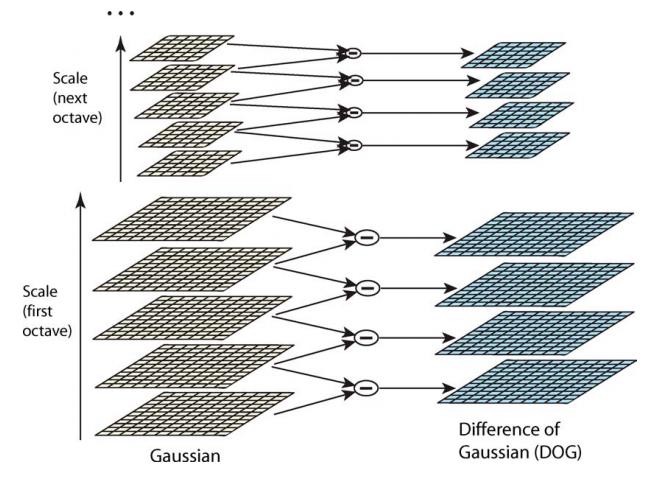
网络结构
- node/vertex:人
- link/edge:人与人之间的relation,可以有标签、权重、 方向
- graph/network:社交网络,表示个体之间的相互关系
- 图、网络参见cs_algorithm/data_structure/graph
基本统计指标、特性
subnetwork/subgraph
- singleton:单点集,没有边的子图
- clique:派系,任意两个节点间均有连边的子图
degree:
- 对有向图可以分为out-degree、in-degree
- average degree:网络平均度,所有节点度的算术平均
- degree distribution:网络度分布,概率分布函数 $P(k)$
Path
- path length:路径长度
- shortest path:节点间最短路径
- distance:节点距离,节点间最短路径长度
diameter:网络直径,任意两个节点间距离最大值
对规模(节点数量)为$N$大多数现实网络(尤其是社交网络)
- 小直径:与六度分离实验相符
- 存在巨大连通分支
- 高聚类特性:具有较大点聚类系数
- 明显的模块结构
- giant connected component:巨大连通分支,即规模达到 $O(N)$的连通分支
node clustering coefficient:点聚类系数
- $triangle_i$:包含节点$i$三角形数量
- $triple_i$:与节点$i$相连三元组:包含节点$i$的三个 节点,且至少存在节点$i$ 到其他两个节点的两条边
- $NC_i$:节点$i$聚类系数
- $NC$:整个网络聚类系数
edge clustering coefficient:边聚类系数
- $d_i$:节点$i$度,即分母为边$
- $d_i$:节点$i$度,即分母为边$
edge betweenness:边介数,从源节点$v$出发、通过该边 的最短路径数目
边介数的计算
从源节点$i$出发,为每个节点$j$维护距离源节点最短路径 $d_j$、从源节点出发经过其到达其他节点最短路径数目$w_j$
定义源节点$i$距离$d_i=0$、权值$w_i=1$
对源节点$i$的邻接节点$j$,定义其距离$d_j=d_i+1$、 权值$w_j=w_i=1$
对节点$j$的任意邻接节点$k$
- 若$k$未被指定距离,则指定其距离$d_k=d_j+1$、 权值$w_k=w_j$
- 若$k$被指定距离且$d_k=d_j+1$,则原权值增加1, 即$w_k=w_k+1$
- 若$k$被指定距离且$d_k<d_j+1$,则跳过
重复以上直至网络中包含节点的连通子图中节点均被指定 距离、权重
从节点$k$经过节点$j$到达源节点$i$的最短路径数目、与节点 $k$到达源节点$i$的最短路径数目之比为$w_i/w_j$
从叶子节点$l$开始,若叶子节点$l$节点$i$相邻,则将 权值$w_i/w_l$赋给边$(i,l)$
从底至上,边$(i,j)$赋值为该边之下的邻边权值之和加1 乘以$w_i/w_j$
重复直至遍历图中所有节点
- 叶子节点:广度优先搜索叶子节点,即不被任何从源节点出发到 其他节点的最短路径经过
- 此边介数计算方式与节点介数中心性计算,都是寻找通过边、 节点的最短路径数目,但是具体计算方式不同
最短路径唯一
- 考虑从任何节点间最短路径只有一条,则某节点到其他节点 的最短路径构成一棵最短路径树
- 找到最短路径树的叶子节点,为每条与叶子节点相连的边赋值 为1
- 自下而上为树中其他边赋值:边之下所有临边值之和加1
- 处理所有节点直至树根源节点时,各边相对于树根源节点的介数 即为其权重
- 对各节点分别重复以上即可得到各边对各节点介数,相总即可得 各边总边介数
Node Centrality
节点中心性:采用某种定量方法对每个节点处于网络中心地位的程度 进行刻画
- 描述整个网络是否存在核心、核心的状态
基于度
