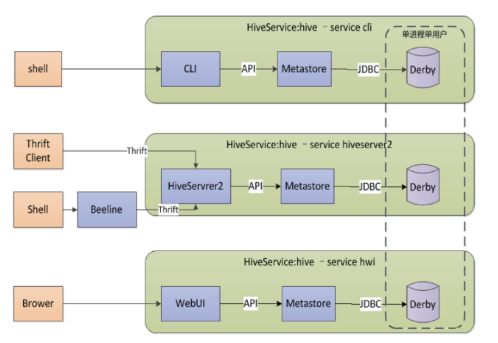
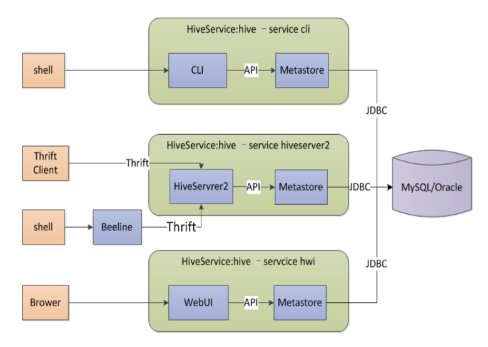
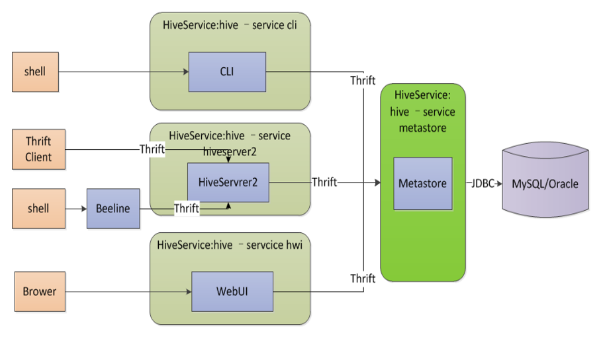
HiveSQL
命令行参数
-d/--define <key=value>:替换脚本中shell形式变量--hivevar <key=value>:替换脚本中shell形式变量- 结合hive脚本中设置shell变量使用
-h <hostname>:hive服务器-p <port>:hive服务器端口-database <database>:连接数据库-e <quoted-query-string>:从命令行获取、执行hive脚本-f <filename>:从文件获取、执行hive脚本-i <filename>:初始化hive脚本--hiveconf <property=value>:设置hive参数-S/--slient:安静模式启动交互hive shell-v/--verbose:详细模式-H/--help:帮助
辅助语句
结果输出
INSERT INTO/OVERWRITE:查询结果追加/覆盖在hive表中INSERT INTO/OVERWRITE [LOCAL] DIRECTORY:查询结果追加/ 覆盖本地/HDFS目录
- 有分区情况下,仅覆盖当前分区
内置函数
聚合函数
collect_set():配合group by合并、消除重复字段,返回arrayconcat_ws():连接字符串if(<condition>, <true_value>, <false_value>):判断条件size():返回array长度length():返回字符串大小
配置相关语句
文本分隔符
- 记录分隔:
\n - 字段分隔:
\001(八进制)ASCII码1字符 - Array、Struct、Map等集合中元素分隔:
\002ASCII码1字符 - Map中键值对分隔:
\003ASCII码1字符
1 | line terminated by `\n` |
空值
hive中空值一般有两种存储方式
NULL:底层存储NULL,查询显示为NULL\N:底层存储\N,查询显示为NULL,查询输出为\N
空值查询:
<field> is NULLNULL:也可<field> = 'NULL'\N:也可<field> = '\\N'(转义)
- 底层存储设置参见表存储
- 空字符串不是空值,需要用
<field> = ''查询
表存储配置
分区
属性
serdeproperties
设置空值存储方式
1
alter <table> SET serdeproperites('serialization.null.format' = '\N')