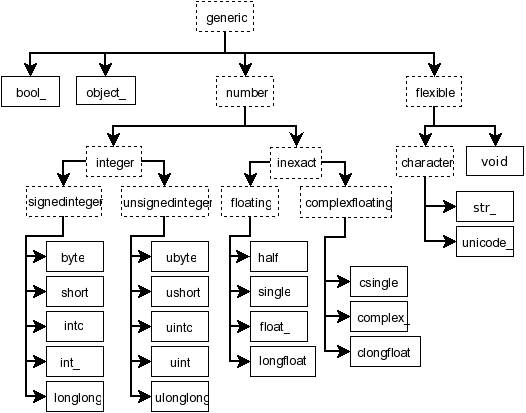
NDArray Routine
Array Manipulation
Shape Only
| Routine | Function Version | Method Version |
|---|---|---|
reshape(a,newshape[,order]) |
||
resize(a,new_shape) |
大小可不同,重复a补不足 |
0补不足 |
ravel(a[,order]) |
展平视图 | |
.flatten([order]) |
无 | 展平副本 |
shape(a) |
||
size(a) |
Order Alteration
| Routine | Function Version | Method Version |
|---|---|---|
transpose(a[,axes]) |
调整轴顺序,缺省逆序即转置 | |
moveaxis(a,source,destination) |
移动数组轴到新位置 | 无 |
rollaxis(a,axis[,start]) |
将指定后向插入至指定位置(缺省0) | 无 |
swapaxes(a,axis1,axis2) |
交换轴 | |
flip(m[,axis]) |
沿指定轴反向,缺省所有轴 | 无 |
fliplr(m) |
左右反向(沿第2轴) | 无 |
flipud(m) |
上下反向(沿第1轴) | 无 |
roll(a,shift[,axis]) |
沿轴滚动shift |
无 |
rot90(m[,k,axes]) |
在axes指定的平面中旋转k次90度 |
无 |
lib.stride_tricks.as_strided(x[,shape,...]) |
利用给定shape、stride在x上创建视图 |
维数改变
| Routine | Function Version | Method Version |
|---|---|---|
atleast_1d(*arys) |
prepend维度直至维度至少维数至少1 | 无 |
atleast_2d(*arys) |
无 | |
atleatt_3d(*arys) |
无 | |
broadcast(*arys) |
广播、打包输入对应元素的元组迭代器,类似zip |
无 |
broadcast_to(array,shape[,subok]) |
广播为指定shape | 无 |
boradcast_arrays(*args,**kwargs) |
输入的广播结果列表 | 无 |
expand_dims(a,axis) |
在指定位置插入新轴 | 无 |
squeeze(a[,axis]) |
删除大小为1维度 |
插入、删除元素
| Routine | Function Version |
|---|---|
delete(arr,obj[,axis]) |
删除obj指定部分,缺省按展平数组删除 |
insert(arr,obj,values[,axis]) |
缺省按展平数组插入 |
append(arr,values[,axis]) |
缺省arr、values展平再添加 |
trim_zeros(filt[,trim]) |
trim前导、尾随0,缺省两边 |
改变类型
| Routine | Function Version | Method Version |
|---|---|---|
asarray(a[,dtype,order]) |
转换为数组 | 无 |
asarray_chkfinite(a[,dtype,order]) |
检查NaN、inf |
无 |
asanyarray(a[,dtype,order]) |
转换为数组,数组子类则不变 | 无 |
ascalar(a) |
将大小为1的数组转换为等效标量 | |
require(a[,dtype,requirements]) |
创建满足要求ndarray.flags数组 |
无 |
asfortranarray(a[,dtype]) |
转换为Fortran-contiguous风格内存布局 | 无 |
ascontiguousarray(a[,dtype]) |
转换为C-contiguous风格内存布局 | 无 |
asmatrix(data[,dtype]) |
无 | |
asfarray(a[,dtype]) |
转换为浮点类型 | 无 |
.astype(dtype[,order,casting,...]) |
无 | 转换为指定类型 |
- numpy中数组不是仅有C、Fortran风格内存布局,对数组的形态 变换会导致内存布局不为任何风格内存布局
组合数组
| Routine | Function Version |
|---|---|
concatenate((a1,a2,...)[,axis,out]) |
沿现有轴连接数组 |
stack(arrays[,axis,out]) |
创建给定(新)轴堆叠数组 |
row_stack(tup)/vstack(tup) |
沿第1(竖直)轴堆叠 |
column_stack(tup)/hstack(tup) |
沿第2(水平)轴堆叠 |
dstack(tup) |
沿第3轴堆叠 |
block(arrays) |
按照arrays中给定数组块、位置组装 |
拆分数组
| Routine | Function Version |
|---|---|
split(ary,indices_or_sections[,axis]) |
沿轴拆分成视图 |
array_split(ary,indices_or_sections[,axis]) |
同split,但可处理不整除拆分 |
