总述
支持向量机是二分类模型
学习要素
基本模型:定义在特征空间上的间隔最大线性分类器
学习策略:间隔最大化
学习算法:求解凸二次规划的最优化算法
数据
在给定特征空间上的训练数据集
$T={(x_1,y_1), (x_2,y_2),\cdots,(x_N,y_N)}$,其中
$x_i \in \mathcal{X} = R^n, y_i \in {-1, +1}, i=1,2,…,N$
- 输入空间:欧氏空间或离散集合
- 特征空间:希尔伯特空间
- 输出空间:离散集合
SVM假设输入空间、特征空间为两个不同空间,SVM在特征空间
上进行学习
线性(可分)支持向量机假设两个空间元素一一对应,并将
输入空间中的输入映射为特征空间中特征向量
非线性支持向量机利用,输入空间到特征空间的非线性映射
(核函数)将输入映射为特征向量
概念
Linear Support Vector Machine in Linearly Separable Case
线性可分支持向量机:硬间隔支持向量机,训练数据线性可分时,
通过硬间隔最大化策略学习
- 直观含义:不仅将正负实例分开,而且对于最难分的实例点
(离超平面最近的点),也有足够大的确信度将其分开,这样的
超平面对新实例预测能力较好
- Hard-margin Maximization:硬间隔最大化,最大化超平面
$(w,b)$关于线性可分训练数据集的两类样本集几何间隔
原始问题策略
最大间隔分离平面存在性
- 若训练数据集T线性可分,则可将训练数据集中样本点完全
正确分开的最大间隔分离超平面存在且唯一
存在性
- 训练数据集线性可分,所以以上中最优化问题一定存在可行解
- 又目标函数又下界,则最优化问题必有解
todo
- 又训练数据集中正、负类点都有,所以$(0,b)$必不是最优化
可行解
唯一性
若以上最优化问题存在两个最优解$(w_1^{},b_1^{})$、
$w_2^{},b_2^{}$
显然$|w_1^{}| = |w_2^{}| = c$,
$(w=\frac {w_1^{}+w_2^{}} 2,b=\frac {b_1^{}+b_2^{}} 2)$
使最优化问题的一个可行解,则有
则有$|w|=\frac 1 2 |w_1^{}|+\frac 1 2 |w_2^{}|$
,有$w_1^{} = \lambda w_2^{}, |\lambda|=1$
- $\lambda = -1$,不是可行解,矛盾
- $\lambda = 1$,则$w_1^{()} = w_2^{}$,两个最优解
写为$(w^{}, b_1^{})$、$(w^{}, b_2^{})$
设$x_1^{+}, x_1^{-}, x_2^{+}, x_2^{-}$分别为对应以上两组
超平面,使得约束取等号、正/负类别的样本点,则有
则有
又因为以上支持向量的性质可得
则有$w^{}(x_1^{+} - x_2^{+})=0$,同理有
$w^{}(x_1^{-} - x_2^{-})=0$
则$b_1^{} - b_2^{} = 0$
概念
Support Vector
支持向量:训练数据集中与超平面距离最近的样本点实例
- 在线性可分支持向量机中即为使得约束条件取等号成立的点
- 在决定分离超平面时,只有支持向量起作用,其他实例点不起
作用
- 支持向量一般很少,所以支持向量机由很少的“重要”训练样本
决定
间隔边界
间隔边界:超平面$wx + b = +/-1$
- 支持向量位于其上
- 两个间隔边界之间距离称为间隔$=\frac 2 {|w|}$
算法
- 输入:线性可分训练数据集T
- 输出:最大间隔分离超平面、分类决策函数
构造并求解约束最优化问题
得到最优解$w^{}, b^{}$
得到分离超平面
分类决策函数
多分类
1 vs n-1:对类$k=1,…,n$分别训练当前类对剩余类分类器
- 分类器数据量有偏,可以在负类样本中进行抽样
- 训练n个分类器
1 vs 1:对$k=1,…,n$类别两两训练分类器,预测时取各
