Kernel
内核:提供硬件抽象层、磁盘及文件系统控制、多任务等功能的系统
软件
内核功能
System Call
系统调用:操作系统提供的实现系统功能的子程序、访问硬件资源
的唯一入口
系统调用意义
用户程序通过系统调用使用硬件,简化开发、移植性
- 分离了用户程序和内核的开发
- 用户程序忽略API具体实现,仅借助其开发应用
- 内核忽略API被调用,只需关心系统调用API实现
- 为用户空间提供了统一硬件抽象接口,用户程序可以方便在
具有相同系统调用不同平台之间迁移
系统调用保证了系统稳定和安全
- 内核可以基于权限和其他规则对需要进行的访问进行
裁决
- 避免程序不正确的使用硬件设备、窃取其他进程资源、
危害系统安全
保证进程可以正常运行在虚拟寻址空间中
- 程序可以随意访问硬件、内核而对此没有足够了解,
则难以实现多任务、虚拟内存
- 无法实现良好的稳定性、安全性
通知内核
- 大部分情况下,程序通过API而不是直接调用系统调用
- POSIX标准是Unix世界最流行的API接口规范,其中API和系统
调用之间有直接关系,但也不是一一对应
系统调用表
系统调用表sys_call_table:其中元素是系统调用服务例程的
起始地址
1
2
3
4
5
|
asmlinkage const sys_call_ptr sys_call_table[__NR_syscall_max+1] ={
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};
|
...是GCCDesignated Initializers插件功能,此插件允许
无序初始化元素值
sys_call_table是长为__NR_syscall_max+1的数组
__NR_syscall_max是给定系统架构所允许的最大系统调用
数目
1
2
|
#define __NR_syscall_max 547
|
- 此数值必然和
arch/x86/entry/syscalls/syscall_64.tbl
中最大系统调用数值相同
sys_call_ptr是指向系统调用表指针类型
1
| typedef void (*sys_call_ptr_t)(void);
|
sys_ni_syscall是返回错误的函数
1
2
3
| asmlinkage long sys_ni_syscall(void){
return -ENOSYS;
}
|
- 未在
<asm/syscalls_64.h>定义系统调用号将会对应此
响应函数,返回ENOSYS专属错误
<asm/syscalls_64.h>由脚本
arch/x86/entry/syscalls/syscalltbl.sh从
arch/x86/entry/syscalls/syscall_64.tbl中生成
1
2
3
4
5
6
7
|
__SYS_COMMON(0, sys_read, sys_read)
__SYS_COMMON(0, sys_write, sys_write)
#define __SYSCALL_COMMON(nr, sym, compat) __SYSCALL_64(nr, sym, compat)
#define __SYSCALL_64(nr, sym, compat) [nr] = sym
|
系统调用号
1
2
3
4
5
6
7
|
#define __NR_setxattr 5
__SYSCALL(__NR_setxattr, sys_setxattr)
#define __NR_lsetxattr 6
__SYSYCALL(__NR_lsetxattr, sys_lsetattr)
#define __NR_fsetxattr 7
__SYSYCALL(__NR_fsetxattr, sys_fsetattr)
|
系统调用号_NR_XXX:系统调用唯一标识
陷入指令
__syscall[N]
_syscall[N]:方便用户程序访问系统调用的一系列宏
1
2
3
4
5
6
|
__syscall0(type, name)
__syscall1(type, name, type1, args1)
__syscall2(type, name, type1, arg1, type2, arg2)
__syscall6(type, name, type1, arg1, type2, arg2, type3, arg3, type4, arg4, type5, arg5, type6, arg6)
|
1
2
3
4
5
6
7
8
9
10
| #define _syscall2(type, name, type1, arg1, type2, arg2) \
type name(type1, arg1, type2, arg2) \
{ \
long _res; \
__asm__ volatile ("int $0x80" \
: "=a" (_res) \
: "0" (__NR##name), "b" ((long)(arg1)), "c" ((long)(arg2))); \
__syscall_return(type, __res)
}
|
- 大部分情况下用户程序都是通过库函数访问系统调用,调用
__syscall[N]系列宏通常由库函数完成
- Linux2.6.19内核之后弃用
syscall
syscall:通过系统调用号相应参数访问系统调用