vsplit(ary,indices_or_sections) |
沿第1(竖直)轴拆分 |
hsplit(ary,indices_or_sections) |
沿第2(水平)轴拆分 |
dsplit(ary,indices_or_sections) |
沿第3轴拆分 |
Padding
| Function | Desc |
|---|---|
pad(array,pad_width[,mode]) |
Index Routine
结果数组shape考虑逻辑链
- 确定输出数组的维数
ndim - 确定参数数组原维度轴位置、补1轴位置,参数维度轴对齐
- 修正各维度大小
- 沿轴操作:保持不变
- 沿轴采样:采样数目
- 沿轴concate:维度相加
- 沿轴聚集:删除维度
- 沿轴切片聚集:删除其余维度
- 确定输出数组的维数
numpy中(多维)索引往往使用整数高级索引的方式返回
np.ndarray数组:首维度各分量分别表示各维度的高级 索引- list、tuple:各元素分别为各维度的高级索引
数组无关切片、高级索引
| Routine | Function Version | 返回值类型 |
|---|---|---|
s_[] |
支持多维切片生成,类slice() |
切片、元组 |
index_exp[] |
同s_,但总返回元组 |
元组 |
r_[] |
沿第1轴concate切片、数组、标量 | 数组 |
c_[] |
沿第-1轴concate切片、数组、标量(1维则被视为列向量) | 数组 |
ravel_multi_index(multi_index,dims[,mode,order]) |
计算高级索引multi_index在dims数组展平后的位置 |
数组 |
unravel_index(indices,shape[,order]) |
ravel_multi_index逆向 |
元组 |
np.r_[]、np.c_[]除可concate切片方便生成数组,还可以 传递两个参数修改行为r/c字符被设置时,返回矩阵- 1维数组,
r被设置时返回1 N矩阵,c被设置时 返回N 1矩阵 - 2维数组,
r、c被设置时,结果矩阵相同
- 1维数组,
<axis>[,<ndim>,<ori_pos>]三个整形,决定shape|参数|说明|
np.r_[]缺省值|np.c_[]缺省值| |——-|——-|——-|——-| |<axis>|concate执行轴|0|-1| |<ndim>|目标维数,仅在其大于结果维数时才生效|1|2| |<ori_pos>|原数据轴所在的位置|-1,即prepend全1轴|0,即postpend全1轴|相同参数时,两者结果相同,可根据不同数组设置合适的 参数相互实现
np.r_[]可视为参数缺省为0,1,-1np.c_[]可视为参数缺省为-1,2,0
np.r_、np.c_分别是np.lib.index_tricks.RClass、np.lib.index_tricks.CClass实例np.s_、np.index_exp均是np.lib.index_tricks.IndexExpression实例,仅初始化参数 不同
网格
| Routine | Function Version | 返回值类型 |
|---|---|---|
ix_(*args) |
以args为基点创建开网格(仅设置基点、维度) |
元组 |
meshgrid(*xi,**kwargs) |
以xi作为基点创建稠密网格(所有网格点高级索引) |
列表 |
mgrid[] |
根据切片创建稠密网格 | 数组 |
ogrid[] |
根据切片创建开网格 | 列表 |
indices(dimensions[,dtype,sparse]) |
以dimensions作为各维度长创建网格 |
数组、元组 |
- 开网格广播即可得到稠密网格
值相关索引
| Routine | Function Version | Method Version |
|---|---|---|
nonzero(a) |
非0元素整形高级索引 | |
where(condition,[x,y]) |
condition对应整形高级索引,给出x,y时则从中抽取元素 |
无 |
flatnonzero(a) |
展平非0位置 | 无 |
特殊位置索引
| Routine | Function Version |
|---|---|
diag_indices(n[,ndim]) |
ndim维长为n数组对角索引 |
diag_indices_from(arr) |
获取arr对角索引 |
mask_indices(n,mask_func[,k]) |
根据mask_func获取n * n数组索引 |
tril_indices(n[,k,m]) |
n * m的下三角索引 |
triu_indices(n[,k,m]) |
n * m的上三角索引 |
tril_indices_from(arr[,k]) |
arr的下三角索引 |
triu_indices_from(arr[,k]) |
arr的下三角索引 |
np.ndindex(*args) == np.broadcast(*np.indices(*args))
Searching 索引
| Routine | Function Version | Method Version |
|---|---|---|
argwhere(a) |
非0点坐标数组 | 无 |
argmax(a[,axis,out]) |
展平后位置,存在NaN则返回0 |
|
argmin(a[,axis]) |
||
nanargmax(a[,axis]) |
忽略NaN |
|
nanargmin(a[,axis]) |
||
searchsorted(a,v[,side,sorter]) |