分类器投票多数
- 需要训练$\frac {n(n-1)} 2$给分类器
DAG:对$k=1,…,n$类别两两训练分类器,根据预先设计的、
可以使用DAG表示的分类器预测顺序依次预测
- 即排除法排除较为不可能类别
- 一旦某次预测失误,之后分类器无法弥补
- 但是错误率可控
- 设计DAG时可以每次选择相差最大的类别优先判别
Dual Algorithm
对偶算法:求解对偶问题得到原始问题的最优解
- 对偶问题往往更容易求解
- 自然引入核函数,进而推广到非线性分类问题
对偶问题策略
求$\min_{w,b} L(w,b,\alpha)$,对拉格朗日函数求偏导置0
解得
将以上结果代理拉格朗日函数可得
以上函数对$\alpha$极大即为对偶问题,为方便改成极小
原始问题解
- 设$\alpha^{} = (\alpha_1^{}, \cdots, \alpha_N^{})$是
上述对偶优化问题的解,则存在$j \in [1, N]$使得
$\alpha_j^{} > 0$,且原始最优化问题解如下
分离超平面
则分离超平面为
分类决策函数为
即分类决策函数只依赖输入$x$和训练样本的内积
支持向量
- 将对偶最优化问题中,训练数据集中对应$\alpha_i^{*} > 0$
的样本点$(x_i, y_i)$称为支持向量
- 由KKT互补条件可知,对应$\alpha_i^{*} > 0$的实例$x_i$有即$(x_i, y_i)$在间隔边界上,同原始问题中支持向量定义一致
算法
- 输入:线性可分数据集$T$
- 输出:分离超平面、分类决策函数
构造并求解以上对偶约束最优化问题,求得最优解
$\alpha^{} = (\alpha_1^{},…,\alpha_N^{*})^T$
依据以上公式求$w^{}$,选取$\alpha^{}$正分量
$\alpha_j^{} > 0$计算$b^{}$
求出分类超平面、分类决策函数
Linear Support Vector Machine
线性支持向量机:训练数据线性不可分时,通过软间隔最大化策略
学习
- soft-margin maximization:软间隔最大化,最大化样本点
几何间隔时,尽量减少误分类点数量
策略
线性不可分的线性支持向量机的学习变成如下凸二次规划,即
软间隔最大化
- $\xi_i$:松弛变量
- $C > 0$:惩罚参数,由应用问题决定,C越大对误分类惩罚越大
- 对给定的线性不可分训练数据集,通过求解以上凸二次规划问题
得到的分类超平面 以及相应的分类决策函数 称为线性支持向量机
- 线性支持向量包括线性可分支持向量机
- 现实中训练数据集往往线性不可分,线性支持向量机适用性更广
对偶问题策略
原始问题的对偶问题
- 类似线性可分支持向量机利用Lagrange对偶即可得
原始问题解
- 设$\alpha^{} = (\alpha_1^{}, \cdots, \alpha_N^{})$是
上述对偶优化问题的解,则存在$j \in [1, N]$使得
$0 < \alpha_j^{} < C$,且原始最优化问题解如下
分离超平面
则分离超平面为
分类决策函数/线性支持向量机对偶形式
即分类决策函数只依赖输入$x$和训练样本的内积
支持向量
- 将对偶最优化问题中,训练数据集中对应$\alpha_i^{*} > 0$
的样本点$x_i$称为(软间隔)支持向量
- $\alpha_i^{*} < C$:则$\xi_i = 0$,恰好落在间隔边界上
- $\alpha_i^{*} = C, 0 < \xi_i < 1$:间隔边界与分离超平面
之间
- $\alpha_i^{*} = C, \xi=1$:分离超平面上
- $\alpha_i^{*} = C, \xi>1$:分离超平面误分一侧
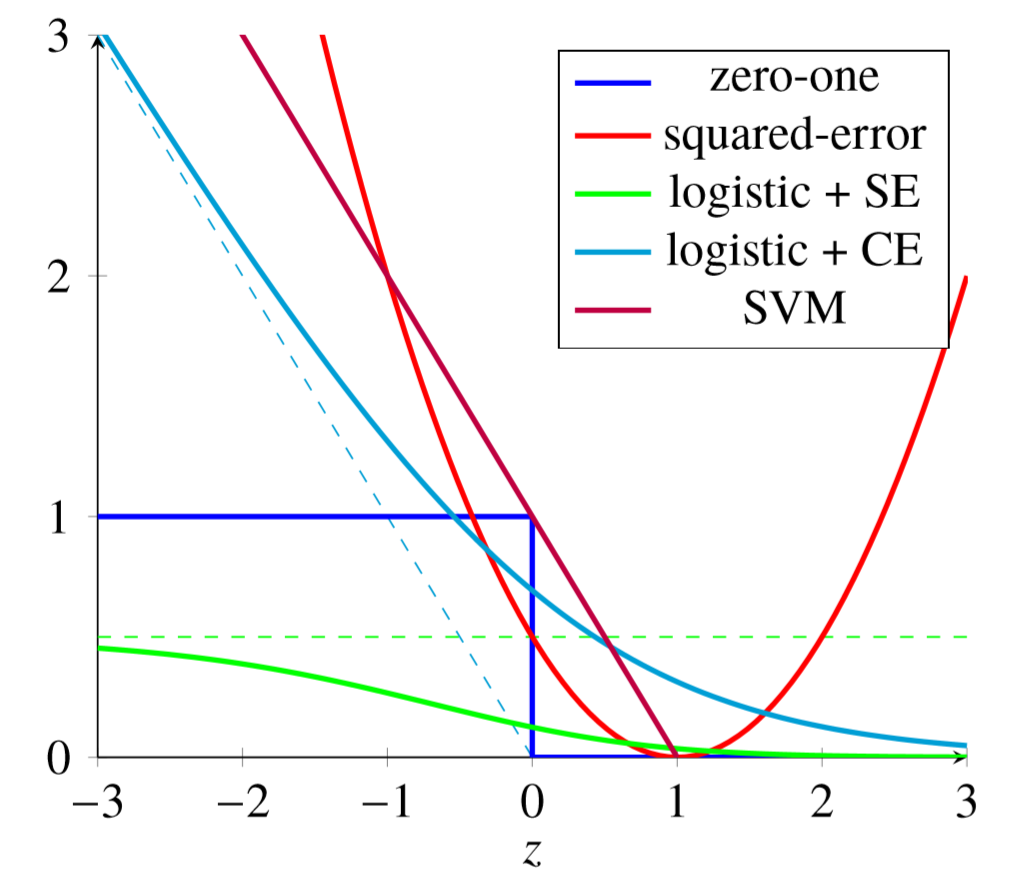
Hinge Loss
线性支持向量机策略还可以视为最小化以下目标函数
- $w$模越大,间隔越小,合页损失越小,所以用这个作为
