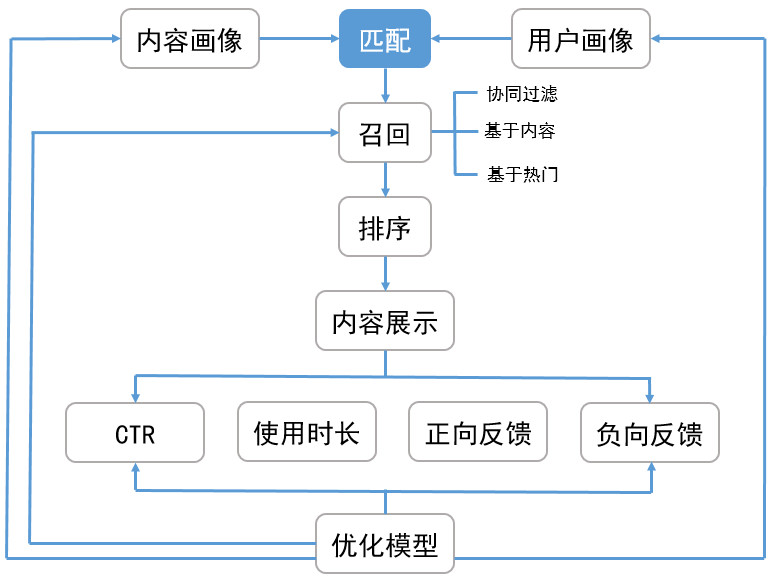
CTR Stacking Models
深度学习CTR
Deep Crossing
Deep Crossing:深度学习CTR模型最典型、基础性模型
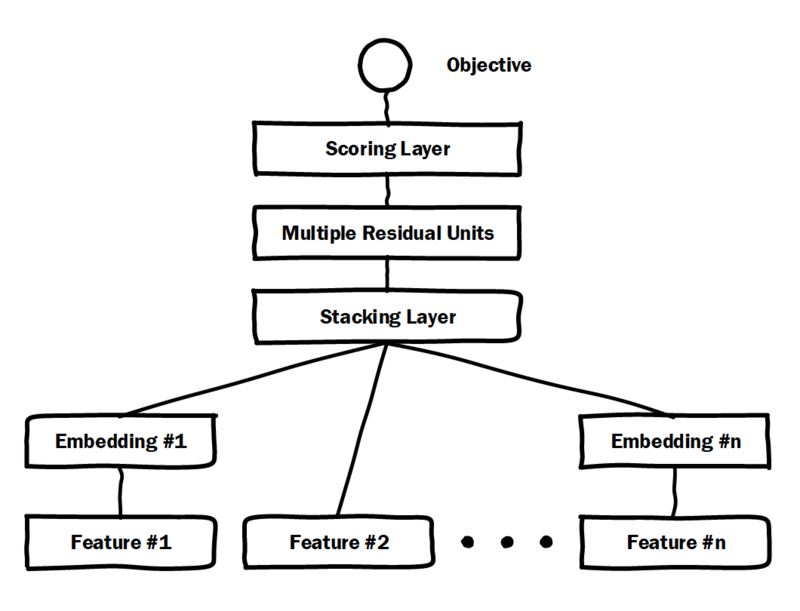
- multiple residual units:残差网络
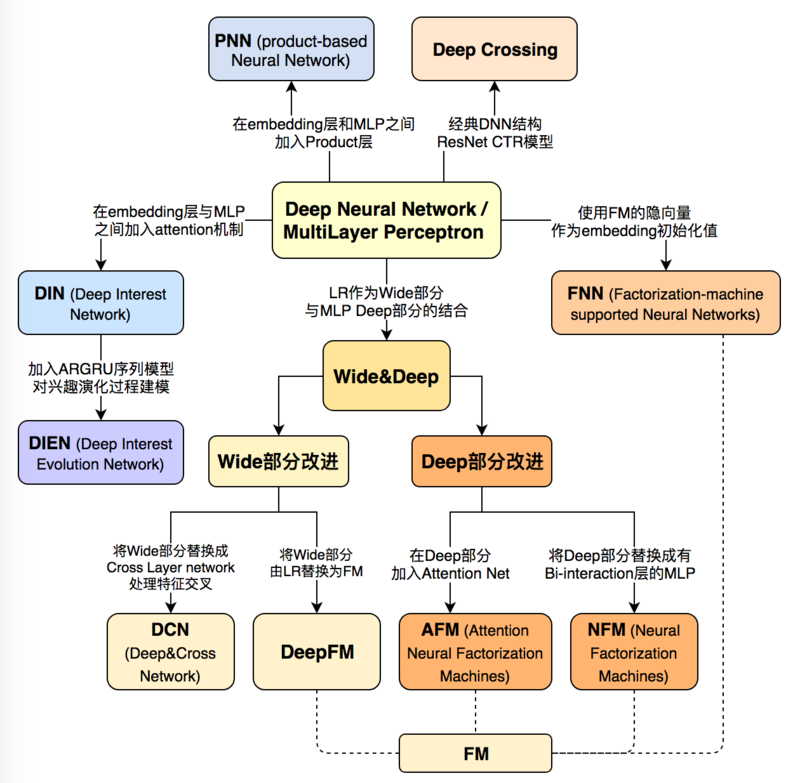
Factorization Machine based Neural Network
FNN:使用FM隐层作为embedding向量,避免完全从随机状态训练 embedding
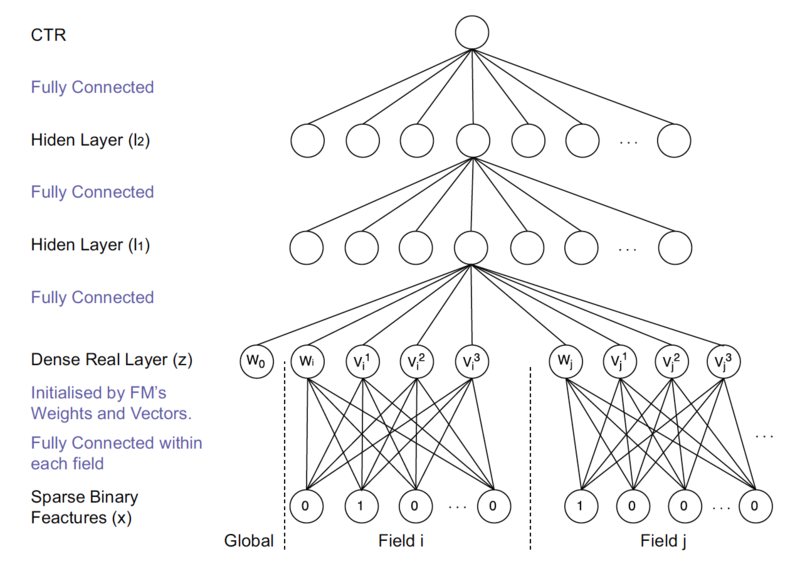
输入特征为高维稀疏特征,embeddingd层与输入层连接数量大、 训练效率低、不稳定
提前训练embedding提高模型复杂度、不稳定性
Product-based Neural Network
PNN:在embedding层、全连接层间加入product layer,完成 针对性特征交叉
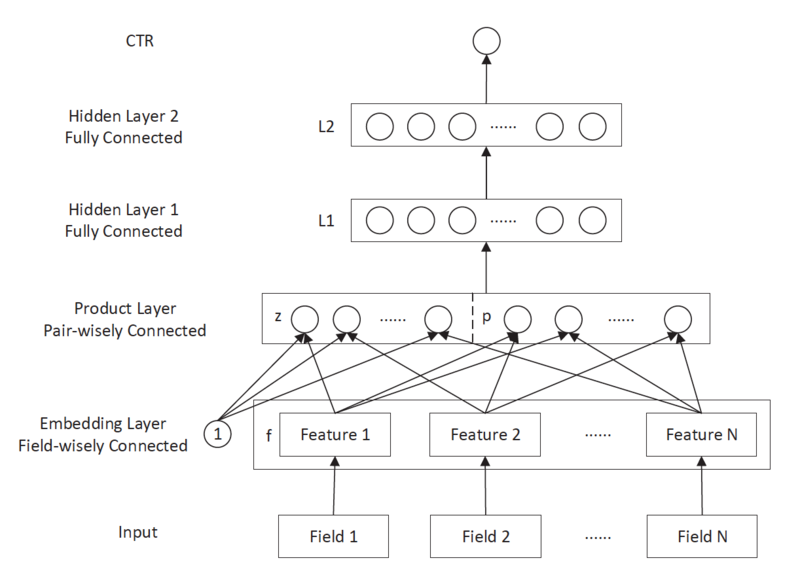
product layer:在不同特征域间进行特征组合,定义有 inner、outer product以捕捉不同的交叉信息,提高表示能力
