SparkSQL2.4中启用CBO时JoinReorder分析
背景
Spark Join方式
SparkSQL目前支持三种join方式
broadcast hash join:将小表广播分发到大表所在的结点上 ,并行在各节点上进行hash join
- 仅适合内表非常小的场合
shuffle hash join:按照join key分区,每个结点独立并行 进行hash join
- 类似分布式GHJ,不同块位于不同结点
sort merge join:按照join key分区,在各节点独立并行SMJ
- spark当前shuffle算法使用sort-based shuffle算法
- 理论上shuffle过后各分区数据已经排序完毕,无需再次 sort,效率很高
Join类型
SparkSQL支持的Join类型可以分为以下两类
顺序结果无关Join
- inner join
- (full)outer join
顺序结果相关Join
- left(outer) join
- right(outer) join
- left semi join
- right semi join
考虑到JoinReorder的结果
仅支持连接重排序的连接类型只可能是inner join outer join
而outer join重排序虽然不影响结果,但是处理不方便,所以 联接重排序一般仅限于inner join???
- 有些情况下RBO可以将外联接等价转换为内联接
- SparkSQL2.4中支持的连接重排序仅限于内连接
Cost-Based Opitimization/Optimizer
CBO:基于成本的优化(器)
根据SQL的执行成本制定、优化查询作业执行计划,生成可能 的执行计划中代价最小的计划
- 数据表统计数据
- 基/势
- 唯一值数量
- 空值数量
- 平均、最大长度
- SQL执行路径I/O
- 网络资源
- CPU使用情况
- 数据表统计数据
在SparkSQL Hash Join中可以用于
- 选择正确hash建表方
- 选择正确join类型:广播hash、全洗牌hash
- join reorder:调整多路join顺序
CBO本身需要耗费一定资源,需要平衡CBO和查询计划优化程度
- 数据表的数据统计资源耗费
- 优化查询计划即时资源耗费
- CBO是相较于Rule-Based Optimization的概念
CBO中的独特概念
cardinality:集的势,结果集的行数
- 表示SQL执行成本值
- SQL执行返回的结果集包含的行数越多,成本越大
selectivity:可选择率,施加指定谓语条件后返回结果集的 记录数占未施加任何谓语条件的原始结果记录数的比率
- 值越小,说明可选择性越好
- 值越大,说明可选择性越差,成本值越大
Join Reorder
Join Reorder:基于CBO的多表连接顺序重排
用统计信息预估的基修正join顺序
主要涉及到以下两个方面
- 查询代价估算
- 多表连接顺序搜索算法
查询代价估计
代价模型
单个join操作成本
- carinality:对应CPU成本
- size:对应IO成本
join树的成本是所有中间join成本总和
Filter Selectivity估计
过滤选择率:估计应用谓词表达式过滤的选择率
逻辑运算符
AND:左侧过滤条件选择率、右侧过滤条件选择率之积OR:左侧、右侧过滤条件选择率之和,减去其乘积NOT:1减去原始过滤条件选择率
比较运算符
=:等于条件- 若常数取值在当前列取值范围之外,则过滤选择率为0
- 否则根据柱状图、均匀分布得到过滤选择率
<:小于条件- 若常数取值小于当前列最小值,则过滤选择率为0
- 否则根据柱状图、均匀分数得到过滤选择率
Join Carinality估计
联接基:估计联接操作结果的基
inner:其他基估计值可由inner join计算
num(A):join操作前表A的有效记录数distinct(A.k):表A中列k唯一值数量
left-outer:取inner join、左表中基较大者
right-outer:取inner join、右表中基较大者
full-outer
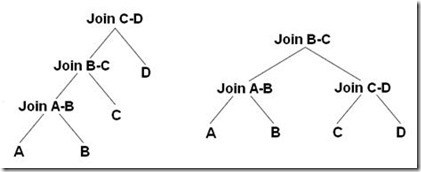
多表连接顺序搜索算法
SparkSQL2.4中使用动态规划算法对可能联接顺序进行搜索,从中 选择最优的联接顺序作为执行计划
最优子结构:一旦前k个表联接顺序确定,则联接前中间表和 第k+1个表方案和前k个表的联接顺序无关
动态规划表:从单表代价开始,逐层向上计算各层多表联接代价 ,直到求得所有表联接最小代价
减少搜索空间启发式想法:尽可能优先有谓词限制的内连接、 中间表
评价
- 优势:动态规划算法能够求得整个搜索空间中最优解
- 缺陷:当联接表数量增加时,算法需要搜索的空间增加的非常快 ,计算最优联接顺序代价很高
PostgreSQL
代价模型
Postgres的查询代价估计模型基于CPU开销、IO开销,另外还增加 了启动代价
动态规划算法
类似SparkSQL2.4多表连接算法(假设联接n个表)
构造第一层关系:每个关系的最优路径就是关系的最优单表扫描 方式
迭代依次构造之后n-1层关系联接最优解
- 左深联接树方式:将第k-1层每个关系同第1层关系联接
- 紧密树联接方式:将第m(m > 2)层每个关系同第k-m层关系 联接
遗传算法
遗传算法:模拟自然界生物进化过程,采用人工进化的方式对目标 空间进行搜索
- 本质是高效、并行、全局搜索方法
- 能在搜索过程中自动获取、积累有关搜索空间的知识,并自适应 的控制搜索过程以求的最佳解
思想
- 将问题域中可能解看作是染色体,将其编码为符号串的形式
- 对染色体群体反复进行基于遗传学的操作:选择、交叉、变异
- 根据预定目标适应度函数对每个个体进行评价,不断得到更优 群体,从中全局并行搜索得到优化群体中最优个体
MySQL
代价模型
- 因为多表联接顺序采用贪心算法,多个表已经按照一定规则排序 (可访问元组数量升序排序)
- 所以MySQL认为,找到每个表的最小花费就是最终联接最小代价
贪心算法
贪心算法:认为每次连接表的连接方式都是最优的,即从未联接表中 选择使得下次联接代价最小者
多表排序一般为
- 常量表最前
- 其他表按可访问元组数量升序排序
贪心算法得到的联接方式都是最优的
- 则每次联接主要求解要联接表对象的最佳访问方式
- 即每次代价估计的重点在于单表扫描的代价
求解结束后,局部最优查询计划生成
- 得到左深树
- 最初始表位于最左下端叶子节点处
优化方案
以下分别从查询代价估计、多表连接顺序搜索算法给出方案
查询代价估计
考虑在现有代价模型上增加网络通信开销
在现有直方图估计选择率基础上,增加选择率估计方法
Parametric Method:参数方法,使用预先估计分布函数 逼近真实分布
Curve Fitting:曲线拟合法,使用多项式函数、最小 标准差逼近属性值分布
多表连接顺序搜索算法
考虑到动态规划算法随着联接表数量增加时,计算代价过于庞大, 可以考虑引入其他算法优化多表连接顺序
- 遗传算法
- 退火算法
- 贪心算法
- 遗传算法
- 退火算法
- 贪心算法