Hadoop概述
- Hadoop(核心):HDFS和MapReduce/YARN
- Hadoop家族:建立在Hadoop基础上的一系列开源工具

Hadoop
Hadoop时Apache的一个分布式计算、java语言实现的开源框架, 实现在大量计算机组成的集群中对海量数据进行分布式计算。相比于 依赖硬件的可靠性,Hadoop被设计为可以检测、处理应用层面的 failures,能够提供构建于电脑集群上的可靠服务。
Hadoop:Apache的分布式计算开源框架,提供分布式文件系统 HDFS、MapReduce/YARN分布式计算的软件架构
Hadoop Common
支持其它Hadoop模块的公用组件
Hadoop Distributed File System(HDFS)
虚拟文件系统,让整个系统表面上看起来是一个空间,实际上是很多 服务器的磁盘构成的
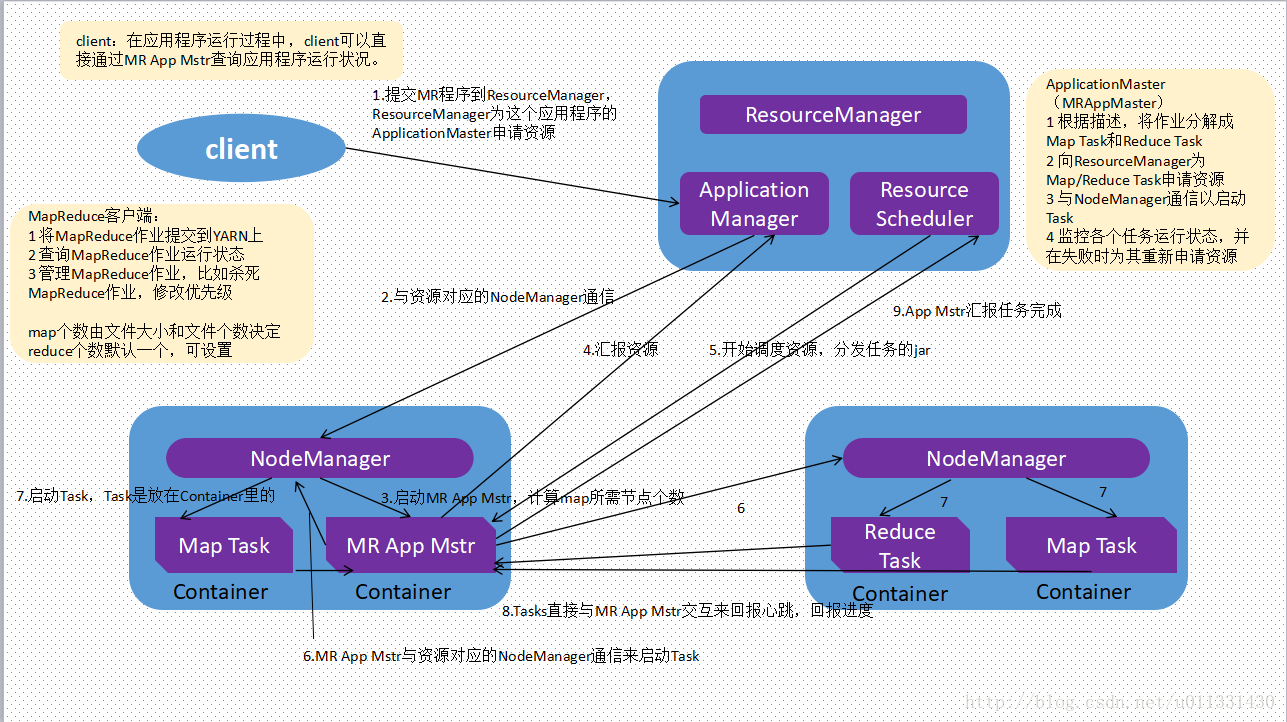
Hadoop YARN
Yet Another Resource Negotiator,通用任务、集群资源分配框架 ,面向Hadoop的编程模型
YARN将classic/MapReduce1中Jobtracker职能划分为多个独立 实体,改善了其面临的扩展瓶颈问题
YARN比MapReduce更具一般性,MapReduce只是YARN应用的一种 形式,可以运行Spark、Storm等其他通用计算框架
YARN精妙的设计可以让不同的YARN应用在同一个集群上共存, 如一个MapReduce应用可以同时作为MPI应用运行,提高可管理性 和集群利用率
Hadoop MapReduce
YARN基础上的大数据集并行处理系统(框架)
包括两个阶段
- Map:映射
- Reduce:归一
在分布式系统上进行计算操作基本都是由Map、Reduce概念步骤 组成
- 分布式系统,不像一般的数据库、文件系统,无法从上至下 、从头到尾进行求和等操作
- 需要由分散的节点不断向一个点聚拢的计算过程
不适合实时性要求的应用,只适合大数据离线处理
Apache下Hadoop相关项目
高频
Ambari
用于部署(供应)、管理、监控Hadoop集群的Web工具
支持HDFS、MapReduce、Hive、HCatalog、HBase、 Oozie、ZooKeeper、Pig、Sqoop
提供dashboard用于查看集群健康程度,如:热度图
能够直观的查看MapReduce、Pig、Hive应用特点,提供 易用的方式考察其执行情况
HBase
Hadoop项目子项目,高可靠、高性能、面向列、可伸缩的分布式 存储系统
该技术源于Fay Chang撰写的Google论文《Bigtable:一个 结构化数据的分布式存储系统》,类似于Bigtable在Google 文件系统上提供的分布式数据存储一样,HBase在Hadoop的 基础上提供了类似于Bigtable的能力
适合非结构化数据存储
可用于在廉价PC Server上搭建大规模结构化存储集群,是 NoSQL数据库的两个首选项目(MongoDB)
Hive
基于Hadoop的数据仓库工具
在Hive中建立表,将表映射为结构化数据文件
可以通过类SQL语句直接查询数据实现简单的MapReduce统计, 而不必开发专门的MapReduce应用
- Hive会将SQL语句转换为MapReduce任务查询Hadoop
- 速度很慢
- 适合数据仓库的统计分析
- 支持SQL语法有限
Pig
基于Hadoop的大规模数据高层分析工具(类似于Hive)
提供SQL-Like语言
PigLatin其编译器会把类SQL的数据分析请求,转换为一系列经过 优化处理的MapReduce运算
是一种过程语言,和Hive中的类SQL语句相比,更适合写 脚本,而Hive的类SQL语句适合直接在命令行执行
Zookeeper
Hadoop正式子项目,针对大型分布式应用设计的分布式、开源协调 系统
提供功能:配置维护、名字服务、分布式同步、组服务
封装好复杂、易出错的关键服务,提供简单易用、功能稳定、 性能高效的接口(系统),解决分布式应用中经常遇到的数据 管理问题,简化分布式应用协调及管理难度,提供高性能分布式 服务
