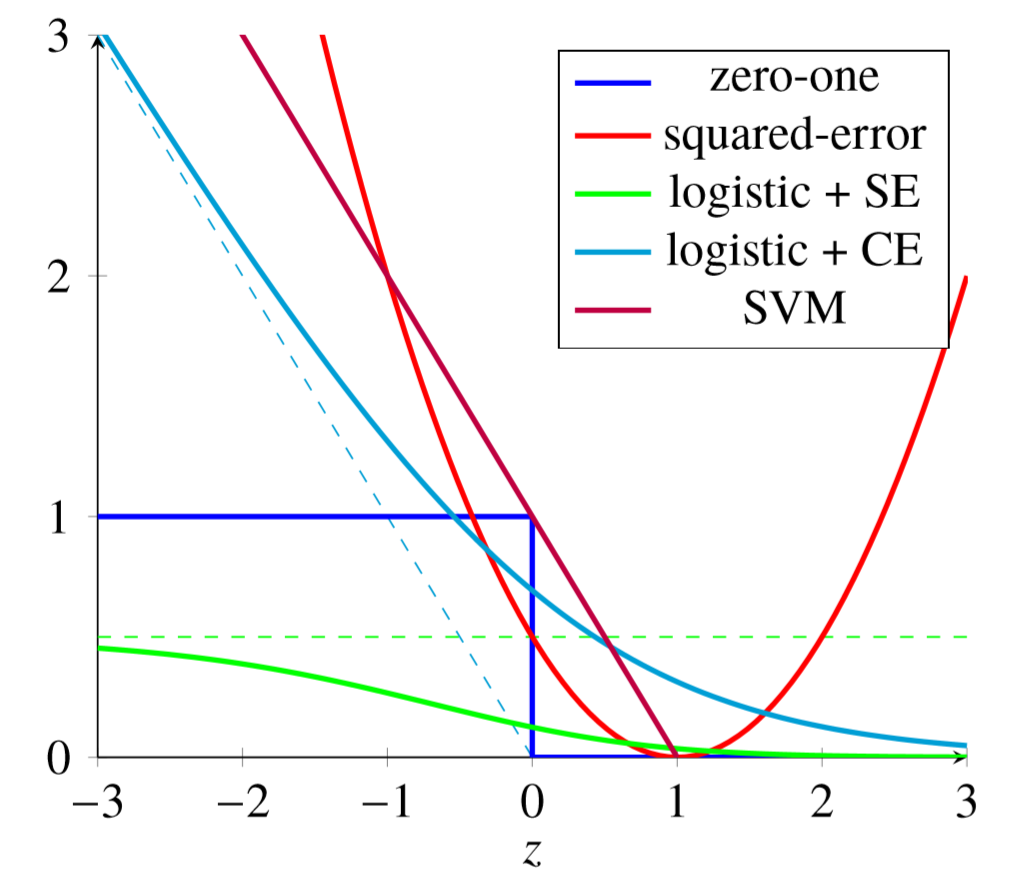
损失函数理论
参数估计
矩估计:建立参数和总体矩的关系,求解参数
- 除非参数本身即为样本矩,否则基本无应用价值
- 应用场合
- 均值:对应二次损失 $\arg\min{\mu} \sum{i=1}^N (x_i - \mu)^2$
- 方差:对应二次损失?
极大似然估计:极大化似然函数,求解概率上最合理参数
- 需知道(假设)总体 概率分布形式
- 似然函数形式复杂,求解困难
- 往往无法直接给出参数的解析解,只能求数值解
- 应用场合
- 估计回归参数:对数损失 $\mathop{\arg\min}{\beta} \sum{i=1}^N lnP(y_i|x_i, \beta)$
损失函数估计:极小化损失函数,求解损失最小的参数
- 最泛用的参数求解方法
- 适合求解有大量参数的待求解的问题
- 往往通过迭代方式逐步求解
- 特别的
- 线性回归使用 MSE 作为损失函数时,也被称为最小二乘估计
- 极大似然估计同对数损失函数
- 最泛用的参数求解方法
- 参数估计都可以找到合适损失函数,通过迭代求解损失最小化
随机模拟估计参数
- 需要设计随机模拟实验估计参数
- 应用场合
- 蒙特卡洛类似算法:随机化损失
迭代求解参数
损失函数定义不同
- 包含样本量数量不同
- 惩罚项设置不同
异步更新参数
- 同时求解参数数量:全部、部分、单个
- 参数升维
更新方向
- 梯度
- 海瑟矩阵
- 次梯度
更新方式
- 叠加惯性
- 动态学习率
Loss Models
模型(目标函数)在样本整体的损失:度量模型整体预测效果
- 代表模型在整体上的性质,有不同的设计形式
可以用于 设计学习策略、评价模型
- 风险函数
- 评价函数
有时在算法中也会使用整体损失
Expected Risk / Expected Loss / Generalization Loss
期望风险(函数):损失函数 $L(Y, f(X))$(随机变量)期望
- $P(X, Y)$:随机变量 $(X, Y)$ 遵循的联合分布,未知
风险函数值度量模型预测错误程度
- 反映了学习方法的泛化能力
- 评价标准(监督学习目标)就应该是选择期望风险最小
联合分布未知,所以才需要学习,否则可以直接计算条件分布概率,而计算期望损失需要知道联合分布,因此监督学习是一个病态问题
Empirical Risk / Empirical Loss
经验风险:模型关于给定训练数据集的平均损失
- $\theta$:模型参数
- $D_i$:样本损失权重,常为 $\frac 1 N$,在 Boosting 框架中不同
经验风险损失是模型 $f(x)$ 的函数
- 训练时,模型是模型参数的函数
- 即其为模型参数函数
根据大数定律,样本量容量 $N$ 趋于无穷时,$R{emp}(f)$ 趋于 $R{exp}(f)$
- 但是现实中训练样本数目有限、很小
- 利用经验风险估计期望常常并不理想,需要对经验风险进行矫正
例子
- maximum probability estimation:极大似然估计
- 模型:条件概率分布(贝叶斯生成模型、逻辑回归)
- 损失函数:对数损失函数
- maximum probability estimation:极大似然估计
Structual Risk / Structual Loss
结构风险:在经验风险上加上表示 模型复杂度 的 regularizer(penalty term)
- $J(f)$:模型复杂度,定义在假设空间$F$上的泛函
- $\lambda$:权衡经验风险、模型复杂度的系数
- 结构风险最小化
- 添加 regularization(正则化),调节损失函数(目标函数)
- 模型复杂度 $J(f)$ 表示对复杂模型的惩罚:模型 $f$ 越复杂,复杂项 $J(f)$ 越大
- 案例
