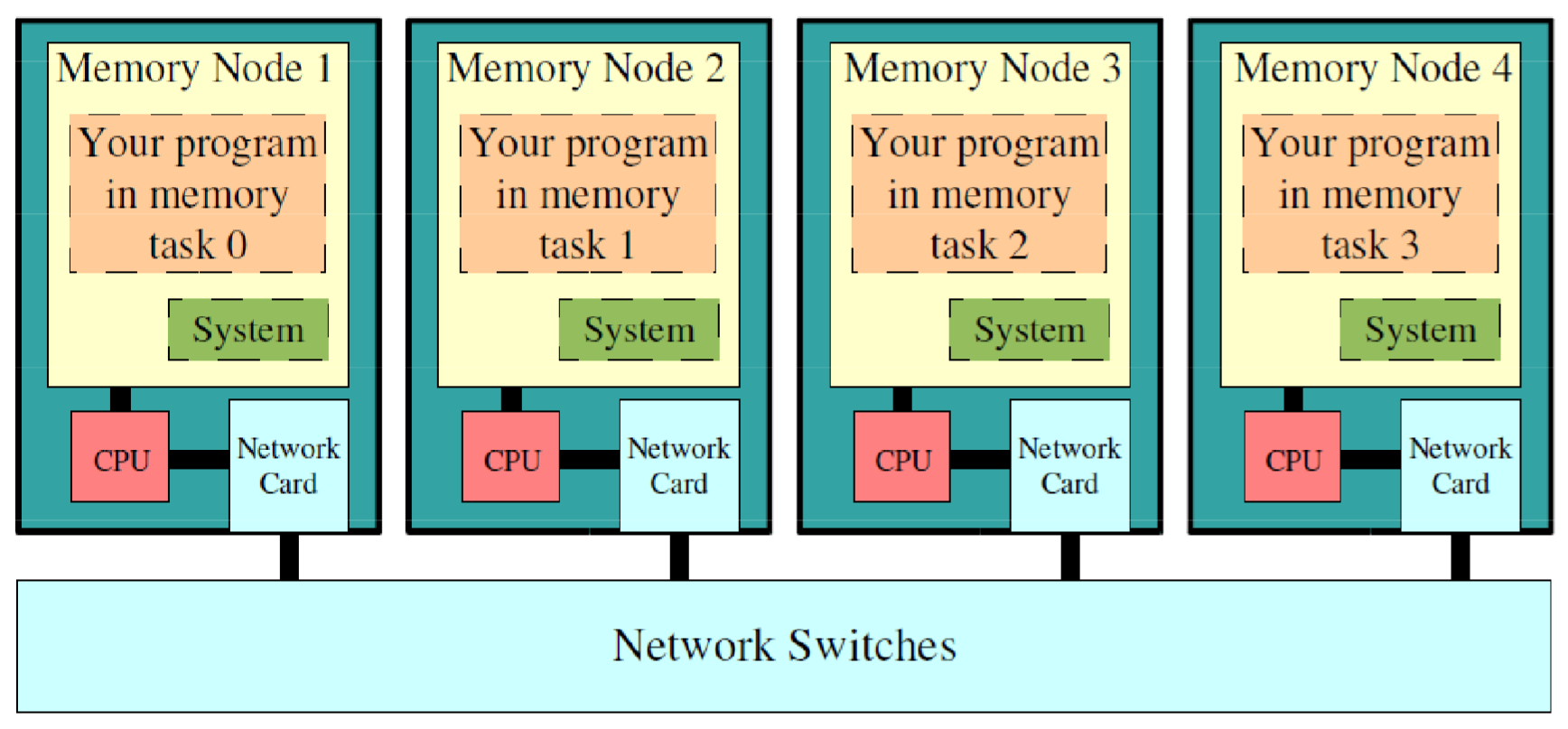
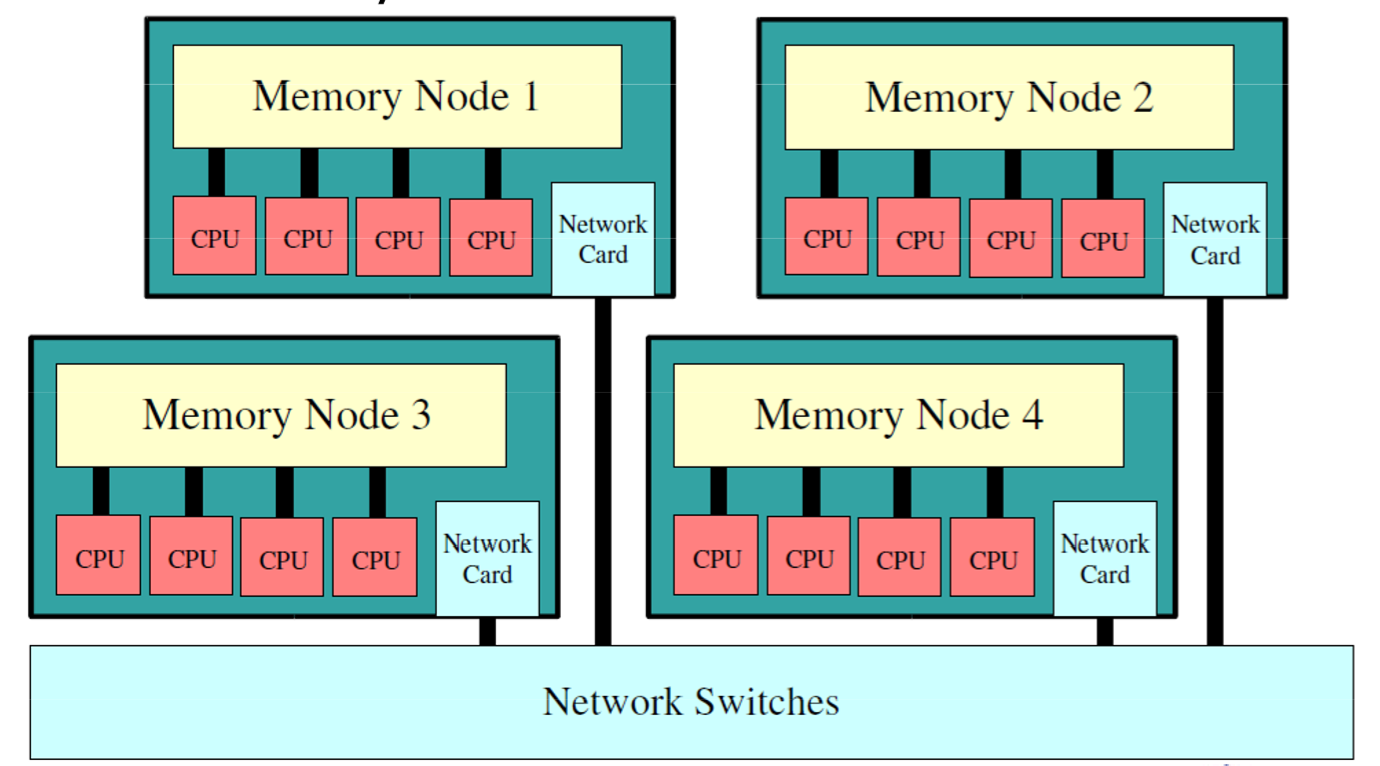
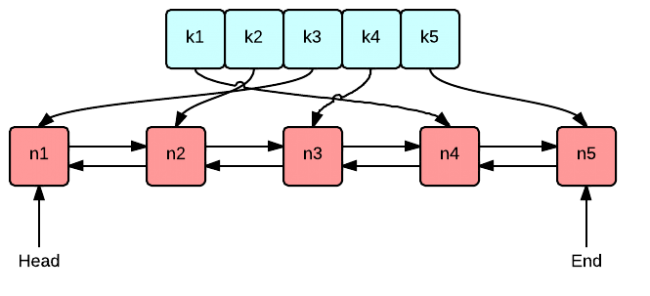
语言设计
编程范型
Functional Programming
函数式编程:使用纯函数
- 程序使用紧密的函数调用表示,这些函数可以进行必要计算, 但是不会执行会改变程序状态(如:赋值)的操作
- 函数就是数据值,可以像对待其他数据值一样对其进行操作
纯函数
纯函数:没有副作用、表达式对所有引用透明度表达式也是引用透明 的函数
- 执行过程中除了根据输入参数给出运算结果外没有其他影响
- 输入完全由输入决定,任何内部、外部过程的状态改变不会影响 函数执行结果
- reference transparency:引用透明,表达式可以用其结果 取代而不改变程序含义
语言基础
错误类型
- trapped errors:导致程序终止执行错误
- 除0
- Java中数组越界访问
- untrapped errors:出错后程序继续执行,但行为不可预知, 可能出现任何行为
- C缓冲区溢出、Jump到错误地址
程序行为
- forbidden behaviours:语言设计时定义的一组行为,必须 包括untrapped errors,trapped errors可选
- undefined behaviours:未定义为行为,C++标准没有做出 明确规定,由编译器自行决定
- well behaved:程序执行不可能出现forbidden behaviors
- ill behaved:否则
语言类型
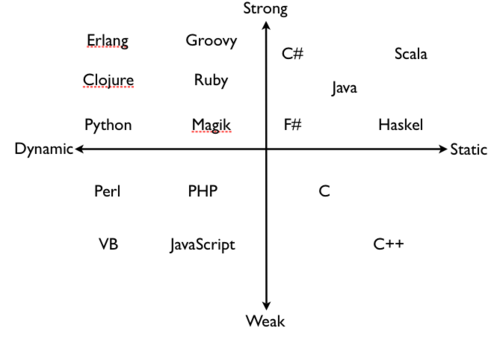
- strongly typed:强类型,偏向于不能容忍隐式类型转换
