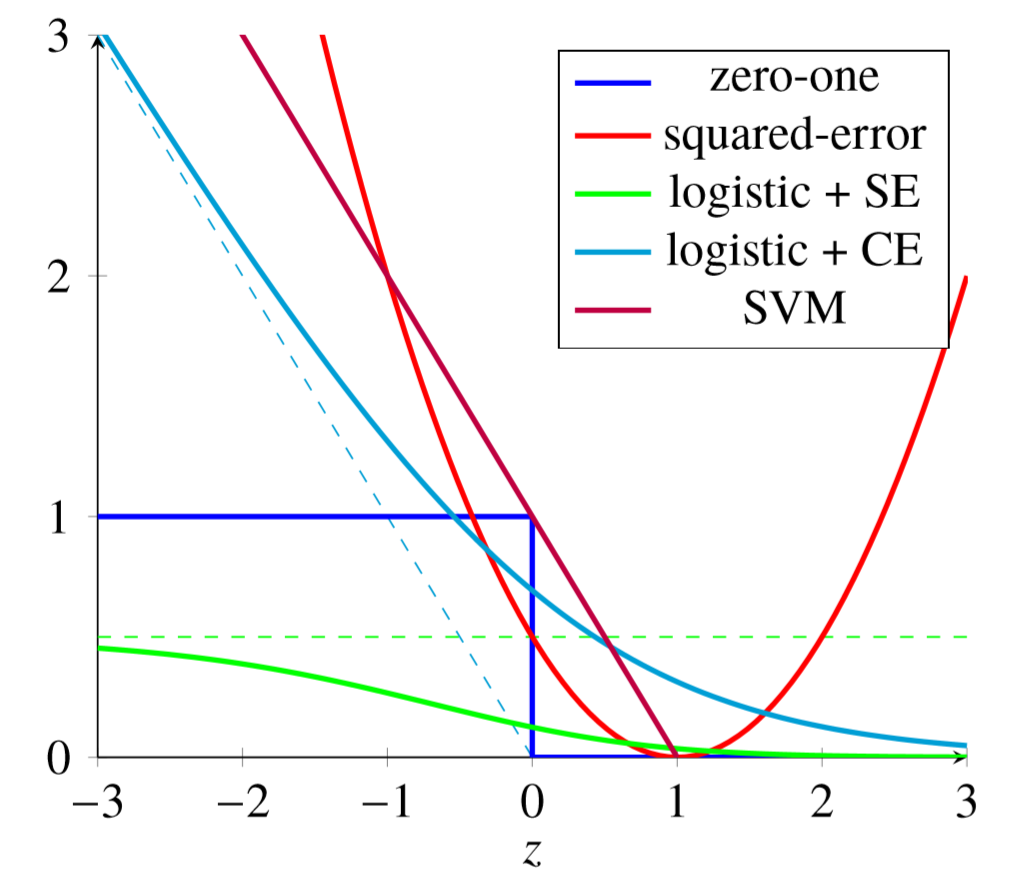
最大熵模型
逻辑斯蒂回归
逻辑斯蒂分布
- $\mu$:位置参数
- $\gamma$:形状参数
- 分布函数属于逻辑斯蒂函数
分布函数图像为sigmoid curve
- 关于的$(\mu, \frac 1 2)$中心对称
- 曲线在靠近$\mu$中心附近增长速度快,两端速度增长慢
- 形状参数$\gamma$越小,曲线在中心附近增加越快
模型优点
- 模型输出值位于0、1之间,天然具有概率意义,方便观测 样本概率分数
- 可以结合$l-norm$正则化解决过拟合、共线性问题
- 实现简单,广泛用于工业问题
- 分类时计算量比较小、速度快、消耗资源少
模型缺点
- 特征空间很大时,性能不是很好,容易欠拟合,准确率一般
- 对非线性特征需要进行转换
Binomial Logistic Regression Model
二项逻辑斯蒂回归模型:形式为参数化逻辑斯蒂分布的二分类 生成模型
- $w, b$:权值向量、偏置
- $\hat x = (x^T|1)^T$
- $\hat w = (w^T|b)^T$
逻辑回归比较两个条件概率值,将实例$x$归于条件概率较大类
通过逻辑回归模型,可以将线性函数$wx$转换为概率
- 线性函数值越接近正无穷,概率值越接近1
- 线性函数值越接近负无穷,概率值越接近0
Odds/Odds Ratio
在逻辑回归模型中,输出$Y=1$的对数几率是输入x的线性函数
OR在逻辑回归中意义:$x_i$每增加一个单位,odds将变为原来 的$e^{w_i}$倍
对数值型变量
- 多元LR中,变量对应的系数可以计算相应 Conditional OR
- 可以建立单变量LR,得到变量系数及相应 Marginal OR
对分类型变量
- 可以直接计算变量各取值间对应的OR
- 变量数值化编码建立模型,得到变量对应OR
- 根据变量编码方式不同,变量对应OR的含义不同,其中 符合数值变量变动模式的是WOE线性编码
策略
极大似然:极小对数损失(交叉熵损失)
- $\pi(x) = P(Y=1|x)$
算法
- 通常采用梯度下降、拟牛顿法求解有以上最优化问题
Multi-Nominal Logistic Regression Model
多项逻辑斯蒂回归:二项逻辑回归模型推广
- 策略、算法类似二项逻辑回归模型
Generalized Linear Model
todo
Maximum Entropy Model
最大熵原理
最大熵原理:学习概率模型时,在所有可能的概率模型(分布)中, 熵最大的模型是最好的模型
使用约束条件确定概率模型的集合,则最大熵原理也可以表述为 在满足约束条件的模型中选取熵最大的模型
直观的,最大熵原理认为
- 概率模型要满足已有事实(约束条件)
- 没有更多信息的情况下,不确定部分是等可能的