Degree Centrality:度中心性
- $d_i$:节点$i$的度
- 衡量节点对促进网络传播过程发挥的作用
eigenvector centrality:特征向量中心性
$$ EC_i = $
subgraph centrality:子图中心性
$$ SC_i = $
基于路径数
Betweenness Centrality:介数中心性
- $p_{j,k}$:节点$j,k$间路径数量
- $p_{j,k}(i)$:节点$j,k$间路径经过节点$i$路径数量
- 衡量节点对其他节点间信息传输的潜在控制能力
Closeness Centrality
Community Structure
社团/模块/社区结构:内部联系紧密、外部联系稀疏(通过边数量 体现)的子图
基于连接频数的定义
- $G, S$:全图、子图
- $\simga_{in}(S)$:子图$S$的内部连接率/频数
- $S_{in}$:子图$S$内部的实际边数
- $E, E(S)$:全图、子图$S$内部边
- $V, V(S)$:全图、子图$S$内部节点
若子图$S \subset G$满足如下,则称为网络$G$的社区
强弱社区
强社区结构
- $E_{in}(S, i)$:节点$i$和子图$S$内节点连边
- $E_{out}(S, i)$:节点$i$和子图$S$内节点连边
弱社区结构
最弱社区结构
- 社区$S_1,S_2,\cdots,S_M$是网络$G$中社区
- $E(S_j, i, S_k)$:子图$S_j$中节点$i$与子图$S_k$之间 连边数
改进的弱社区结构:同时满足弱社区结构、最弱社区结构
LS集
LS集:任何真子集与集合内部连边数都多于与集合外部连边数 的节点集合
Clique
- 派系:节点数大于等于3的全连通子图
n派系:任意两个顶点最多可以通过n-1个中介点连接
- 对派系定义的弱化
- 允许两社团的重叠
全连通子图:任意两个节点间均有连边
模块度函数Q
- $\hat e_{i,i}$:随机网络中社区$i$内连边数占比期望
- $e_{i,j}$:社区$i,j$中节点间连边数在所有边中所占比例
- $ai = \sum_j e{i,j}$:与社区$i$中节点连边数比例
思想:随机网络不会具有明显社团结构
不考虑节点所属社区在节点对间直接连边,则应有 $\hat e{i,j} = a_i a_j$,特别的 $\hat e{i,i} = a_i^2$
比较社区实际覆盖度、随机连接覆盖度差异评估对社区结构 的划分
划分对应Q值越大,划分效果越好
- $0< Q <1$:一般以$Q=0.3$作为网络具有明显社团结构的 下限
- 实际网络中$Q{max} \in [0.3, 0.7]$,$Q{max}$越大 网络分裂(聚类)性质越强,社区结构越明显
缺点
- 采用完全随机形式,无法避免重边、自环的存在,而现实 网络研究常采用简单图,所以Q值存在局限
- Q值分辨能力有限,网络中规模较大社区会掩盖小社区, 即使其内部连接紧密
- 覆盖度:社区内部连接数占总连接数比例
模块密度D
- 模块密度D表示社区内部连边、社区间连边之差与社区节点总数
之比
- 值越大表示划分结果越好
- 考虑社区总节点数,克服模块度Q无法探测小社区的缺陷
社区度C
- $\frac {|E_{in}(S_i)} {|V(S_i)||(|V(S_i)-1)/2}$:社区 $S_i$的簇内密度
- $\frac {|E_{out}(S_i)} {|V(S_i)||(|V|-|V(S_i))}$:社区 $S_i$的簇内密度
Fitness函数
- $f_i$:社区$S_i$的fitness函数
- $d{in}(S_i) = 2 * E{in}(S_i)$:社区$S_i$内部度
- $d{out}(S_i) = E{out}(S_i)$:社区$S_i$外部度
- $\bar f$:整个网络社区划分的fitness函数
- fitness函数使用直接的方式避开了模块度Q函数的弊端
- 应用结果显示其为网络社区结构的有效度量标准
Modularity
社区发现算法
网络测试集