应插入(保持有序)位置 |
Value Manipulation
Value Extraction
| Routine | Function Version | Method Version |
|---|---|---|
take(a,indices[,axis,out,mode]) |
按indices沿给定轴获取超平面(缺省将数组展平) |
|
take_along_axis(arr,indices,axis) |
将arr、indices沿axis匹配,选取元素 |
无 |
compress(condition,a[,axis,out]) |
按bool数组condition沿给定轴axis选取超平面(缺省将数组展平) |
|
extract(condition,arr) |
在展平数组上抽取元素 | 无 |
choose(a,choices[,out,mode]) |
根据a广播后元素值选择choices中数组填充对应位置 |
|
select(condlist,choicelist[,default]) |
condlist中首个真值对应的choicelist数组填充对应位置 |
无 |
diag(v[,k]) |
从2维v抽取对角、或以1维v作为对角 |
无 |
diagonal(a[,offset,axis1,axis2]) |
返回给定对象 |
take:沿给定轴从数组中获取元素axis为None时,按展平后获取indices指定元素, 非None时- 函数行为同高级索引
- 指定
axis可以简化通过高级索引获取指定轴的元素
- 基本元素为数组在该轴的切片
1
2
3
4
5
6Ni, Nk = a.shape[:axis], a.shape[axis+1:]
Nj = indices.shape
for ii in np.ndindex(Ni):
for jj in np.ndindex(Nj):
for kk in np.ndindex(Nk):
out[ii+jj+kk] = a[ii+(indices[jj],)+kk]take_along_axis:匹配给定轴方向的1维索引、数据切片, 获取元素- 基本元素为单个元素
- 将
indices和arr对齐,除给定维度外,其余维度 大小均须相同 - 其余维度给定下,按照
indices在超平面上给出的 位置获取对应的元素 - 即
take以超平面为单位获取整个超平面的元素,而take_along_axis按元素为单位,沿给定轴方向调整 元素顺序
- 将
np.argsort、np.argpartition等函数能够返回适合此 函数的索引
1
2
3
4
5
6
7
8
9N1, M, Nk = arr.shape[:axis], arr.shape[axis], arr.shape[axis+1:]
J = indices.shape[axis]
out = np.empty(Ni + (J,) + Nk)
for ii in np.ndindex(Ni):
for kk in np.ndindex(Nk):
a_1d = arr[ii + np.s_[:,] + kk]
indices_1d = indices[ii + np.s_[:,] +kk]
out_1d = out[ii + np.s_[:,] + kk]
out_1d = a_1d[indices_1d[j]]- 基本元素为单个元素
np.choosechoices:数组序列,其中数组和a需广播兼容- 若本身为数组,则其最外层被视为序列
- 逻辑
a、choices中数组共同广播- 广播结果的shape即为结果shape,其中
a取值为n处用数组choices[n]填充
1
np.choose(a,choices) == np.array([choices[a[I]][I] for I in np.ndindex(a.shape)])
np.select- 使用各位置
condlist首个真值出现的位序值构建a,则 等价于np.choose(a,choicelist)(不考虑缺省值)
- 使用各位置
np.extract- 等价于
np.compress(np.ravel(condition), np.ravel(arr)) - 若
condition为bool数组,也等价于arr[condition]
- 等价于
Value Modification
| Routine | Function Version | Method Version |
|---|---|---|
place(arr,mask,vals) |
按照mask循环使用vals中值替换arr中元素 |
无 |
put(a,ind,v[,mode]) |
同place,但根据展平索引ind替换 |
|
put_along_axis(arr,indices,values,axis) |
匹配indices和arr沿axis分量,替换值 |
无 |
copyto(dst,src[,casting,where]) |
根据bool数组where替换dst中元素 |
无 |
putmask(a,mask,values) |
同copyto |
无 |
fill_diagonal(a,val[,wrap]) |
用val填充a的主对角 |
无 |
clip(a,a_min,a_max[,out=None,**kwargs]) |
裁剪值 |
where、mask、condition缺省为、等价为bool数组np.clip是ufunc
Sorting
| Routine | Function Version | Method Version |
|---|---|---|
sort(a[,axis,kind,order,]) |
在位排序 | |
lexsort(keys[,axis]) |
