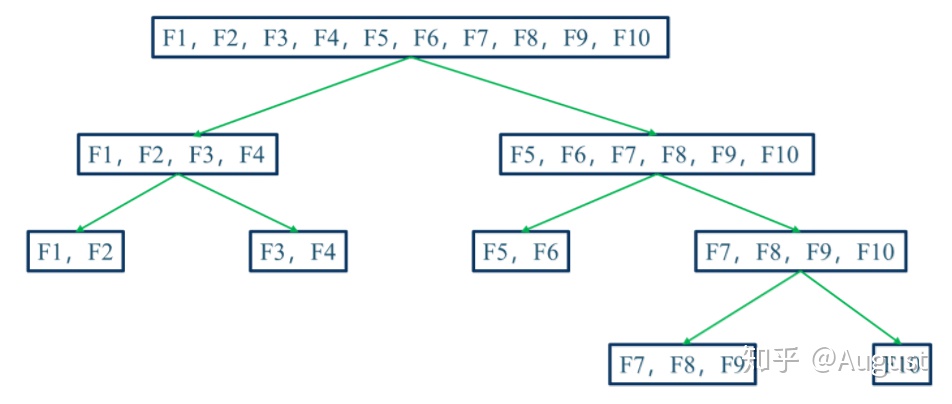
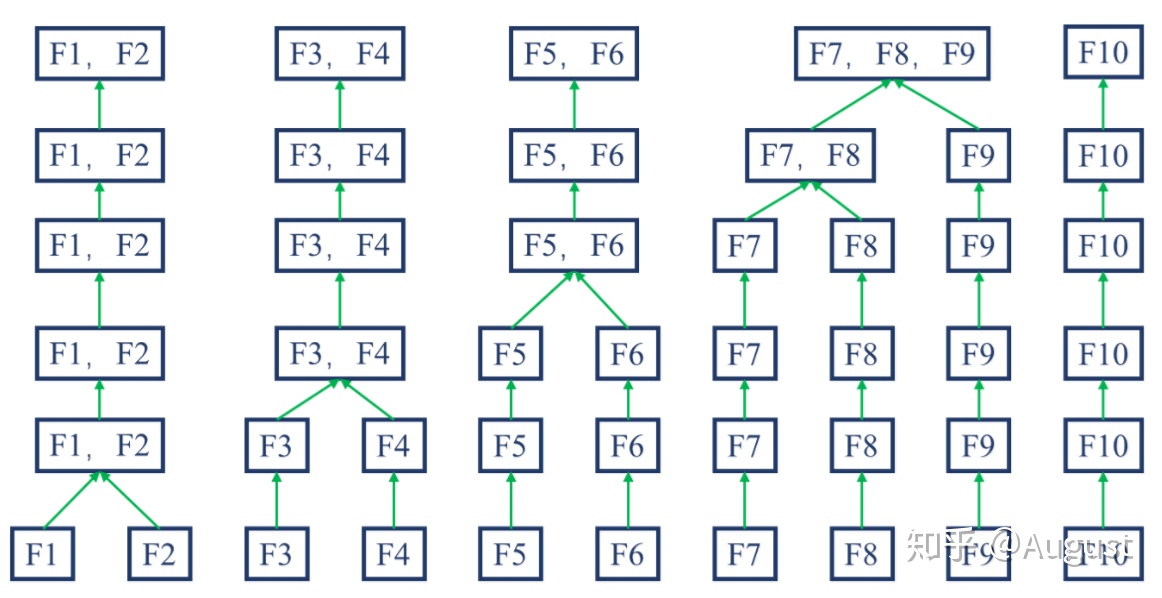
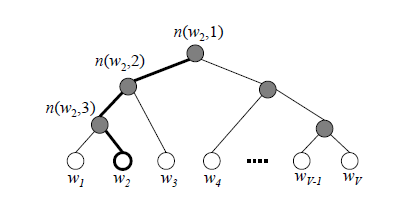
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
| Public Sub AllInternalPasswords()
Const DBLSPACE As String = vbNewLine & vbNewLine
Const AUTHORS As String = DBLSPACE & vbNewLine & _
"Adapted from Bob McCormick base code by" & _
"Norman Harker and JE McGimpsey"
Const HEADER As String = "AllInternalPasswords User Message"
Const VERSION As String = DBLSPACE & "Version 1.1.1 2003-Apr-04"
Const REPBACK As String = DBLSPACE & "Please report failure " & _
"to the microsoft.public.excel.programming newsgroup."
Const ALLCLEAR As String = DBLSPACE & "The workbook should " & _
"now be free of all password protection, so make sure you:" & _
DBLSPACE & "SAVE IT NOW!" & DBLSPACE & "and also" & _
DBLSPACE & "BACKUP!, BACKUP!!, BACKUP!!!" & _
DBLSPACE & "Also, remember that the password was " & _
"put there for a reason. Don't stuff up crucial formulas " & _
"or data." & DBLSPACE & "Access and use of some data " & _
"may be an offense. If in doubt, don't."