- maximum posterior probability estimation:最大后验概率估计
- 损失函数:对数损失函数
- 模型复杂度:模型先验概率对数后取负
- 先验概率对应模型复杂度,先验概率越小,复杂度越大
- 岭回归:平方损失 + $L2$ 正则化 $\mathop{\arg\min}{\beta} \sum_{i=1}^N (y_i - f(x_i, \beta))^2 + |\beta|$
- LASSO:平方损失 + $L1$ 正则化 $\mathop{\arg\min}{\beta} \sum_{i=1}^N (y_i - f(x_i, \beta))^2 + |\beta|_1$
- maximum posterior probability estimation:最大后验概率估计
Generalization Ability
泛化能力:方法学习到的模型对未知数据的预测能力,是学习方法本质、重要的性质
- 测试误差衡量学习方法的泛化能力不可靠,其依赖于测试集,而测试集有限
- 学习方法的泛化能力往往是通过研究泛化误差的概率上界进行
Generalization Error Bound
泛化误差上界:泛化误差的 概率 上界
- 是样本容量函数,样本容量增加时,泛化上界趋于 0
- 是假设空间容量函数,假设空间容量越大,模型越难学习,泛化误差上界越大
泛化误差
根据 Hoeffding 不等式,泛化误差满足
- $H$:假设空间
- $N$:样本数量
- $E(h) := R_{exp}(h)$
- $\hat E(h) := R_{emp}(h)$
证明如下:
对任意 $\epsilon$,随样本数量 $m$ 增大, $|E(h) - \hat E(h)| \leq \epsilon$ 概率增大,可以使用经验误差近似泛化误差
二分类泛化误差上界
由 Hoeffding 不等式
则 $\forall h \in H$,有
则令 $\sigma = |H| exp(-2N\epsilon^2)$,则至少以概率 $1-\sigma$ 满足如下,即得到泛化误差上界
Probably Approximate Correct 可学习
PAC 可学习:在短时间内利用少量(多项式级别)样本能够找到假设 $h^{‘}$,满足
即需要假设满足两个 PAC 辨识条件
- 近似条件:泛化误差 $E(h^{‘})$ 足够小
- 可能正确:满足近似条件概率足够大
同等条件下
- 模型越复杂,泛化误差越大
- 满足条件的样本数量越大,模型泛化误差越小
PAC 学习理论关心能否从假设空间 $H$ 中学习到好的假设 $h$
- 由以上泛化误差可得,取 $\sigma = 2|H|e^{-2N\epsilon^2}$,则样本量满足 $N = \frac {ln \frac {2|H|} \sigma} {2 \epsilon^2}$ 时,模型是 PAC 可学习的
Regularization
正则化:(向目标函数)添加额外信息以求解病态问题、避免过拟合
常应用在机器学习、逆问题求解
- 对模型(目标函数)复杂度惩罚
- 提高学习模型的泛化能力、避免过拟合
- 学习简单模型:稀疏模型、引入组结构
有多种用途
- 最小二乘也可以看作是简单的正则化
- 岭回归中的 $\mathcal{l_2}$ 范数
模型复杂度
模型复杂度:经常作为正则化项添加作为额外信息添加的,衡量模型复杂度方式有很多种
函数光滑限制
- 多项式最高次数
向量空间范数
- $\mathcal{L_0} - norm$:参数个数
- $\mathcal{L_1} - norm$:参数绝对值和
- $\mathcal{L_2}$- norm$:参数平方和
$\mathcal{L_0} - norm$
- $\mathcal{l_0} - norm$ 特点
- 稀疏化约束
- 解 $\mathcal{L_0}$ 范数正则化是 NP-hard 问题
$\mathcal{L_1} - norm$