根据keys中多组键沿axis轴排序(靠后优先级高) |
无 |
msort(a) |
沿第1轴排序 | 无 |
argsort(a[,axis,kind,order]) |
沿axis方向间接排序 |
|
sort_complex(a) |
先实、后虚排序 | |
partition(a,kth[,axis,kind,order]) |
以第kth大小数划分 |
|
argpartition(a,kth[,axis,kind,order]) |
间接分段 |
lexsort:按照axis方向、以keys中数组顺序作为权重 进行间接排序keys:数组序列或2维以上数组- 数组最高维视为序列
keys为数组时,最高维被省略- 多个数组视为权重不同的排序依据,靠后优先级高
axis:排序所沿轴方向,缺省为-1,沿最低维轴排序- 可视为按
keys中数组逆序优先级,取用各数组沿轴 方向的间接排序结果 - 即对每个第1轴、
axis构成平面,优先考虑第1轴末尾axis方向数组进行排序,再依次考虑前序
- 可视为按
lexsort、argsort排序方向相同时,lexsort结果中 最后子数组和argsort结果应差别不大 (排序方向相同而不是axis参数取值相同)
Logical Test
真值测试
| Routine | Function Version | Method Version |
|---|---|---|
all(a[,axis,out,keepdims]) |
给定轴方向所有元素为真 | |
any(a[,axis,out,keepdims]) |
给定轴方向存在元素为真 |
数组内容
| Routine | Function Version |
|---|---|
isfinite(x,/[,out,where,casting,order,...]) |
逐元素是否有限 |
isinf(x,/[,out,where,casting,order,...]) |
|
isnan(x,/[,out,where,casting,order,...]) |
|
isnat(x,/[,out,where,casting,order,...]) |
逐元素是否NaT |
isneginf(x,/[,out]) |
|
isposinf(x,/[,out]) |
isneginf、isposinf行为类似ufunc,但不是
类型测试
| Routine | Function Version |
|---|---|
iscomplex(x) |
|
iscomplexobj(x) |
复数类型或复数值 |
isfortran(a) |
Fortran contiguous |
isreal(x) |
|
isrealobj(x) |
实数类型或实数值 |
isscalar(x) |
Mathmatics
- 部分数学函数为ufunc
UFunc初等运算
| Function | Desc |
|---|---|
add(x1,x2,/[out,where,casting,order,...]) |
|
subtract(x1,x2,/[,out,where,casting,...]) |
|
multiply(x1,x2,/[,out,where,casting,...]) |
|
divide(x1,x2,/[,out,where,casting,...]) |
|
true_devide(x1,x2,/[,out,where,casting,...]) |
|
floor_devide(x1,x2,/[,out,where,casting,...]) |
|
logaddexp(x1,x2,/[,out,where,casting,...]) |
ln(x1+x2) |
logaddexp2(x1,x2,/[,out,where,casting,...]) |
log_2 (x1+x2) |
negative(x,/[,out,where,casting,order,...]) |
|
positive(x,/[,out,where,casting,order,...]) |
|
power(x1,x2,/[,out,where,casting,order,...]) |
x1^x2 |
float_power(x1,x2,/[,out,where,casting,...]) |
x1^x2 |
remainder(x1,x2,/[,out,where,casting,...]) |
求余/取模 |
mod(x1,x2,/[,out,where,casting,order,...]) |
求余/取模 |
fmod(x1,x2,/[,out,where,casting,order,...]) |
求余/取模 |
divmod(x1,x2,/[,out1,out2],/[out,...]) |
|
absolute(x,/[,out,where,casting,order,...])/abs |
|
rint(x,/[,out,where,casting,order,...]) |
|
sign(x,/[,out,where,casting,order,...]) |
|
heaviside(x1,x2,/[,out,where,casting,...]) |
阶跃函数 |
conj(x,/[,out,where,casting,...]) |
对偶 |
exp(x,/[,out,where,casting,order,...]) |
|
exp2(x,/[,out,where,casting,order,...]) |
|
log(x,/[,out,where,casting,order,...]) |
|
log2(x,/[,out,where,casting,order,...]) |