Const MSGNOPWORDS1 As String = "There were no passwords on " & _
"sheets, or workbook structure or windows." & AUTHORS & VERSION
Const MSGNOPWORDS2 As String = "There was no protection to " & _
"workbook structure or windows." & DBLSPACE & _
"Proceeding to unprotect sheets." & AUTHORS & VERSION
Const MSGTAKETIME As String = "After pressing OK button this " & _
"will take some time." & DBLSPACE & "Amount of time " & _
"depends on how many different passwords, the " & _
"passwords, and your computer's specification." & DBLSPACE & _
"Just be patient! Make me a coffee!" & AUTHORS & VERSION
Const MSGPWORDFOUND1 As String = "You had a Worksheet " & _
"Structure or Windows Password set." & DBLSPACE & _
"The password found was: " & DBLSPACE & "$$" & DBLSPACE & _
"Note it down for potential future use in other workbooks by " & _
"the same person who set this password." & DBLSPACE & _
"Now to check and clear other passwords." & AUTHORS & VERSION
Const MSGPWORDFOUND2 As String = "You had a Worksheet " & _
"password set." & DBLSPACE & "The password found was: " & _
DBLSPACE & "$$" & DBLSPACE & "Note it down for potential " & _
"future use in other workbooks by same person who " & _
"set this password." & DBLSPACE & "Now to check and clear " & _
"other passwords." & AUTHORS & VERSION
Const MSGONLYONE As String = "Only structure / windows " & _
"protected with the password that was just found." & _
ALLCLEAR & AUTHORS & VERSION & REPBACK
Dim w1 As Worksheet, w2 As Worksheet
Dim i As Integer, j As Integer, k As Integer, l As Integer
Dim m As Integer, n As Integer, i1 As Integer, i2 As Integer
Dim i3 As Integer, i4 As Integer, i5 As Integer, i6 As Integer
Dim PWord1 As String
Dim ShTag As Boolean, WinTag As Boolean
Application.ScreenUpdating = False
With ActiveWorkbook
WinTag = .ProtectStructure Or .ProtectWindows
End With
ShTag = False
For Each w1 In Worksheets
ShTag = ShTag Or w1.ProtectContents
Next w1
If Not ShTag And Not WinTag Then
MsgBox MSGNOPWORDS1, vbInformation, HEADER
Exit Sub
End If
MsgBox MSGTAKETIME, vbInformation, HEADER
If Not WinTag Then
MsgBox MSGNOPWORDS2, vbInformation, HEADER
Else
On Error Resume Next
Do
For i = 65 To 66: For j = 65 To 66: For k = 65 To 66
For l = 65 To 66: For m = 65 To 66: For i1 = 65 To 66
For i2 = 65 To 66: For i3 = 65 To 66: For i4 = 65 To 66
For i5 = 65 To 66: For i6 = 65 To 66: For n = 32 To 126
With ActiveWorkbook
.Unprotect Chr(i) & Chr(j) & Chr(k) & _
Chr(l) & Chr(m) & Chr(i1) & Chr(i2) & _
Chr(i3) & Chr(i4) & Chr(i5) & Chr(i6) & Chr(n)
If .ProtectStructure = False And _
.ProtectWindows = False Then
PWord1 = Chr(i) & Chr(j) & Chr(k) & Chr(l) & _
Chr(m) & Chr(i1) & Chr(i2) & Chr(i3) & _
Chr(i4) & Chr(i5) & Chr(i6) & Chr(n)
MsgBox Application.Substitute(MSGPWORDFOUND1, _
"$$", PWord1), vbInformation, HEADER
Exit Do
End If
End With
Next: Next: Next: Next: Next: Next
Next: Next: Next: Next: Next: Next
Loop Until True
On Error GoTo 0
End If
If WinTag And Not ShTag Then
MsgBox MSGONLYONE, vbInformation, HEADER
Exit Sub
End If
On Error Resume Next
For Each w1 In Worksheets
w1.Unprotect PWord1
Next w1
On Error GoTo 0
ShTag = False
For Each w1 In Worksheets
ShTag = ShTag Or w1.ProtectContents
Next w1
If ShTag Then
For Each w1 In Worksheets
With w1
If .ProtectContents Then
On Error Resume Next
Do
For i = 65 To 66: For j = 65 To 66: For k = 65 To 66
For l = 65 To 66: For m = 65 To 66: For i1 = 65 To 66
For i2 = 65 To 66: For i3 = 65 To 66: For i4 = 65 To 66
For i5 = 65 To 66: For i6 = 65 To 66: For n = 32 To 126
.Unprotect Chr(i) & Chr(j) & Chr(k) & _
Chr(l) & Chr(m) & Chr(i1) & Chr(i2) & Chr(i3) & _
Chr(i4) & Chr(i5) & Chr(i6) & Chr(n)
If Not .ProtectContents Then
PWord1 = Chr(i) & Chr(j) & Chr(k) & Chr(l) & _
Chr(m) & Chr(i1) & Chr(i2) & Chr(i3) & _
Chr(i4) & Chr(i5) & Chr(i6) & Chr(n)
MsgBox Application.Substitute(MSGPWORDFOUND2, _
"$$", PWord1), vbInformation, HEADER
For Each w2 In Worksheets
w2.Unprotect PWord1
Next w2
Exit Do
End If
Next: Next: Next: Next: Next: Next
Next: Next: Next: Next: Next: Next
Loop Until True
On Error GoTo 0
End If
End With
Next w1
End If
MsgBox ALLCLEAR & AUTHORS & VERSION & REPBACK, vbInformation, HEADER
End Sub
|