identifier ::= xid_start xid_continue* id_start ::= <all characters in general categories Lu, Ll, Lt, Lm, Lo, Nl, the underscore, and characters with the Other_ID_Start property> id_continue ::= <all characters in id_start, plus characters in the categories Mn, Mc, Nd, Pc and others with the Other_ID_Continue property> xid_start ::= <all characters in id_start whose NFKC normalization is in "id_start xid_continue*"> xid_continue ::= <all characters in id_continue whose NFKC normalization is in "id_continue*">
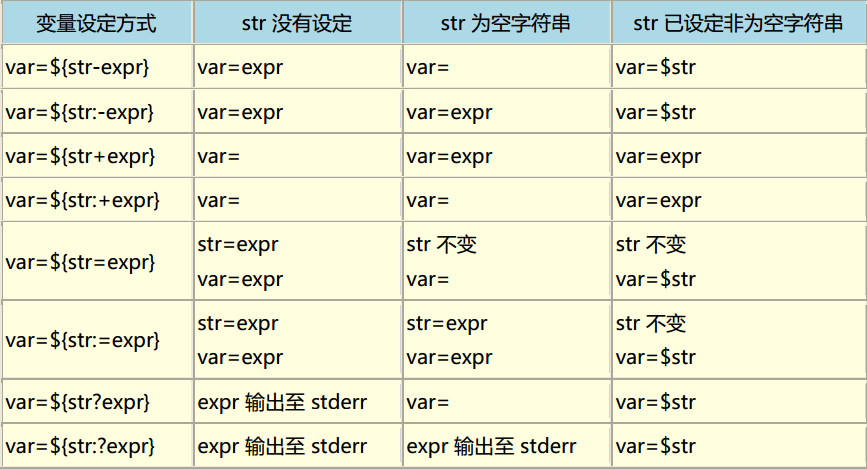
Lu:大写字母
Ll:小写字母
Lt:词首大写字母
Lm:修饰字母
Lo:其他字母
Nl:字母数字
Mn:非空白标识
Mc:含空白标识
Nd:十进制数字
Pc:连接标点
Other_ID_Start:由PropList.txt定义的显式字符列表,
用来支持向后兼容
Other_ID_Continue:同上
Keywords
关键字:以下标识符作为语言的保留字、关键字,不能用作普通
标识符
1 2 3 4 5 6 7
False await else import pass None break except in raise True class finally is return and continue for lambda try as def from nonlocal while assert del global not with async elif if or yield
fnmain(){ let favorite_color: Option<&str> = None; let is_tuesday = false; let age: Result<u8, _> = "34".parse();
ifletSome(color) = favorite_color{ //模式匹配 //注意这里是`=`而不是一般值比较`==` //`while`同 println!("favorite color is {}", color}; }elseif is_tuesday{ //普通`if`条件语句 println!("Tuesday is green day!"); }elseifletOk(age) = age{ //`age`变量覆盖原变量 //此时`age`是`u8`类型 if age > 30 { //因此此条件不能提出,因为两个`age`变量不同, //不能共存在同一条语句中 println!("Using purple as the background color"); }else{ println!("Using orange as the background color"); } }else{ println!("Using blue as the background color"); } }
let p = Point{x: 0, y: 7}; let Point{x: a, y: b} = p; //`Point{x: a, y: b}`是模式”Point结构体“ //解构结构体
let p = Point{x: 0, y: 7}; let Point{x, y} = p; //模式匹配解构结构体简写 //只要列出结构体字段,模式创建相同名称的变量
let p = Point{x: 0, y: 7}; match p { Point {x, y: 0} => println!("on the x axis at {}", x), Point {x: 0, y} => println!("on the y axis at {}", y), Point {x, y} => println!("on neither axis: ({}, {})", x, y), //这里没有`_`通配符,因为`Point {x, y}`模式已经 //是irrefutable,不需要 } }
let msg = Message::Hello { id: 5 }; match msg{ Message::Hello{ id: id_variable @ 3...7 } => { //匹配结构体模式(值绑定`id_variable`)&&值在`3...7`范围 println!("Found an id in range: {}", id_variable) }, Message::Hello{ id: 10...12 } => { //此分支模式指定了值的范围,但是没有绑定值给变量`id` //结构体匹配简略写法不能应用与此 println!("Found an id in another range") } Message::Hello{ id } => { //此分支结构体匹配简略写法,值绑定于`id` println!("Found some other id: {}", id) }, }
fnmain(){ let x = vec![1, 2, 3] let equal_to_x = move |z| z == x; println!("can't use x here: {:?}", x); //此时`x`的所有权已经转移进闭包,不能在闭包外使用 let y = vec![1, 2, 3]; assert!(equal_to_x(y));
use std::thread; use std::time:Duration; fnmain(){ let handle = thread::spawn(|| { //`thread::spawn`接受一个闭包作为参数,返回 //`JoinHandle`类型的值(不是引用) for i in1..10{ println!("number {} from spwaned thread!", i); thread::sleep(Duration::from_millis(1)); } );
for i in1..5{ println!("number{} from main thread!", i); thread::sleep(Duration::from_millis(1)); }
thread::spawn(move || {d let vals = vec![ String::from("move"), String::from("messages"), String::from("for"), String::from("you"), ]; for val in vals{ tx.send(val).unwrap(); thread::sleep(Duration::from_secs(1)); } });
let received = rx.recv().unwrap(); //`recv`将阻塞直到接收到一个值,返回`Result<T, E>` //通道发送端关闭时`recv`将返回`Err<E>`表明不会有新值
let received = rx.try_recv().unwrap(); //`try_recv`不阻塞,立刻返回`Result<T, E>`,`Err<E>` //表示当前没有消息 //可以再循环中多次调用`try_recv`,有消息进行处理, //否则进行其他工作直到下次调用`try_recv`
for received in rx{ //将接收端`rx`当作迭代器使用,返回接收到值 println!("Got: {}", received); } }
for _ in0..10{ let counter = Arc::clone(&counter); let handle = thread::spawn(move || { letmut num = counter.lock().unwrap(); //`lock`返回一个`MutexGuard`类型的智能指针, //实现了`Deref`指向其内部数据,`Drop`当 //`MutexGuard`离开作用域时自动释放锁
v <- c(2, 5.5, 6, 9) t <- c(8, 2.5, 14, 9) print (v > t) # 比较两个向量的相应元素,返回布尔值向量 print (v < t) print (v == t) print (v != t) print (v <= t) print (v >= t)
new.function_2 <- function(a, b, c){ # 有参数函数 result <- a * b + c print(result) } new.function_2(5, 3, 11) # 按参数顺序调用函数 new.function_2( a = 11, b = 5, c = 3) # 按参数名称调用
new.function_3 <- function(a=3, b=6){ # 含有默认参数函数 result <- a * b print(result) } new.function_3 # 无参数(使用默认参数) new.function_3(9, 5)