|
log10(x,/[,out,where,casting,order,...]) |
|
expm1(x,/[,out,where,casting,order,...]) |
计算exp(x)-1 |
log1p(x,/[,out,where,casting,order,...]) |
计算ln(x+1) |
sqrt(x,/[,out,where,casting,order,...]) |
非负平方根 |
square(x,/[,out,where,casting,order,...]) |
|
cbrt(x,/[,out,where,casting,order,...]) |
立方根 |
reciprocal(x,/[,out,where,casting,order,...]) |
倒数 |
gcd(x,/[,out,where,casting,order,...]) |
最大公约数 |
lcm(x,/[,out,where,casting,order,...]) |
最小公倍数 |
out参数可用于节省内存,如:G=A*B+C- 等价于:
t1=A*B; G=t1+C; del t1; - 可利用
out节省中间过程内存:G=A*B; np.add(G,C,G)
- 等价于:
UFunc Floating函数
| Routine | Function Version |
|---|---|
fabs(x,/[,out,where,casting,order,...]) |
不可用于复数 |
signbit(x,/[,out,where,casting,order,...]) |
signbit是否设置,即<0 |
copysign(x1,x2,/[,out,where,casting,order,...]) |
根据x1设置x2的signbit |
nextafter(x1,x2,/[,out,where,casting,order,...]) |
x1朝向x2的下个浮点数,即变动最小精度 |
spacing(x,/[,out,where,casting,order,...]) |
x和最近浮点数距离,即取值的最小精度 |
modf(x[,out1,out2],/[,out,where],...) |
返回取值的整数、小数部分 |
ldexp(x1,x2,/[,out,where,casting,...]) |
计算x1*2**x2,即还原2为底的科学计数 |
frexp(x[,out1,out2],/[,out,where],...) |
返回2为底的科学计数的假数、指数 |
floor(x,/,out,*,where,...) |
|
ceil(x,/,out,*,where,...) |
|
trunc(x,/,out,*,where,...) |
|
rint(x,/[,out,where,casting,order,...]) |
最近整数 |
around(a[,decimals,out])/round/round_ |
|
fix(x[,out]) |
向零点取整 |
np.fix不是ufunc,但行为类似
比较函数
数值比较
np.equal()更多应用于整形比较,比较浮点使用np.isclose()更合适np.allclose()则是判断数组整体是否相同array_equal(a1,a2)数组a1、a2相同array_equiv(a1,a2)数组a1、a2广播后相同
逻辑运算符
&、|、~:逐元素逻辑运算- 优先级高于比较运算符
and、or、not:整个数组的逻辑运算
np.maximum()、np.minimum()函数max()寻找最大值效率比np.maximum.reduce()低,同样min()效率也较低
UFunc比较函数
| Routine | Function Version | Method Version |
|---|---|---|
greater(x1,x2,/[,out,where,casting,...]) |
> |
|
greater_equal(x1,x2,/[,out,where,casting,...]) |
>= |
|
less(x1,x2,/[,out,where,casting,...]) |
< |
|
less_equal(x1,x2,/[,out,where,casting,...]) |
<= |
|
not_equal(x1,x2,/[,out,where,casting,...]) |
!= |
|
equal(x1,x2,/[,out,where,casting,...]) |
== |
|
logical_and(x1,x2,/[,out,where,casting,...]) |
逐元素and |
and |
logical_or(x1,x2,/[,out,where,casting,...]) |
or |
|
logical_xor(x1,x2,/[,out,where,casting,...]) |
无 | |
logical_not(x1,x2,/[,out,where,casting,...]) |
not |
|
maximum(x1,x2,/[,out,where,casting,...]) |
逐元素选择较大者 | |
minimum(x1,x2,/[,out,where,casting,...]) |
逐元素选择较小者 | |
fmax(x1,x2,/[,out,where,casting,...]) |
逐元素选择较大者,忽略NaN |
|
fmin(x1,x2,/[,out,where,casting,...]) |
逐元素选择较小者,忽略NaN |
非UFunc
| Routine | Function Version |
|---|---|