$\mathcal{L_1} - norm$ 特点
- $\mathcal{L_1}$ 范数可以通过凸松弛得到 $\mathcal{L_0}$ 的近似解
- 有时候出现解不唯一的情况
- $\mathcal{L_1}$ 范数凸但不严格可导,可以使用依赖次梯度的方法求解极小化问题
应用
- LASSO
求解
- Proximal Method
- LARS
$\mathcal{L_2} - norm$
- $\mathcal{L_2} - norm$ 特点
- 凸且严格可导,极小化问题有解析解
$\mathcal{L_1 + L_2}$
$\mathcal{L_1 + L_2}$ 特点
- 有组效应,相关变量权重倾向于相同
应用
- Elastic Net
稀疏解产生
稀疏解:待估参数系数在某些分量上为 0
$\mathcal{L_1} - norm$ 稀疏解的产生
- $\mathcal{L_1}$ 范数在参数满足 一定条件 情况下,能对 平方损失 产生稀疏效果
在 $[-1,1]$ 内 $y=|x|$ 导数大于 $y=x^2$(除 0 点)
- 则特征在 0 点附近内变动时,为了取到极小值,参数必须始终为 0
- 高阶项在 0 点附近增加速度较慢,所以 $\mathcal{L_1} - norm$ 能产生稀疏解是很广泛的
- $mathcal{L_1} - norm$ 前系数(权重)越大,能够容许高阶项增加的幅度越大,即压缩能力越强
在 0 附近导数 “不小”,即导数在 0 点非 0
- 对多项式正则化项
- $\mathcal{L_1} - norm$ 项对稀疏化解起决定性作用
- 其他项对稀疏解无帮助
- 对“非多项式”正则化项
- $e^{|x|}-1$、$ln(|x|+1)$ 等在0点泰勒展开同样得到 $\mathcal{L_1} - norm$ 项
- 但是此类正则化项难以计算数值,不常用
- 对多项式正则化项
$\mathcal{L_1} - norm$ 稀疏解推广
正负差异化:在正负设置权重不同的 $\mathcal{L_1}$,赋予在正负不同的压缩能力,甚至某侧完全不压缩
分段函数压缩:即只要保证在 0 点附近包含 $\mathcal{L_1}$ 用于产生稀疏解,远离 0 处可以设计为常数等不影响精确解的值
Smoothly Clipped Absolute Deviation
Derivate of SCAD
Minimax Concave Penalty
分指标:对不同指标动态设置 $\mathcal{L_0}$ 系数
- Adaptive Lasso:$\lambda \sum_J w_jx_j$
稀疏本质
稀疏本质:极值、不光滑,即导数符号突然变化
若某约束项导数符号突然变化、其余项在该点处导数为 0,为保证仍然取得极小值,解会聚集(极小)、疏远(极大)该点(类似坡的陡峭程度)
- 即此类不光滑点会抑制解的变化,不光滑程度即导数变化幅度越大,抑制解变化能力越强,即吸引、排斥解能力越强
- 容易构造压缩至任意点的约束项
- 特殊的,不光滑点为 0 时,即得到稀疏解
可以设置的多个极小不光滑点,使得解都在不连续集合中
- 可以使用三角函数、锯齿函数等构造,但此类约束项要起效果,必然会使得目标函数非凸
- 但是多变量场合,每个变量实际解只会在某个候选解附近,其邻域内仍然是凸的
- 且锯齿函数这样的突变非凸可能和凸函数具有相当的优秀性质
- 当这些点均为整数时,这似乎可以近似求解 整数规划
- 可以使用三角函数、锯齿函数等构造,但此类约束项要起效果,必然会使得目标函数非凸
Early Stopping
Early Stopping:提前终止(训练)
- Early Stopping 也可以被视为是 regularizing on time
- 迭代式训练随着迭代次数增加,往往会有学习复杂模型的倾向
- 对时间施加正则化,可以减小模型复杂度、提高泛化能力