- 等可能不容易操作,所有考虑使用可优化的熵最大化 表示等可能性
最大熵模型
最大熵模型为生成模型
对给定数据集$T={(x_1,y_1),\cdots,(x_N,y_N)}$,联合分布 P(X,Y)、边缘分布P(X)的经验分布如下
- $v(X=x,Y=y)$:训练集中样本$(x,y)$出频数
用如下feature function $f(x, y)$描述输入x、输出y之间 某个事实
特征函数关于经验分布$\tilde P(X, Y)$的期望
特征函数关于生成模型$P(Y|X)$、经验分布$\tilde P(X)$ 期望
期望模型$P(Y|X)$能够获取数据中信息,则两个期望值应该相等
此即作为模型学习的约束条件
此约束是纯粹的关于$P(Y|X)$的约束,只是约束形式特殊, 需要通过期望关联熵
若有其他表述形式、可以直接带入的、关于$P(Y|X)$约束, 可以直接使用
- 满足所有约束条件的模型集合为 定义在条件概率分布$P(Y|X)$上的条件熵为 则模型集合$\mathcal{C}$中条件熵最大者即为最大是模型
策略
最大熵模型的策略为以下约束最优化问题
引入拉格朗日函数
原始问题为
对偶问题为
考虑拉格朗日函数$L(P, w)$是P的凸函数,则原始问题、 对偶问题解相同
记
求$L(P, w)$对$P(Y|X)$偏导
偏导置0,考虑到$\tilde P(x) > 0$,其系数必始终为0,有
考虑到约束$\sum_y P(y|x) = 1$,有
- $Z_w(x)$:规范化因子
- $f(x, y)$:特征
- $w_i$:特征权值
原最优化问题等价于求解偶问题极大化问题$\max_w \Psi(w)$
记其解为
带入即可得到最优(最大熵)模型$P_{w^{*}}(Y|X)$
策略性质
已知训练数据的经验概率分布为$\tilde P(X,Y)$,则条件概率 分布$P(Y|X)$的对数似然函数为
- 这里省略了系数样本数量$N$
将最大熵模型带入,可得
对偶函数$\Psi(w)$等价于对数似然函数$L_{\tilde P}(P_w)$, 即最大熵模型中,对偶函数极大等价于模型极大似然估计
改进的迭代尺度法
思想
- 假设最大熵模型当前参数向量$w=(w_1,w_2,\cdots,w_M)^T$
- 希望能找到新的参数向量(参数向量更新) $w+\sigma=(w_1+\sigma_1,\cdots,w_M+\sigma_M)$ 使得模型对数似然函数/对偶函数值增加
- 不断对似然函数值进行更新,直到找到对数似然函数极大值
对给定经验分布$\tilde P(x,y)$,参数向量更新至$w+\sigma$ 时,对数似然函数值变化为
不等式步利用$a - 1 \geq log a, a \geq 1$
最后一步利用
记上式右端为$A(\sigma|w)$,则其为对数似然函数改变量的 一个下界
- 若适当的$\sigma$能增加其值,则对数似然函数值也应该 增加
