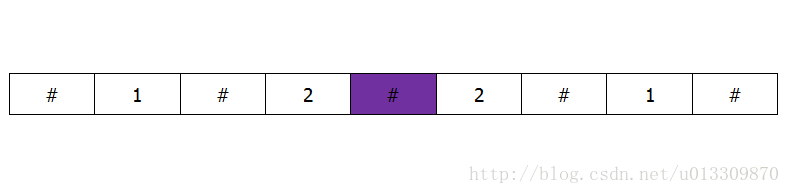# 开启交互式Session sess = tf.InteractiveSession() a = tf.constant(5.0) b = tf.constant(6.0) c = a * b x = tf.Variable([1.0, 2.0]) # 无需显式在`sess.run`中执行 # 直接调用`OPs.eval/run()`方法得到结果 x.initializer.run() print(c.eval()) sess.close()
import tensorflow as tf import tensorflow.contrib.eager as tfe # 启用TF eager execution tfe.enable_eager_execution()
优势
支持python debug工具
提供实时报错
支持python数据结构
支持pythonic的控制流
1 2 3
i = tf.constant(0) whlile i < 1000: i = tf.add(i, 1)
eager execution开启后
tensors行为类似np.ndarray
大部分API和未开启同样工作,倾向于使用
tfe.Variable
tf.contrib.summary
tfe.Iterator
tfe.py_func
面向对象的layers
需要自行管理变量存储
eager execution和graph大部分兼容
checkpoint兼容
代码可以同时用于python过程、构建图
可使用@tfe.function将计算编译为图
示例
placeholder、sessions
1 2 3 4 5 6 7 8 9
# 普通TF x = tf.placholder(tf.float32, shape=[1, 1]) m = tf.matmul(x, x) with tf.Session() as sess: m_out = sess.run(m, feed_dict={x: [[2.]]})
# Eager Execution x = [[2.]] m = tf.matmul(x, x)
Lazy loading
1 2 3 4 5
x = tf.random_uniform([2, 2]) for i inrange(x.shape[0]): for j inrange(x.shape[1]): # 不会添加多个节点 print(x[i, j])
Device
设备标识
设备标识:设备使用字符串进行标识
/cpu:0:所有CPU都以此作为名称
/gpu:0:第一个GPU,如果有
/gpu:1:第二个GPU
1 2 3 4 5 6
# 为计算指定硬件资源 with tf.device("/gpu:2"): a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0], name="a") b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0], name="b") c = tf.multiply(a, b) # creates a graph
if(<eva_expr>){ // code-block if true }elseif(<eva_expr>){ // code-block }else{ // code-block if false }
返回值:对应函数块返回值
while语句
1 2 3
while(<eva_expr>){ // code-block if true }
Scala中while作用被弱化、不推荐使用
返回值:始终为Unit类型()
for语句
1 2 3 4 5 6 7
for{ <item1> <- <iter1> <item2> <- <iter2> if <filter_exp> if <filter_exp> }{ }
以上在同语句中多个迭代表达式等价于嵌套for
返回值
默认返回Unit类型()
配合yield返回值迭代器(元素会被消耗)
注意:迭代器中元素会被消耗,大部分情况不应该直接在嵌套
for语句中使用
match模式匹配
模式匹配的候选模式
常量
构造函数:解构对象
需伴生对象实现有unapply方法,如:case class
序列
需要类伴生对象实现有unapplySeq方法,如:
Seq[+A]类、及其子类
元组
类型:适合需要对不同类型对象需要调用不同方法
一般使用类型首字母作为case标识符name
对密封类,无需匹配其他任意情况的case
不匹配可以隐式转换的类型
变量绑定
候选模式可以增加pattern guards以更灵活的控制程序
模式匹配可以视为解构已有值,将解构结果map至给定名称
可以用于普通赋值语句中用于解构模式
显然也适合于for语句中模式匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
<target> match { // 常量模式 + 守卫语句 case x if x % 2 == 0 => // 构造函数模式 caseDog(a, b) => // 序列模式 caseArray(_, second) => // 元组模式 case (second, _*) => // 类型模式 case str: String => // 变量绑定 case all@Dog(name, _) => }
// 普通赋值语句中模式匹配 val all@Array(head, _*) = Array(1,3,3)
// 实例化`Function2[T1, T2, T3]`创建函数 val sum = newFunction2[Int, Int, Int] { defapply(x: Int, y: Int): Int = x + y } val sum = (x: Int, y: Int) => x + y
偏函数
偏函数:只处理参数定义域中子集,子集之外参数抛出异常
1 2 3 4 5 6 7 8 9 10 11
// scala中定义 traitPartialFunction[-A, +B] extends (A => B){ // 判断元素在偏函数处理范围内 defisDefinedAt(?ele: A) // 组合多个偏函数 deforElse(?pf: PartialFunction[A, B]) // 方法的连续调用 defaddThen(?pf: PartialFunction[A, B]) // 匹配则调用、否则调用回调函数 defapplyOrElse(?ele: A, ?callback: Function1[B, Any]) }