Girvan、Newman人工构造网络
- 网络包含128个节点、平均分为4组
- 每组内部连边、组间连边概率分别记为$p{in}, p{out}$
- 要求每个节点度期望为16
Lancichinet ti人工构造网络
- 测试集中节点度、社区大小服从幂律分布
- 混淆参数$\mu$控制社区结构显著程度
小规模、社区结构已知真实网络
- Zachary空手道俱乐部
- 海豚社会关系网络
- 美国大学生足球俱乐部网络
社区发现算法
- Agglomerative Method:凝聚算法
- NF算法
- Walk Trap
Division Method:分裂算法
- Girvan-Newman算法
- 边聚类探测算法
凝聚算法流程
- 最初每个节点各自成为独立社区
- 按某种方法计算各社区之间相似性,选择相似性最高的社区
合并
- 相关系数
- 路径长度
- 矩阵方法
- 不断重复直至整个网络成为一个社区
算法流程可以的用世系图表示
- 可以在任意合并步骤后停止,此时节点聚合情况即为网络中 社区结构
- 但应该在度量标准值最大时停止
- 分裂算法流程同凝聚算法相反
Girvan-Newman算法
GN算法
流程
- 计算网络中各边相对于可能源节点的边介数
- 删除网络中边介数较大的边,每当分裂出新社区
(即产生新连通分支)
- 计算网络的社区结构评价指标
- 记录对应网络结构
- 重复直到网络中边都被删除,每个节点为单独社区,选择 最优评价指标的网络结构作为网络最终分裂状态
缺点:计算速度满,边介数计算开销大,只适合处理中小规模 网络
Newman Fast Algorithm
NF快速算法:
流程
初始化网络中各个节点为独立社区、矩阵$E={e_{i,j}}$
- $M$:网络中边总数
- $e_{i,j}$:网络中社区$i,j$节点边在所有边中占比
- $a_i$:与社区$i$中节点相连边在所有边中占比
依次合并有边相连的社区对,计算合并后模块度增量
- 根据贪婪思想,每次沿使得$Q$增加最多、减少最小 方向进行
- 每次合并后更新元素$e_{i,j}$,将合并社区相关行、 列相加
- 计算网络社区结构评价指标、网络结构
重复直至整个网络合并成为一个社区,选择最优评价指标 对应网络社区结构
基于贪婪思想的凝聚算法
GN算法、NF算法大多使用无权网络,一个可行的方案是计算无权 情况下各边介数,加权网络中各边介数为无权情况下个边介数 除以边权重
- 此时,边权重越大介数越小,被移除概率越小,符合社区 结构划分定义
Edge-Clustering Detection Algorithm
边聚类探测算法:
- 流程:
- 计算网络中尚存的边聚类系数值
- 移除边聚类系数值最小者$(i,j)$,每当分裂出新社区
(即产生新连通分支)
- 计算网络社区评价指标fitness、modularity
- 记录对应网络结构
- 重复直到网络中边都被删除,每个节点为单独社区,选择 最优评价指标的网络结构作为网络最终分裂状态
Walk Trap
随机游走算法:
Label Propagation
标签扩散算法:
Self-Similar
(网络结构)自相似性:局部在某种意义上与整体相似
- fractal分形的重要性质
Random Walk
(网络)随机游走:
游走形式
- unbiased random walks:无偏随机游走,等概率游走
- biased random walks:有偏随机游走,正比于节点度
- self-avoid walks:自规避随机游走
- quantum walks:量子游走
研究内容
first-passage time:平均首达时间
mean commute time:平均转移时间
mean return time:平均返回时间
用途
- community detection:社区探测
- recommendation systems:推荐系统
- electrical networks:电力系统
- spanning trees:生成树
- infomation retrieval:信息检索