- 函数$A(\sigma|w)$中因变量$\sigma$为向量,难以同时 优化,尝试每次只优化一个变量$\sigma_i$,固定其他变量 $\sigma_j$
记
考虑到$f_i(x,y)$为二值函数,则$f^{**}(x,y)$表示所有特征 在$(x,y)$出现的次数,且有
考虑到$\sum_{i=1}^M \frac {f_i(x,y)} {f^{**}(x,y)} = 1$, 由指数函数凸性、Jensen不等式有
则
记上述不等式右端为$B(\sigma|w)$,则有
其为对数似然函数改变量的一个新、相对不紧的下界
求$B(\sigma|w)$对$\sigma_i$的偏导
置偏导为0,可得
其中仅含变量$\sigma_i$,则依次求解以上方程即可得到 $\sigma$
算法
- 输入:特征函数$f_1, f_2, \cdots, f_M$、经验分布 $\tilde P(x)$、最大熵模型$P_w(x)$
- 输出:最优参数值$wi^{*}$、最优模型$P{w^{*}}$
对所有$i \in {1,2,\cdots,M}$,取初值$w_i = 0$
对每个$i \in {1,2,\cdots,M}$,求解以上方程得$\sigma_i$
若$f^{**}(x,y)=C$为常数,则$\sigma_i$有解析解
若$f^{**}(x,y)$不是常数,则可以通过牛顿法迭代求解
- $g(\sigma_i)$:上述方程对应函数
- 上述方程有单根,选择适当初值则牛顿法恒收敛
更新$w_i$,$w_i \leftarrow w_i + \sigma_i$,若不是所有 $w_i$均收敛,重复2
BFGS算法
对最大熵模型
为方便,目标函数改为求极小
梯度为
算法
将目标函数带入BFGS算法即可
- 输入:特征函数$f_1, f_2, \cdots, f_M$、经验分布 $\tilde P(x)$、最大熵模型$P_w(x)$
- 输出:最优参数值$wi^{*}$、最优模型$P{w^{*}}$
取初值$w^{(0)}$、正定对称矩阵$B^{(0)}$,置k=0
计算$g^{(k)} = g(w^{(k)})$,若$|g^{(k)}| < \epsilon$, 停止计算,得到解$w^{*} = w^{(k)}$
由拟牛顿公式$B^{(k)}p^{(k)} = -g^{(k)}$求解$p^{(k)}$
一维搜索,求解
置$w^{(k+1)} = w^{(k)} + \lambda^{(k)} p_k$
计算$g^{(k+1)} = g(w^{(k+1)})$,若 $|g^{(k+1)}| < \epsilon$,停止计算,得到解 $w^{*} = w^{(k+1)}$,否则求
- $s^{(k)} = w^{(k+1)} - w^{(k)}$
- $y^{(k)} = g^{(k+1)} - g^{(k)}$
置k=k+1,转3