- weakly typed:弱类型,偏向于容忍隐式类型转换
- statically typed:静态类型,编译时就知道每个变量类型, 因为类型错误而不能做的事情是语法错误
- dynamically typed:动态类型,编译时不知道每个变量类型 ,因为类型错误而不能做的事情是运行时错误
静态类型语言不定需要声明变量类型
- explicitly typed:显式静态类型,类型是语言语法的 一部分,如:C
- implicitly typed:隐式静态类型,类型由编译时推导 ,如:ML、OCaml、Haskell
类型绑定
- 强类型倾向于值类型,即类型和值绑定
- 弱类型倾向于变量类型,类型和变量绑定,因而偏向于 容忍隐式类型转换
polymorphism
多态:能将相同代码应用到多种数据类型上方式
- 相同对象收到不同消息、不同对象收到相同消息产生不同动作
Ad hoc Polymorphism:
ad hoc polymorphism:接口多态,为类型定义公用接口
- 函数重载:函数可以接受多种不同类型参数,根据参数类型有 不同的行为
- ad hoc:for this, 表示专为某特定问题、任务设计的解决 方案,不考虑泛用、适配其他问题
Parametric Polymorphism
parametric polymorphism:参数化多态,使用抽象符号代替具体 类型名
定义数据类型范型、函数范型
参数化多态能够让语言具有更强表达能力的同时,保证类型安全
- 例
- C++:函数、类模板
- Rust:trait bound
- 在函数式语言中广泛使用,被简称为polymorphism
Subtyping
subtyping/inclsion polymorphism:子类多态,使用基类实例 表示派生类
