NLP 总述
文本挖掘
文本处理:将非结构化数据转换为结构化数据
预测建模
- 文本分类:根据观察到的对象特征值预测其他特征值
描述建模
- 文本聚类:对数据对象进行概括,以看到数据对象的最重要
特征
- 适应范围非常广
- 聚类分析
- 文本聚类:对数据对象进行概括,以看到数据对象的最重要
特征
基于相似度方法
- 需要用户显式指定相似度函数
- 聚类算法根据相似度的计算结果将相似文本分在同一个组
- 每个文本只能属于一个组,因此也成为“硬聚类”
基于模型的方法
- 文本有多个标签,也成为“软聚类”
话题检测
找出文档中的K个话题,计算每个文档对话题的覆盖率
话题表示方法
基于单个词
基于词分布
问题描述
- 输入
- N个文档构成的文本集C
- 话题个数K
- 词典V
- 输出
- K个话题的分布 $(\theta_1, \theta2, \cdots, \theta_K)$
- N个文档在K个话题上的概率分布 $(\pi_1, \pi_2, \cdots, \pi_N)$
语言模型
词向量:将向量表示词
1-of-N representation/one hot representation:one-hot 表示词
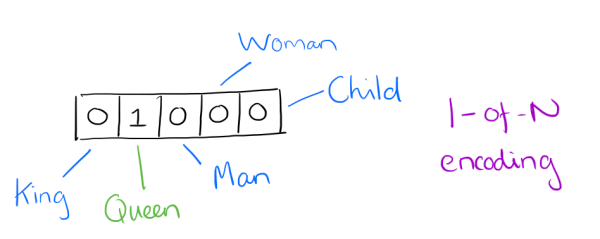
- 词向量维度为整个词汇表大小
- 简单、效率不高
distributed representation:embedding思想,通过训练, 将词映射到较短词向量中
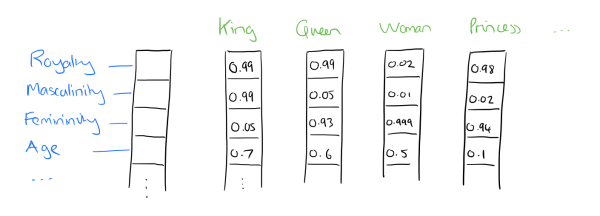
- 词向量维度自定义
- 容易分析词之间关系
Continuous Bag-of-Words
CBOW:输入特征词上下文相关词对应词向量,输出特征词的词向量
- CBOW使用词袋模型
- 特征词上下文相关从平等,不考虑和关注的词之间的距离
Skip-Gram
Skip-Gram:输入特征词词向量,输出softmax概率靠前的词向量
神经网络词向量
神经网络词向量:使用神经网络训练词向量
一般包括三层:输入层、隐层、输出softmax层
从隐藏层到输出softmax层计算量很大
- 需要计算所有词的softmax概率,再去找概率最大值