传统DNN中通过多层全连接层完成特征交叉组合,缺乏针对性
- 没有针对不同特征域进行交叉
- 不是直接针对交叉特征设计
Wide&Deep Network
Wide&Deep:结合深层网络、广度网络平衡记忆、泛化
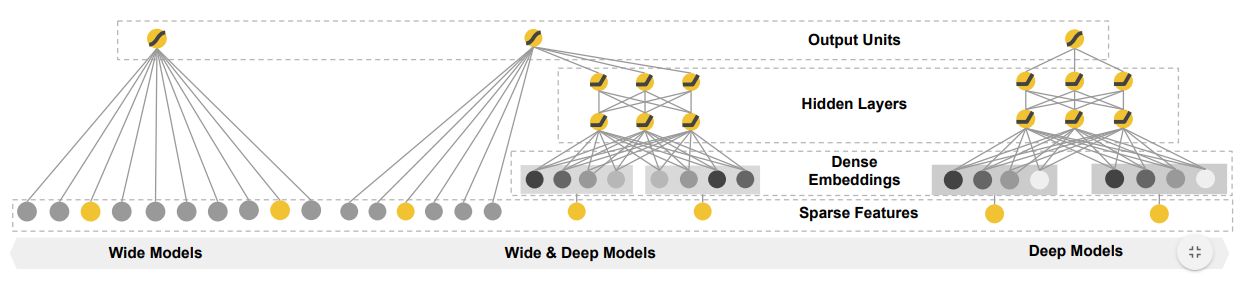
- deep models:基于稠密embedding前馈神经网络
- wide models:基于稀疏特征、特征交叉、特征转换线性模型
- 基于记忆的推荐通常和用户已经执行直接相关;基于泛化的推荐 更有可能提供多样性的推荐
- memorization:记忆,学习频繁出现的物品、特征,从历史 数据中探索相关性
generalization:泛化,基于相关性的transitivity,探索 较少出现的新特征组合
- wide&deep系模型应该都属于stacking集成
Google App Store实现
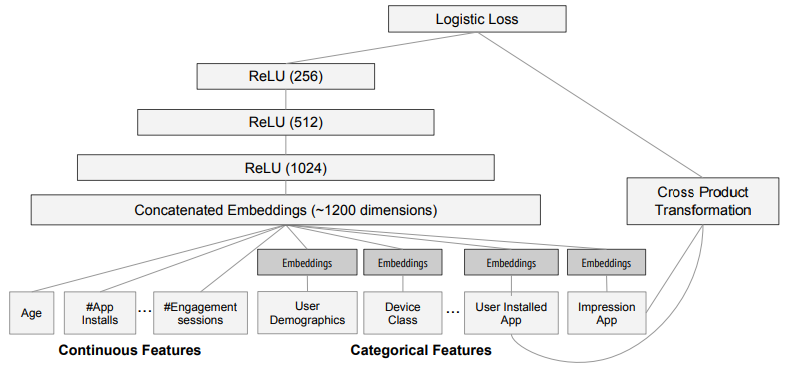
wide部分:cross product transformation
- 输入
- 已安装Apps
- impression Apps
- 特征工程交叉特征
- 优化器:带L1正则的FTRL
- 输入
Deep部分:左侧DNN
- 输入
- 类别特征embedding:32维
- 稠密特征
- 拼接:拼接后1200维 (多值类别应该需要将embedding向量平均、极大化)