子类多态可以用于限制多态适用范围
子类多态一般是动态解析的,即函数地址绑定时间
- 非多态:编译期间绑定
- 多态:运行时绑定
例
- C++:父类指针
- Rust:trait bound
变量设计
Lvalue、Rvalue
- lvalue:location value,可寻址
- rvalue:readable value,可读取
左值:引用内存中能够存储数据的内存单元的表达式
- 使用表达式在内存中位置
- 考虑其作为对象的身份
右值:非左值表达式
- 使用表达式的值
- 考虑其作为对象的内容
- 左值、右值最初源自C
- 左值:可以位于赋值运算符
=左侧的表达式- 右值:不可以位于赋值运算赋
=左侧的表达式
左值
- 任何左值都存储在内存中,所以都有一个地址
- 左值声明后,地址不会改变,地址中存储的内容可能发生 改变
- 左值的地址是一个指针值,可以被存储在内存中的、像数据 一样被修改
特点
重要原则
- 多数情况下,需要右值处可使用左值替代
- 需要左值处不能用右值替代
重要特点
- 左值存在在变量中,有持久的状态
- 右值常为字面常量、表达式求职过程中创建的临时对象, 没有持久状态
一等对象
一等对象:满足以下条件的程序实体
- 在运行时创建
- 能赋值给变量、数据结构中的元素
- 能作为参数传递给函数
- 能作为函数返回结果
高阶函数
高阶函数:以其他函数作为参数、返回函数作为结果的函数
短路求值
短路求值:布尔运算and/or中若结果已经确定,则不继续计算之后 表达式
x and y:首先对x求值- 若
x为假停止计算 - 否则继续对
y求值再判断
- 若
x or y:首先对x求值- 若
x为真则停止计算 - 否则继续对
y求值再判断
- 若
- 返回值取决于语言实现
- 确定返回布尔值:C/C++
- 返回
x、或y的求值结果:python