正则化项是合理的
等价证明
令
Non-Linear Support Vector Machine
非线性支持向量机
非线性问题:通过非线性模型才能很好进行分类的问题
- 通过非线性变换$\phi(x)$,将输入空间映射到特征
空间(维数可能非常高)
- 原空间中非线性可分问题在特征空间可能变得线性可分,
在特征空间中学习分类模型
SVM求解非线性问题时
- kernel trick:通过非线性变换将输入空间对应一个特征
空间,使得输入空间中超曲面对应于特征空间的超平面模型
- 软间隔最大化策略:在特征空间中求解线性支持向量机
Kernal Trick
核技巧:线性SVM的对偶问题中,目标函数、决策函数均只涉及输入
实例、实例之间的内积
- 参见data_science/ref/functions
对偶问题目标函数
原始问题解
分类决策函数
算法
选取适当的核函数$K(x,z)$、适当参数C,构造求解最优化问题
求得最优解
$\alpha^{} = (\alpha_1^{},\alpha_2^{},\cdots,\alpha_N^{})$
选择$\alpha^{}$的一个正分量$0 < \alpha_j^{} < C$,计算
构造决策函数
- $K(x,z)$是正定核函数时,最优化问题是凸二次规划,有解
Sequential Minimal Optimization
序列最小最优化算法,主要解如下凸二次规划的对偶问题
- 凸二次规划有很多算法可以求得全局最优解,但是在训练样本
容量较大时,算法会很低效
思想
将原问题不断分解为子问题求解,进而求解原问题
如果所有变量的解都满足此优化问题的KKT条件,得到此最优化
问题的一个可能解
- 对凸二次规划就是最优解,因为凸二次规划只有一个稳定点
否则选择两个变量,固定其他变量,构建一个二次规划
不失一般性,假设选择两个变量$\alpha_1, \alpha_2$,其他
变量$\alpha_i(i=3,4,…,N)$是固定的,则SMO最优化子问题
- $K_{ij} = K(x_i, x_j), i,j=1,2,\cdots,N$
- $\zeta$:常数
两变量二次规划取值范围
由等式约束,$\alpha_1, \alpha_2$中仅一个自由变量,
不妨设为$\alpha_2$
设初始可行解为$\alpha_1, \alpha_2$
设最优解为$\alpha_1^{}, \alpha_2^{}$
未经剪辑(不考虑约束条件而来得取值范围)最优解为
$\alpha_2^{**}$
由不等式约束,可以得到$\alpha_2$取值范围$[L, H]$
$y_1 = y_2 = +/-1$时
$y_1 \neq y_2$时
- 以上取值范围第二项都是应用等式约束情况下,考虑
不等式约束
两变量二次规划求解
为叙述,记
- $g(x)$:SVM预测函数(比分类器少了符号函数)(函数间隔)
- $E_j$:SVM对样本预测与真实值偏差
- 以上两变量二次规划问题,沿约束方向未经剪辑解是 剪辑后的最优解是
变量选择
SMO算法每个子问题的两个优化变量,其中至少一个违反KKT条件
外层循环—首个变量选择
在训练样本中选择违反KKT条件最严重的样本点,将对应的变量作为
第一个变量$\alpha_1$
内层循环
第二个变量$\alpha_2$选择标准是其自身有足够大的变化,以加快
计算速度
更新阈值
算法
- 输入:训练数据集$T$,精度$\epsilon$
- 输出:近似解$\hat \alpha$
初值$\alpha^{(0)}$,置k=0
选取优化变量$\alpha_1^{(k)}, \alpha_2^{(k)}$,解析求解
两变量最优化问题得$\alpha_1^{(k+1)}, \alpha_2^{(k+2)}$,
更新$\alpha^{(k+1)}$
若在精度范围内满足停机条件(KKT条件)
则转4,否则置k=k+1,转2
取$\hat \alpha = \alpha^{(k+1)}$