 $\phi(x)$ 映射、内积的计算技巧
核函数即在核技巧中应用的函数
核技巧常被用于分类器中
- Cover’s 定理可以简单表述为:非线性分类问题映射到高维空间后更有可能线性可分
- 设 $X \subset R^n$,$K(x,z)$ 是定义在 $X X$的对称函数,若 $\forall x_i \in \mathcal{X}, i=1,2,…,m$,$K(x,z)$ 对应的 Gram* 矩阵 $$
$$ 是半正定矩阵,则称 $K(x,z)$ 为正定核G = [K(x_i, x_j)]_{m*m}
线性核:最简单的核函数
多项式核:non-stational kernel
高斯核:radial basis kernel,经典的稳健径向基核
- $\sigma$:带通,取值关于核函数效果,影响高斯分布形状
- 高估:分布过于集中,靠近边缘非常平缓,表现类似像线性一样,非线性能力失效
- 低估:分布过于平缓,失去正则化能力,决策边界对噪声高度敏感
特点
对应映射:省略分母
即高斯核能够把数据映射至无穷维
应用场合
SVM:高斯radial basis function分类器
指数核:高斯核变种,仅去掉范数的平方,也是径向基核
拉普拉斯核:完全等同于的指数核,只是对参数$\sigma$改变敏感 性稍低,也是径向基核
方差核:径向基核
Sigmoid核:来自神经网络领域,被用作人工神经元的激活函数
条件正定,但是实际应用中效果不错
参数
- 使用Sigmoid核的SVM等同于两层感知机神经网络
二次有理核:替代高斯核,计算耗时较小
多元二次核:适用范围同二次有理核,是非正定核
逆多元二次核:和高斯核一样,产生满秩核矩阵,产生无穷维的 特征空间
环形核:从统计角度考虑的核,各向同性稳定核,在$R^2$上正定
类似环形核,在$R^3$上正定
波动核
三角核/幂核:量纲不变核,条件正定
对数核:在图像分隔上经常被使用,条件正定
样条核:以分段三次多项式形式给出
B-样条核:径向基核,通过递归形式给出
- $x_{+}^d$:截断幂函数
Bessel核:在theory of function spaces of fractional smoothness 中非常有名
柯西核:源自柯西分布,是长尾核,定义域广泛,可以用于原始维度 很高的数据
卡方核:源自卡方分布
直方图交叉核:在图像分类中经常用到,适用于图像的直方图特征
广义直方图交叉核:直方图交叉核的扩展,可以应用于更多领域
贝叶斯核:取决于建模的问题
波核:源自波理论
参数
转化不变版本如下
字符串核函数:定义在字符串集合(离散数据集合)上的核函数
$[\phin(s)]_n = \sum{i:s(i)=u} \lambda^{l(i)}$:长度 大于等于n的字符串集合$S$到特征空间 $\mathcal{H} = R^{\sum^n}$的映射,目标特征空间每维对应 一个字符串$u \in \sum^n$
$\sum$:有限字符表
$\sum^n$:$\sum$中元素构成,长度为n的字符串集合
$u = s(i) = s(i1)s(i_2)\cdots s(i{|u|})$:字符串s的 子串u(其自身也可以用此方式表示)
$i =(i1, i_2, \cdots, i{|u|}), 1 \leq i1 < i_2 < … < i{|u|} \leq |s|$:序列指标
$l(i) = i_{|u|} - i_1 + 1 \geq |u|$:字符串长度,仅在 序列指标$i$连续时取等号($j$同)
$0 < \lambda \leq 1$:衰减参数
两个字符串s、t上的字符串核函数,是基于映射$\phi_n$的 特征空间中的内积
应用场合
Azuma-Hoeffding 不等式:设 ${Xi:i=0,1,2,\cdots}$ 是鞅差序列,且 $|X_k - X{k-1}| < c_k$,则
Hoeffding 不等式:考虑随机变量序列 $X_1, X_2, \cdots, X_N, X_i \in [a_i, b_i]$
对随机变量 $\bar X = \frac 1 N \sum_{i=1}^N {X_i}$,对任意 $t>0$ 满足
对随机变量 $SN = \sum{i=1}^N X_i$,对任意 $t>0$ 满足
- 两不等式可用绝对值合并,但将不够精确
Bretagnolle-Huber-Carol 不等式:${X_i: i=1,2,\cdots,N} i.i.d. M(p1, p_2, \cdots, p_k)$ 服从类别为 $k$ 的多项分布
- $N_i$:第 $i$ 类实际个数