- 优化器:AdaGrad
- 隐层结构
- 激活函数relu优于tanh
- 3层隐层效果最佳
- 隐层使用塔式结构
- 输入
DeepFM
DeepFM:用FM替代wide&deep中wide部分,提升其表达能力
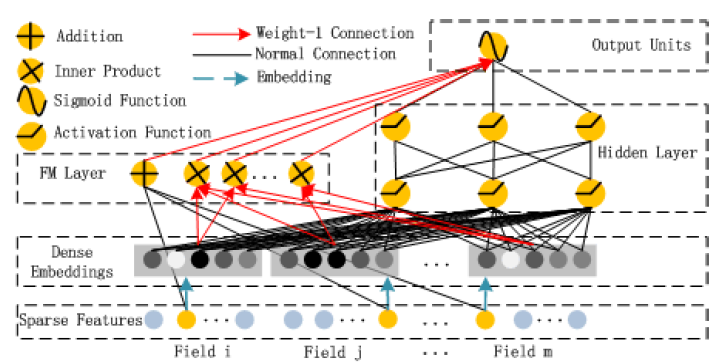
- Dense Embeddings:FM中各特征隐向量,FM、DNN公用
- FM Layer:FM內积、求和层
特点(和Wide&Deep关键区别)
- wide部分为FM (deep&wide中wide部分有特征交叉,但依靠特征工程实现)
- FM、DNN部分共享embedding层
同时组合wide、二阶交叉、deep三部分结构,增强模型表达能力
- FM负责一阶特征、二阶特征交叉
- DNN负责更高阶特征交叉、非线性
实现
DNN部分隐层
- 激活函数relu优于tanh
- 3层隐层效果最佳
- 神经元数目在200-400间为宜,略少于Wide&Deep
- 在总神经元数目固定下,constant结构最佳
embedding层
- 实验中维度为10
Deep&Cross Network
Deep&Cross:用cross网络替代wide&deep中wide部分,提升其 表达能力
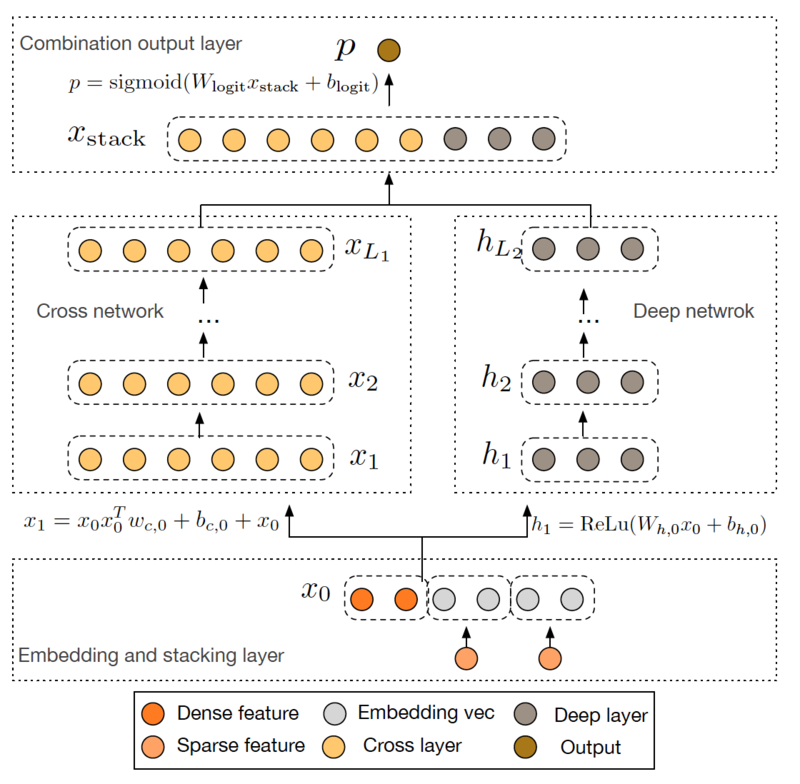
特点(和WDL、DeepFM区别)