isclose(a,b[,rtol,atol,equal_nan]) |
逐元素容忍度范围内相等 |
allclose(a,b[,rtol,atol,equal_nan]) |
all(isclose()) |
array_equal(a1,a2[,equal_nan]) |
数组整体 |
array_equiv(a1,a2) |
广播后相等 |
UFunc Bit-twiddling函数
| Routine | Function Version |
|---|---|
bitwise_and(x1,x2,/[,out,where,...]) |
|
bitwise_or(x1,x2,/[,out,where,...]) |
|
bitwise_xor(x1,x2,/[,out,where,...]) |
|
invert(x,/[,out,where,casting,...]) |
|
left_shift(x1,x2,/[,out,where,casting...]) |
|
left_shift(x1,x2,/[,out,where,casting...]) |
UFunc 三角函数
| Routine | Function Version |
|---|---|
sin(x,/[,out,where,casting,order,...]) |
|
cos(x,/[,out,where,casting,order,...]) |
|
tan(x,/[,out,where,casting,order,...]) |
|
arcsin(x,/[,out,where,casting,order,...]) |
|
arccos(x,/[,out,where,casting,order,...]) |
|
arctan(x,/[,out,where,casting,order,...]) |
|
arctan2(x1,x2,/[,out,where,casting,order,...]) |
考虑象限下,arctan(x1/x2) |
hypot(x1,x2,/[,out,where,casting,order,...]) |
计算斜边 |
sinh(x,/[,out,where,casting,order,...]) |
双曲正弦 |
cosh(x,/[,out,where,casting,order,...]) |
|
tanh(x,/[,out,where,casting,order,...]) |
|
arcsinh(x,/[,out,where,casting,order,...]) |
|
arccosh(x,/[,out,where,casting,order,...]) |
|
arctanh(x,/[,out,where,casting,order,...]) |
|
deg2rad(x,/[,out,where,casting,order,...]) |
角度转换为弧度 |
rad2deg/degrees(x,/[,out,where,casting,order,...]) |
弧度转换为角度 |
基本数学
| Routine | Function Version | Method Version |
|---|---|---|
prod(a[,axis,dtype,out,keepdims,...]) |
||
nanprod(a[,axis,dtype,out,keepdims,...]) |
无 | |
sum(a[,axis,dtype,out,keepdims,...]) |
||
nansum(a[,axis,dtype,out,keepdims,...]) |
无 | |
cumprod(a[,axis,dtype,out,keepdims,...]) |
累乘(也可用ufunc.accumulate) | |
cumsum(a[,axis,dtype,out,keepdims,...]) |
累加 | |
nancumprod(a[,axis,dtype,out,keepdims,...]) |
NaN视为1 |
无 |
nancumsum(a[,axis,dtype,out,keepdims,...]) |
NaN视为0 |
无 |
diff(a[,n,axis,prepend,append,...]) |
沿给定轴1阶差分(保持类型不变,注意溢出) | 无 |
ediff1d(ary[,to_end,to_begin] |
沿展平顺序1阶差分 | 无 |
gradient(f,*varargs,**kwargs) |
梯度 | 无 |
cross(a,b[,axisa,axisb,axisc,axis]) |
向量叉积 | 无 |
trapz(y[,x,dx,axis]) |
梯形法则定积分 | 无 |
复数运算
| Routine | Function Version | Method Version |
|---|---|---|
angle(z[,deg]) |
角度 | 无 |
real(val) |
实部 | |
imag(val) |
虚部 | |
conj/conjugate(x,/[,out,where,casting,order,...]) |
复共轭 |
Miscellaneous
| Routine | Function Version |
|---|---|
nan_to_num(x[,copy,nan,posinf,neginf]) |
替换NaN、inf为数值 |
real_if_close(a[,to]) |
虚部接近0则省略 |
interp(x,xp,fp[,left,right,period]) |
1维线性插值 |
polyfit(x,y,deg[,rcond,full,w,cov]) |
