- Hadoop(核心):HDFS和MapReduce/YARN
- Hadoop家族:建立在Hadoop基础上的一系列开源工具

Hadoop
Hadoop时Apache的一个分布式计算、java语言实现的开源框架,
实现在大量计算机组成的集群中对海量数据进行分布式计算。相比于
依赖硬件的可靠性,Hadoop被设计为可以检测、处理应用层面的
failures,能够提供构建于电脑集群上的可靠服务。
Hadoop:Apache的分布式计算开源框架,提供分布式文件系统
HDFS、MapReduce/YARN分布式计算的软件架构
Hadoop Common
支持其它Hadoop模块的公用组件
Hadoop Distributed File System(HDFS)
虚拟文件系统,让整个系统表面上看起来是一个空间,实际上是很多
服务器的磁盘构成的
Hadoop YARN
Yet Another Resource Negotiator,通用任务、集群资源分配框架
,面向Hadoop的编程模型
YARN将classic/MapReduce1中Jobtracker职能划分为多个独立
实体,改善了其面临的扩展瓶颈问题
YARN比MapReduce更具一般性,MapReduce只是YARN应用的一种
形式,可以运行Spark、Storm等其他通用计算框架
YARN精妙的设计可以让不同的YARN应用在同一个集群上共存,
如一个MapReduce应用可以同时作为MPI应用运行,提高可管理性
和集群利用率
Hadoop MapReduce
YARN基础上的大数据集并行处理系统(框架)
Apache下Hadoop相关项目
高频
Ambari
用于部署(供应)、管理、监控Hadoop集群的Web工具
支持HDFS、MapReduce、Hive、HCatalog、HBase、
Oozie、ZooKeeper、Pig、Sqoop
提供dashboard用于查看集群健康程度,如:热度图
能够直观的查看MapReduce、Pig、Hive应用特点,提供
易用的方式考察其执行情况
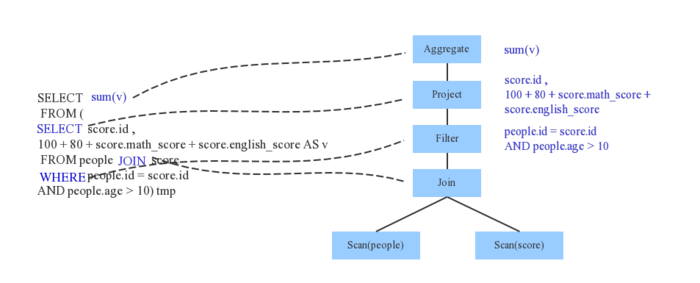
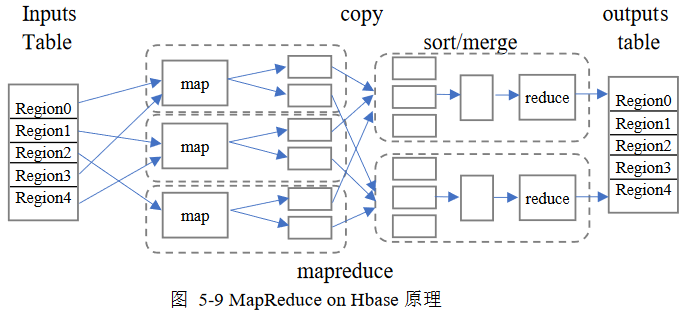
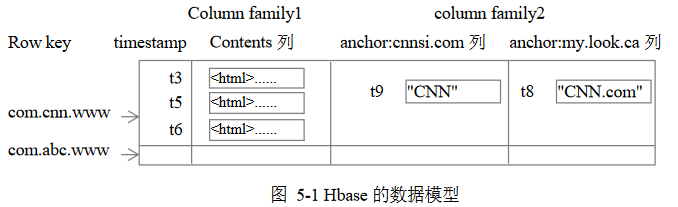
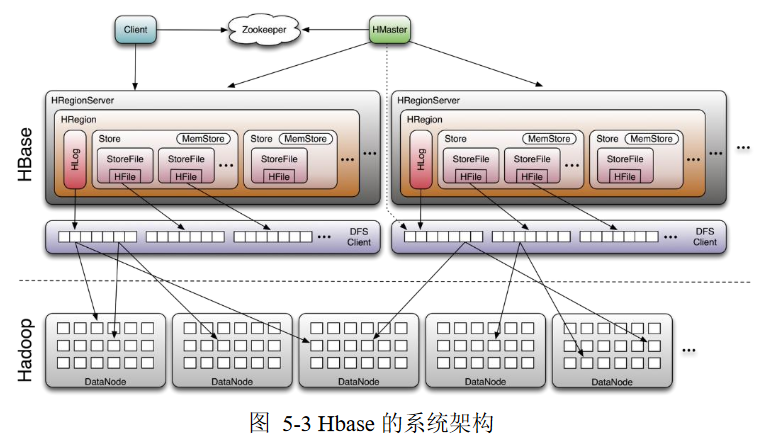
HBase
Hadoop项目子项目,高可靠、高性能、面向列、可伸缩的分布式
存储系统
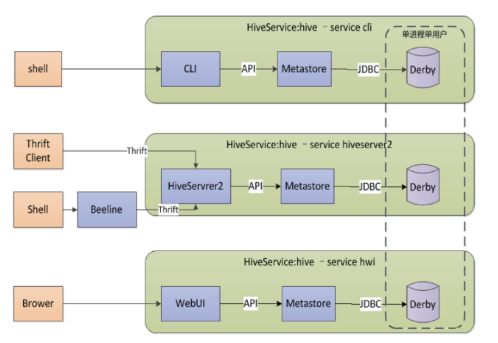
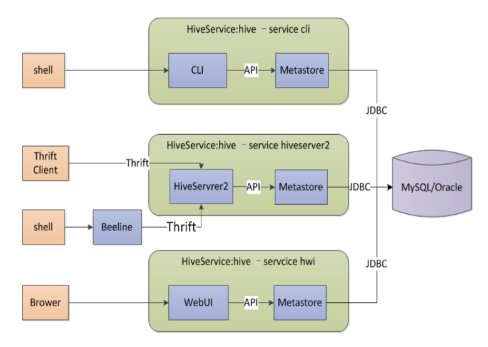
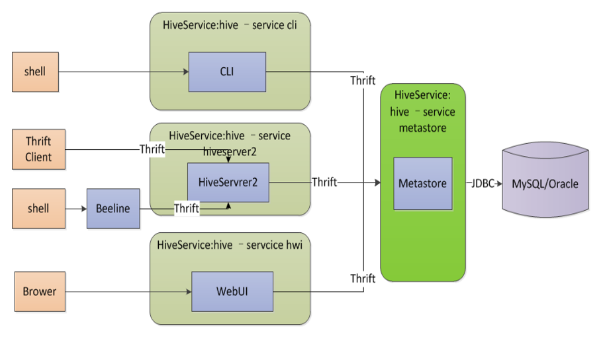
Hive
基于Hadoop的数据仓库工具
Pig
基于Hadoop的大规模数据高层分析工具(类似于Hive)
Zookeeper
Hadoop正式子项目,针对大型分布式应用设计的分布式、开源协调