偏函数实现了Function1特质
用途
适合作为map函数参数,利用模式匹配简化代码
1 2 3 4 5
val receive: PartialFunction[Any, Unit] = { case x: Int => println("Int type") case x: String => println("String type") case _ => println("other type") }
Methods
方法:表现、行为类似函数,但有关键差别
def定义方法,包括方法名、参数列表、返回类型、方法体
方法可以接受多个参数列表、没有参数列表
1 2 3
defaddThenMutltiply(x: Int, y: Int)(multiplier: Int): Int = (x+y) * multiplier
defname: String = System.getProperty("user.name")
Scala中可以嵌套定义方法
Java中全在类内,确实都是方法
Currying
柯里化:使用较少的参数列表调用多参数列表方法时会产生新函数,
该函数接受剩余参数列表作为其参数
多参数列表/参数分段有更复杂的调用语法,适用场景
给定部分参数列表
可以尽可能利用类型推断,简化代码
创建新函数,复用代码
指定参数列表中部分参数为implicit
1 2 3 4 5 6 7 8
val number = List(1,2,3,4,5,6,7,8,9) numbers.foldLeft(0)(_ + _) // 柯里化生成新函数 val numberFunc = numbers.foldLeft(List[Int]())_ val square = numberFunc((xs, x) => xs:+ x*x) val cube = numberFunc((xs, x) => xs:+ x*x*x)
objectCustomerID{ defapply(name: String) = s"$name--${Random.nextLong}" defunapply(customerID: String): Option[String] = { val stringArray:[String] = customer.ID.split("--") if (stringArray.tail.nonEmpty) Some(StringArray.head) elseNone } }
val customer1ID = CustomerId("Tom") customer1ID match { caseCustomerID(name) => println(name) case _ => println("could not extract a CustomerID") } valCustomerID(name) = customer1ID // 变量定义中可以使用模式引入变量名 // 此处即使用提取器初始化变量,使用`unapply`方法生成值 val name = CustomerID.unapply(customer2ID).get
abstractclassPrinter[-A] { defprint(value: A): Unit } classAnimalPrinterextendsPrinter[Animal] { defprint(animal: Animal): Unit = println("The animal's name is: " + animal.name) } classCatPrinterextendsPrinter[Cat]{ defprint(cat: Cat): Unit = println("The cat's name is: " + cat.name) }
val myCat: Cat = Cat("Boots") defprintMyCat(printer: Printer[Cat]): Unit = { printer.print(myCat) }
val catPrinter: Printer[Cat] = newCatPrinter val animalPrinter: Printer[Animal] = newAnimalPrinter
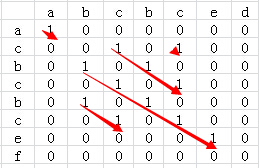
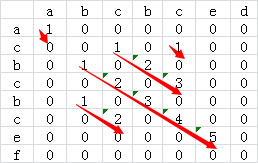
lengthOfLIS(nums[0..n-1]): // 动态规划求解最上升子序列 // 输入:序列nums // 输出:最长上升子序列长度 if n == 0: return0 LIS = InitVector() for num in nums: if num > LIS.last() LIS.push(num) else: for idx=0 to LIS.len(): if num <= LIS[idx]: break LIS[idx] = num // 更新上升子序列中首个大于当前元素的元素 return LIS.len()
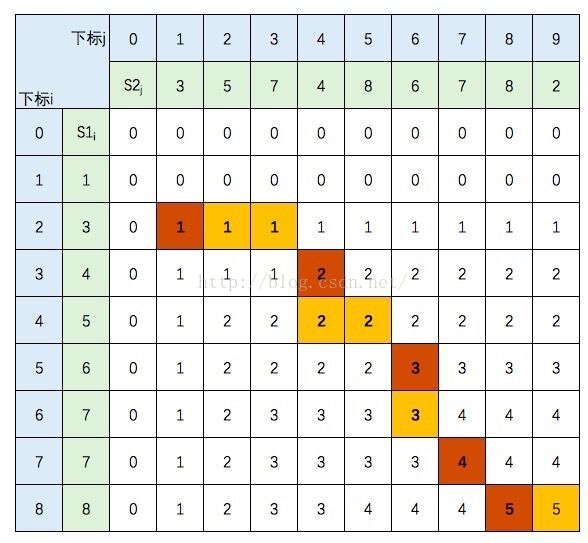
LongestSubParlidrome(nums[0..n-1]): // 中心扩展法求解最长回文子串 // 输入:串nums[0..n-1] // 输出:最长回文串 nnums = padding(nums) nn = len(nnums) max_shift, center = 0, -1 for i=0 to nn: shift = 1 while i >= shift and i + shift < nn: if nnums[i-shift] != nnums[i+shift]: break shift += 1
// 越界、不匹配,均为-1得到正确、有效`shift` shift -= 1
if shift > max_shift: max_shift, center = shift, i
left = (center - max_shift + 1) // 2 right = (center + max_shift) // 2 return nums[left : right]