- natural language proessing:自然语言处理
- graph partitioning:图像分割
- random walk hypothesis:随机游走假设(经济学)
- pagerank algorithm:PageRank算法
网络可视化
Graph Layout
图布局:无实际意义但是影响网络直观效果
- random layout:随机布局,节点、边随机放置
- circular layout:节点放在圆环上
- grid layout:网格布局
- force-directed layout:力导向布局
- 最常用
- 动态、由节点相互连接决定布局
- 点距离较近节点在放置在较近位置
- YiFan Hu layout
- Harel-Koren Fast Multiscale Layout
- NodeXL:节点以box形式被展示,边放置在box内、间
Visualizing Network Features
网络特征可视化:边权、节点特性、标签、团结构
- 标签:只显示感兴趣标签
- 度、中心性、权重等量化特征:借助大小、形状、颜色体现
- 节点分类信息:节点节点颜色、形状体现
Scale Issue
网络可视化:是否对所有网络均有可视化必要
- 网络密度太小、太大,无可视化必要
现实网络
网络科学:现实世界的任何问题都可以用复杂关系网络近似模拟
- 节点:研究问题中主体
- 边:模拟主体间的某种相互关系
现实网络大多为无标度网络,且幂指数$\gamma \in [2, 3]$
- 网络中大部分节点度很小,小部分hub节点有很大的度
- 对随机攻击稳健,但对目的攻击脆弱
- triangle power law:网络中三角形数量服从幂律分布
- eigenvalue power law:网络邻接矩阵的特征值服从 幂律分布
绝大多数现实网络、网络结构模型虽然不能只管看出自相性, 但是在某种length-scale下确实具有自相似性
- 万维网
- 社会网络
- 蛋白质交互作用网络
- 细胞网络
个体社会影响力:社交网络中节点中心性
- power-law distribution:幂律分布
- scale-free network:无标度网络,度分布服从幂律分布的 复杂网络,具有无标度特性
- heavy-tailed distribution:厚尾分布
社交网络
人、人与人之间的关系确定,则网络结构固定
有人类行为存在的任何领域都可以转化为社交网络形式
- offline social networks:线下社交网络,现实面对面 接触中的人类行为产生,人类起源时即出现
- online social networks/social webs:在线社交网络
- social media websites:多媒体网社交网
由于社交网络中人类主观因素的存在,定性特征可以用于社交 网络分析
- 关系强弱
- 信任值
对网络结构的分析的数量化指标可以分析社交网络的基本特征
- 度、度分布
- 聚类系数
- 路径长度
- 网络直径
数据分析类型
- Content Data:内容数据分析,文本、图像、其他多媒体 数据
- Linkage Data:链接数据分析,网络的动力学行为:网络 结构、个体之间沟通交流
社交网络中社区发现
现实世界网络普遍具有模块/社区结构特性
- 内部联系紧密、外部连接稀疏
- 提取社区/模块结构,研究其特性有助于在网络动态演化 过程中理解、预测其自然出现的、关键的、具有因果关系的 本质特性
挑战
- 现实问题对应的关系网络
- 拓扑结构类型未知
- 大部分为随时间变化网络
- 规模庞大
- 现有技术方法应用受到限制
- 多数方法适用静态无向图,研究有向网络、随时间动态 演化网络形式技术方法较少
- 传统算法可能不适用超大规模网络
- 现实问题对应的关系网络
社区发现/探测重要性
- 社区结构刻画了网络中连边关系的局部聚集特性,体现了 连边的分布不均匀性
- 社区通常由功能相近、性质相似的网络节点组成
- 有助于揭示网络结构和功能之间的关系
- 有助于更加有效的理解、开发网络