1
2
3
4
5
6
7
8
9
10
11
| int syscall(int number, ...);
#include <unistd.h>
#include <sys/syscall.h>
#include <sys/types.h>
int main(int argc, char *argv){
pid_t tid;
// `SYS_[NAME]`是系统调用号常量
tid = syscall(SYS_getpid);
}
|
System Call Service Routine
系统调用服务例程/响应函数:系统调用的实际处理逻辑
参数传递
参数传递
- 除系统调用号外参数输入同样存放在寄存器中
- X86机器上,
ebx、ecx、edx、esi、edi按照顺序
存放前5个参数
- 需要6个以上参数情况不多,此时应该用单独的寄存器存放
指向所有参数在用户空间地址的指针
参数验证
系统调用需要检查参数是否合法有效、正确
- 文件IO相关系统调用需要检查文件描述符是否有效
- 进程相关函数需要检查PID是否有效
用户指针检查,内核必须保证
- 指针指向的内存区域属于用户空间:不能哄骗内核读取
内核空间数据
- 指针指向的内存区域在进程地址空间:不能哄骗内核读取
其他进程数据
- 进程不能绕过内存访问限制:内存读、写应被正确标记
访问系统调用
系统调用初始化
系统调用上下文
系统调用返回值
errno错误码
系统调用将错误码放入名为errno的全局变量中
- 为防止和正常返回值混淆,系统调用不直接返回错误码
errno值只在函数发生错误时设置,若函数不发生错误,
errno值无定义,并不置为0
0值通常表示成功- 负值表示系统调用失败
- 错误值对应错误消息定义在
error.h中
- 可以通过
perror()库函数翻译误码
- 处理
errno前最好将其存入其他变量中,因为在错误处理
过程中errno值可能会被改变
系统调用具有明确的操作
ret_from_sys_call
Linux系统调用、派生函数
进程管理
进程控制
fork:创建新进程clone:按照指定条件创建子进程execve:运行可执行文件exit:终止进程_exit:立即终止当前进程getdtablesize:进程能打开的最大文件数getpgid:获取指定进程组标识号setpgid:设置指定进程组标识号getpgrp:获取当前进程组标识号setpgrp:设置当前进程组标识号getpid:获取进程标识号getppid:获取父进程标识号getpriority:获取调度优先级setpriority:设置调度优先级modify_ldt:读写进程本地描述符nanosleep:使指定进程睡眠nice:改变分时进程的优先级pause:挂起进程,等待信号personality:设置进程运行域prctl:对进程进行特定操作ptrace:进程跟踪sched_get_priority_max:取得静态优先级上限sched_get_priority_min:取得静态优先级下限sched_getparam:取得进程调度参数sched_getscheduler:取得指定进程的调度策略sched_rr_get_interval:取得按RR算法实调度的实时进程
时间片sched_setparam:设置进程调度参数sched_setscheduler:设置进程调度策略和参数sched_yield:进程主动出让处理器,并添加到调度队列队尾vfork:创建执行新程序的子进程wait/wait3:等待子进程终止watipid/wait4:等待指定子进程终止capget:获取进程权限capset:设置进程权限getsid:获取会晤标识号setsid:设置会晤标识号
进程间通信
信号
sigaction:设置对指定信号的处理方法sigprocmask:根据参数对信号集中的号执行阻塞、解除
阻塞等操作sigpending:为指定被阻塞信号设置队列sigsuspend:挂起进程等待特定信号signalkill:向进程、进程组发信号sigvec:为兼容BSD设置的信号处理函数,作用类似
sigactionssetmask:ANSI C的信号处理函数,作用类似sigaction
消息
msgctl:消息控制操作msgget:获取消息队列msgsnd:发消息msgrcv:取消息
管道
信号量
semctl:信号量控制semget:获取一组信号量semop:信号量操作
内存管理
内存管理
brk/sbrk:改变数据段空间分配mlock:内存页面加锁munlock:内存页面解锁mlockall:进程所有内存页面加锁munlockall:进程所有内存页面解锁mmap:映射虚拟内存页munmap:去除内存映射页mremap:重新映射虚拟内存地址msync:将映射内存中数据写回磁盘mprotect:设置内存映像保护getpagesize:获取页面大小sync:将内存缓冲区数据写回磁盘cacheflush:将指定缓冲区中内容写回磁盘
共享内存
shmctl:控制共享内存shmget:获取共享内存shmat:连接共享内存shmdt:卸载共享内存
文件管理
文件读写