通常为HBase提供节点间的协调,部署HDFS的HA模式时是 必须的
Spark
基于内存计算的开源集群计算系统,目的是让数据分析更加快速
低频
Mahout
基于Hadoop的机器学习、数据挖掘的分布式框架
使用MapReduce实现了部分数据挖掘算法,解决了并行挖掘问题
- 包括聚类、分类、推荐过滤、频繁子项挖掘
通过使用Hadoop库,Mahout可以有效扩展至云端
Cassandra
开源分布式NoSQL数据库系统,最初由Facebook开发,用于存储 简单格式数据,集Google BigTable数据模型和Amazon Dynamo 的完全分布式架构于一身
Avro
数据序列化系统,设计用于支持数据密集型、大批量数据交换应用,
是新的数据序列化格式、传输工具,将逐步取代Hadoop原有的
IPC机制
Chukwa
用于监控大型分布式系统的开源数据收集系统,可以将各种类型的 数据收集成适合Hadoop处理的文件,保存在HDFS中供MapReduce 操作
Tez
基于YARN的泛用数据流编程平台
- 提供强力、灵活的引擎用于执行任何DAG任务,为批处理和 交互用例处理数据
Tez正逐渐被Hive、Pig等Hadoop生态框架采用,甚至被一些 商业公司用于替代MapReduce作为底层执行引擎
其他Hadoop相关项目
高频
Sqoop
用于将Hadoop和关系型数据库中数据相互转移的开源工具
可以将关系型数据库(MySQL、Oracle、Postgres)中 数据转移至Hadoop的HDFS中
也可以将HDFS的数据转移进关系型数据库中
Impala
由Cloudera发布的实时查询开源项目
模仿Google Dremel
称比基于MapReduce的Hive SQL查询速度提升3~30倍,更加 灵活易用
Phoenix
apache顶级项目,在HBase上构建了一层关系型数据库,可以用 SQL查询HBase数据库,且速度比Impala更快,还支持包括 二级索引在内的丰富特性,借鉴了很多关系型数据库优化查询方法
Oozie
工作流引擎服务器,用于管理、协调运行在Hadoop平台 (HDFS、Pig、MapReduce)的任务
Cloudera Hue
基于Web的监控、管理系统,实现对HDFS、MapReduce/YARN、 HBase、Hive、Pig的Web化操作和管理
低频
Hama
基于HDFS的BSP(Bulk Synchronous Parallel)并行 计算框架,可以用包括图、矩阵、网络算法在内的大规模、 大数据计算
Flume
分布的、可靠的、高可用的海量日志聚合系统,可用于日志数据 收集、处理、传输
Giraph
基于Hadoop的可伸缩的分布式迭代图处理系统,灵感来自于BSP和 Google Pregel
Crunch
基于Google FlumeJava库编写的Java库,用于创建MapReduce 流水线(程序)
类似于Hive、Pig,提供了用于实现如连接数据、执行聚合 、排序记录等常见任务的模式库
但是Crunch不强制所有输入遵循同一数据类型
其使用一种定制的类型系统,非常灵活,能直接处理复杂 数据类型,如:时间序列、HDF5文件、HBase、序列化 对象(protocol buffer、Avro记录)
尝试简化MapReduce的思考方式
MapReduce有很多优点,但是对很多问题,并不是合适的 抽象级别
出于性能考虑,需要将逻辑上独立的操作(数据过滤、投影 、变换)组合为一个物理上的MapReduce操作
Whirr
运行于云服务的类库(包括Hadoop),提供高度互补性
- 相对中立
- 支持AmazonEC2和Rackspace的服务
Bigtop
对Hadoop及其周边生态打包、分发、测试的工具
HCatalog
基于Hadoop的数据表、存储管理,实现中央的元数据、模式管理, 跨越Hadoop和RDBMS,利用Pig、Hive提供关系视图
Llama
让外部服务器从YARN获取资源的框架
非CDH组件
Fuse
让HDFS系统看起来像普通文件系统
Hadoop Streamin
MapReduce代码其他语言支持,包括:C/C++、Perl、Python 、Bash等