最小二乘多项式拟合 |
Statistics
axis=None:默认值None,表示在整个数组上执行操作
Count
| Routine | Function Version |
|---|---|
count_nonzero(a[,axis]) |
顺序
| Routine | Function Version | Method Version |
|---|---|---|
amin/min(a[,axis,out,keepdims,initial,where]) |
||
amax/max(a[,axis,out,keepdims,initial,where]) |
||
nanmin(a[,axis,out,keepdims,initial,where]) |
忽略NaN |
|
nanmax(a[,axis,out,keepdims,initial,where]) |
||
ptp(a[,axis,out,keepdims]) |
极差 | |
percentile(a,q[,axis,out,...]) |
q取值[0-100] |
无 |
nanpercentile(a,q[,axis,out,...]) |
无 | |
quantile(a,q[,axis,out,overwrite_input,...]) |
q取值[0,1] |
无 |
nanquantile(a,q[,axis,out,...]) |
无 |
均值、方差
| Routine | Function Version | Method Version |
|---|---|---|
median(a[,axis,out,overwrite_input,keepdims]) |
无 | |
average(a[,axis,weights,returned]) |
无 | |
mean(a[,axis,dtype,out,keepdims]) |
||
std(a[,axis,dtype,out,ddof,keepdims]) |
标准差 | |
var(a[,axis,dtype,out,ddof,keepdims]) |
方查 | |
nanmedian(a[,axis,out,overwrite_input,...]) |
无 | |
nanmean(a[,axis,dtype,out,keepdims]) |
无 | |
nanstd(a[,axis,dtype,out,ddof,keepdims]) |
无 | |
nanvar(a[,axis,dtype,out,ddof,keepdims]) |
无 |
相关系数
| Routine | Function Version |
|---|---|
corrcoef(x[,y,rowvar,bias,ddof]) |
Pearson积差相关系数 |
correlate(a,v[,mode]) |
卷积 |
convolve(a,v[,mode]) |
离散、线性卷积 |
cov(m[,y,rowvar,bias,ddof,fweights,...]) |
方差 |
Array Creation
Ones and Zeros
| Routine | Function Version |
|---|---|
empty(shape[,dtype,order]) |
无初始化 |
empty_like(prototype[,dtype,order,subok,...]) |
shape、类型同prototype |
eye(N[,M,k,dtype,order]) |
对角为1的2D数组 |
identity(n[,dtype]) |
单位矩阵数组 |
ones(shape[,dtype,order]) |
|
ones_like(a[,dtype,order,subok,shape]) |
|
zeros(shape[,dtype,order]) |
|
zeros_like(a[,dtype,order,subok,shape]) |
|
full(shape,fill_value[,dtype,order]) |
全full_value数组 |
full_like(a,fill_value[,dtype,order,...]) |
Numerical Ranges
| Routine | Function Version |
|---|---|
arange([start,]stop[,step][,dtpye]) |
给定间距 |
linspace(start,stop[,num,endpoint]) |
给定数量,等差均分 |
geomspace(start,stop[,num,endpoint,base,...]) |
等比均分 |
logspace(start,stop[,num,endpoint,base,...]) |
在log10尺度上均分,同np.power(10, np.linspace(start,stop)) |
Repetition
| Routine | Function Version | Method Version |
|---|---|---|
tile(A,reps) |
重复A(可是数组)创建一维数组 |
无 |
repeat(a,repeats[,axis]) |
沿已有轴重复a创建 |
Matrix-Relative
| Routine | Function Version |
|---|---|
diag(v[,k]) |
从2维v抽取对角、或以1维v作为对角 |
diagflat(v[,k]) |
|
tri(N[,M,k,dtype]) |
对角线及以下为1、其余为0矩阵 |
tril(m[,k]) |
下三角 |
triu(m[,k]) |
上三角 |
vander(x[,N,increasing]) |