系统
Spark
基于内存计算的开源集群计算系统,目的是让数据分析更加快速
低频
Mahout
基于Hadoop的机器学习、数据挖掘的分布式框架
Cassandra
开源分布式NoSQL数据库系统,最初由Facebook开发,用于存储
简单格式数据,集Google BigTable数据模型和Amazon Dynamo
的完全分布式架构于一身
Avro
数据序列化系统,设计用于支持数据密集型、大批量数据交换应用,
是新的数据序列化格式、传输工具,将逐步取代Hadoop原有的
IPC机制
Chukwa
用于监控大型分布式系统的开源数据收集系统,可以将各种类型的
数据收集成适合Hadoop处理的文件,保存在HDFS中供MapReduce
操作
Tez
基于YARN的泛用数据流编程平台
- 提供强力、灵活的引擎用于执行任何DAG任务,为批处理和
交互用例处理数据
Tez正逐渐被Hive、Pig等Hadoop生态框架采用,甚至被一些
商业公司用于替代MapReduce作为底层执行引擎
其他Hadoop相关项目
高频
Sqoop
用于将Hadoop和关系型数据库中数据相互转移的开源工具
Impala
由Cloudera发布的实时查询开源项目
Phoenix
apache顶级项目,在HBase上构建了一层关系型数据库,可以用
SQL查询HBase数据库,且速度比Impala更快,还支持包括
二级索引在内的丰富特性,借鉴了很多关系型数据库优化查询方法
Oozie
工作流引擎服务器,用于管理、协调运行在Hadoop平台
(HDFS、Pig、MapReduce)的任务
Cloudera Hue
基于Web的监控、管理系统,实现对HDFS、MapReduce/YARN、
HBase、Hive、Pig的Web化操作和管理
低频
Hama
基于HDFS的BSP(Bulk Synchronous Parallel)并行
计算框架,可以用包括图、矩阵、网络算法在内的大规模、
大数据计算
Flume
分布的、可靠的、高可用的海量日志聚合系统,可用于日志数据
收集、处理、传输
Giraph
基于Hadoop的可伸缩的分布式迭代图处理系统,灵感来自于BSP和
Google Pregel
Crunch
基于Google FlumeJava库编写的Java库,用于创建MapReduce
流水线(程序)
Whirr
运行于云服务的类库(包括Hadoop),提供高度互补性
- 相对中立
- 支持AmazonEC2和Rackspace的服务
Bigtop
对Hadoop及其周边生态打包、分发、测试的工具
HCatalog
基于Hadoop的数据表、存储管理,实现中央的元数据、模式管理,
跨越Hadoop和RDBMS,利用Pig、Hive提供关系视图
Llama
让外部服务器从YARN获取资源的框架
非CDH组件
Fuse
让HDFS系统看起来像普通文件系统
Hadoop Streamin
MapReduce代码其他语言支持,包括:C/C++、Perl、Python
、Bash等