tcntl:文件控制open:打开文件creat:创建新文件close :关闭文件描述字read:读文件write:写文件readv:从文件读入数据到缓存区writev:将缓冲区数据写入文件pread:随机读文件pwrite:随机写文件lseek:移动文件指针_llseek:64位地址空间中移动文件指针dup:复制已打开的文件描述字dup2:按指定条件复制文件描述字flock:文件加/解锁poll:IO多路切换truncat/ftruncate:截断文件vumask:设置文件权限掩码fsync:将内存中文件数据写入磁盘
文件系统操作
access:确定文件可存取性chdir/fchdir:改变当前工作目录chmod/fchmod:改变文件模式chown/fchown/lchown:改变文件属主、用户组chroot:改变根目录stat/lstat/fstat:获取文件状态信息statfs/fstatfs:获取文件系统信息ustat:读取文件系统信息mount:安装文件系统umount:卸载文件系统readdir:读取目录项getdents:读取目录项mkdir:创建目录mknod:创建索引节点rmdir:删除目录rename:文件改名link:创建链接symlink:创建符号链接unlink:删除链接readlink:读取符合链接值utime/utimes:改变文件的访问修改时间quotactl:控制磁盘配额
驱动管理
系统控制
ioctl:IO总控制函数_sysctl:读写系统参数acct:启用或禁用进程记账getrlimit:获取系统资源上限setrlimit:设置系统资源上限getrusage:获取系统资源使用情况uselib:选择要使用的二进制库ioperm:设置端口IO权限iopl:改变进程IO权限级别outb:低级端口操作reboot:重启swapon:开启交换文件和设备swapoff:关闭交换文件和设备bdflush:控制bdflush守护进程sysfs:获取核心支持的文件系统类型sysinfo:获取系统信息adjtimex:调整系统时钟getitimer:获取计时器值setitimer:设置计时器值gettimeofday:获取时间、时区settimeofday:设置时间、时区stime:设置系统日期和时间time:获取系统时间times:获取进程运行时间uname:获取当前unix系统名称、版本、主机信息vhangup:挂起当前终端nfsservctl:控制NFS守护进程vm86:进入模拟8086模式create_module:创建可载入模块项delete_module:删除可载入模块项init_module:初始化模块query_module:查询模型信息
网络管理
网络管理
getdomainname:获取域名setdomainname:设置域名gethostid:获取主机标识号sethostid:设置主机标识号gethostname:获取主机名称sethostname:设置主机名称
Socket控制
socketcall:socket系统调用socket:建立socketbind:绑定socket到端口connect:连接远程主机accept:响应socket连接请求send/sendmsg:通过socket发送信息sendto:发送UDP信息recv/recvmsg:通过socket接收信息recvfrom:接收UDP信息listen:监听socket端口select:对多路同步IO进行轮询shutdown:关闭socket上连接getsockname:获取本地socket名称getpeername:获取通信对方socket名称getsockopt:获取端口设置setsockopt:设置端口参数sendfile:在文件端口间传输数据socketpair:创建一对已连接的无名socket
用户管理
getuid:获取用户标识号setuid:设置用户标识号getgid:获取组标识号setgid:设置组标识号getegid:获取有效组标识号setegid:设置有效组标识号geteuid:获取有效用户标识号seteuid:设置有效用户标识号setregid:分别设置真实、有效的组标识号setreuid:分别设置真实、有效的用户标识号getresgid:分别获取真实、有效、保存过的组标识号setresgid:分别设置真实、有效、保存过的组标识号getresuid:分别获取真实、有效、保存过的用户标识号setresuid:分别设置真实、有效、保存过的用户标识号setfsgid:设置文件系统检查时使用的组标识号setfsuid:设置文件系统检查时使用的用户标识号getgroups:获取候补组标志清单setgroups:设置候补组标志清单
通知内核
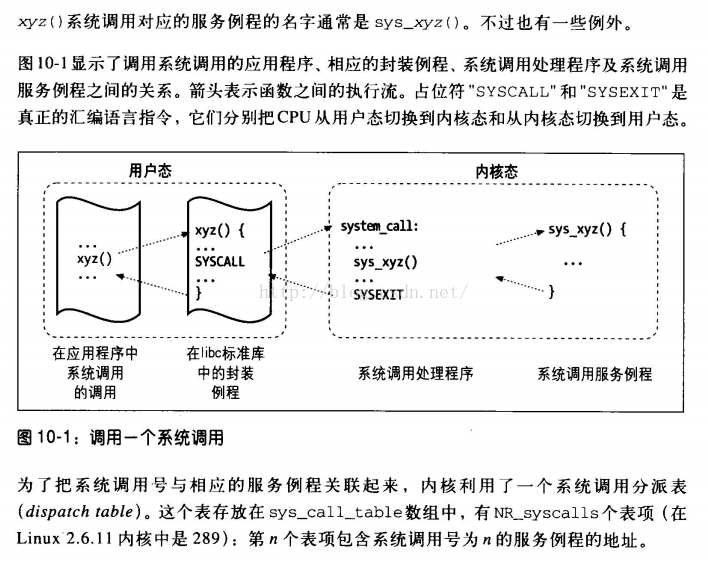
一般系统调用都是通过软件中断向内核发请求,实现内核提供的
某些服务
- 128号异常处理程序就是系统调用处理程序
system_call()
用户空间进程不能直接执行内核代码,需要通过中断通知内核
需要执行系统调用,希望系统切换到内核态,让内核可以代表
应用程序执行系统调用
通知内核机制是靠软件中断实现,X86机器上软中断由int产生
- 用户程序为系统调用设置参数,其中一个参数是系统调用
编号
- 程序执行“系统调用”指令,该指令会导致异常
- 保存程序状态
- 处理器切换到内核态并跳转到新地址,并开始执行异常处理
程序,即系统调用处理程序
- 将控制权返还给用户程序
arch/i386/kernel/head.s
init/main.carhc/i386/kernel/traps.cinclude/asm/system.h
参数传递