Vandermonde矩阵 |
From Existing Data
| Routine | Function Version |
|---|---|
array(object[,dtype,copy,order,subok,ndmin]) |
|
copy(a[,order]) |
|
frombuffer(buffer[,dtype,count,offset] |
从缓冲(如字节串)创建数组 |
fromfunction(function,shape,**kwargs) |
以坐标为参数,从函数创建数组 |
fromiter(iterable,dtype[,count]) |
- 改变数组数据类型也可以视为是创建新数组
转入、转出
类型转出
| Routine | Method Version |
|---|---|
.item(*args) |
根据args选择元素复制至标准python标量 |
.tolist() |
转换为.ndim层嵌套python标量列表 |
.itemset(*args) |
插入元素(尝试转换类型) |
.byteswap([inplace]) |
反转字节序 |
.view([dtype,type]) |
创建新视图 |
.getfield(dtype[,offset]) |
设置数据类型为指定类型 |
.setflags([write,align,uic]) |
设置标志 |
.fill(value) |
使用标量填充 |
打包二进制
| Function | Desc |
|---|---|
packbits(a[,axis,bitorder]) |
元素打包为标志位,0补足,返回uint8数组 |
upackbits(a[,axis,bitorder]) |
输入、输出
| Routine | 格式 | 输入 | 输出 |
|---|---|---|---|
dump(file) |
pickle | 无 | 文件 |
tofile(fid[,sep,format]) |
内存内容(sep="")、分割符串 |
无 | 文件 |
fromfile(file[,dtype,count,sep,offset]) |
字节串、分割符串 | 文件 | 数组 |
save(file,arr[,allow_pickle,fix_imports]) |
.npy |
数组 | 文件 |
savez(file,*args,**kwds) |
非压缩的.npz |
(多个)数组 | 文件 |
savez_compressed(file,*args,**kwds) |
压缩的.npz |
(多个)数组 | 无 |
load(file[,mmap_mode,allow_pickle,...]) |
.npy、.npz、pickle |
文件 | 数组 |
savetxt(fname,X[,fmt,delimiter,newline,...]) |
分割符串 | 二维以下数组 | 文件 |
loadtxt(fname[,dtype,comments,delimiter,...]) |
分割符串 | 文件 | 数组 |
genfromtxt(fname[,dtype,comments,...]) |
分割符串 | 文件 | 数组 |
fromregex(file,regexp,dtype[,encoding]) |
正则表达式结构 | 文件 | 数组 |
串
| Routine | Function Version | Method Version | |
|---|---|---|---|
array2string(a[,max_line_width,precision,...]) |
__str__ |
||
array_repr(arr[,max_line_width,precision,...]) |
__repr__ |
||
array_str(arr[,max_line_width,precision,...]) |
__str__ |
||
dumps() |
无 | pickle序列化 | |
loads(*args,**kwargs) |
pickle | 字节串 | 数组 |
tobytes([order])/tostring |
内存内容字节串 | ||
fromstring(string[,dtype,count,sep]) |
从字符串、字节串(sep="",且缺省)创建1维数组 |
np.loads即pickle.loads,不建议使用np.fromstringsep="":从二进制字节串中创建数组,类frombuffersep置为分割符时,只能指定一种元素分隔符,也只能 解析1维数组的字符串
字符串输出格式
| Routine | Function Version |
|---|---|
format_float_positional(x[,precision,...]) |
格式化位置计数 |
format_float_scientific(x[,precision,...]) |
格式化科学计数 |
set_printoptions([precision,threshold,...]) |
|
get_printoptions() |
|
set_string_function(f[,repr]) |
|
printoptions(*args,**kwargs) |
设置打印选项的上下文管理器 |
binary_repr(num[,width]) |
二进制字符串 |
base_repr(number[,base,padding]) |
Data Source
| Function | Desc |
|---|---|
DataSource([destpath]) |
通用数据源文件(file,http,ftp等) |