- 使用交叉网络结构提取高阶交叉特征
- 无需特征工程(WDL)
- 不局限于二阶交叉特征(DeepFM)
- 使用交叉网络结构提取高阶交叉特征
交叉网络可以使用较少资源提取高阶交叉特征
https://arxiv.org/pdf/1708.05123.pdf
交叉网络
交叉网络:以有效地方式应用显式特征交叉,由多个交叉层组成
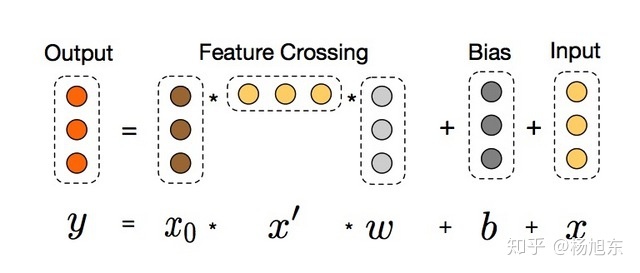
- $x_l$:第$l$交叉层输出
- $w_l, b_l$:第$l$交叉层参数
借鉴残差网络思想
- 交叉层完成特征交叉后,会再加上其输入
- 则映射函数$f(x_l, w_l, b_l)$即拟合残差
特征高阶交叉
- 每层$x_0 x_l^T$都是特征交叉
- 交叉特征的阶数随深度$l$增加而增加,最高阶为$l+1$
复杂度(资源消耗)
- 随输入向量维度、深度、线性增加
- 受益于$x_l^T w$为标量,由结合律无需存储中间过程矩阵
Nueral Factorization Machine
NFM:用带二阶交互池化层的DNN替换FM中二阶交叉项,提升FM的 非线性表达能力
- $f_{DNN}(x)$:多层前馈神经网络,包括Embedding Layer、 Bi-Interaction Layer、Hidden Layer、 Prediciton Layer
- $h^T$:DNN输出层权重
模型结构
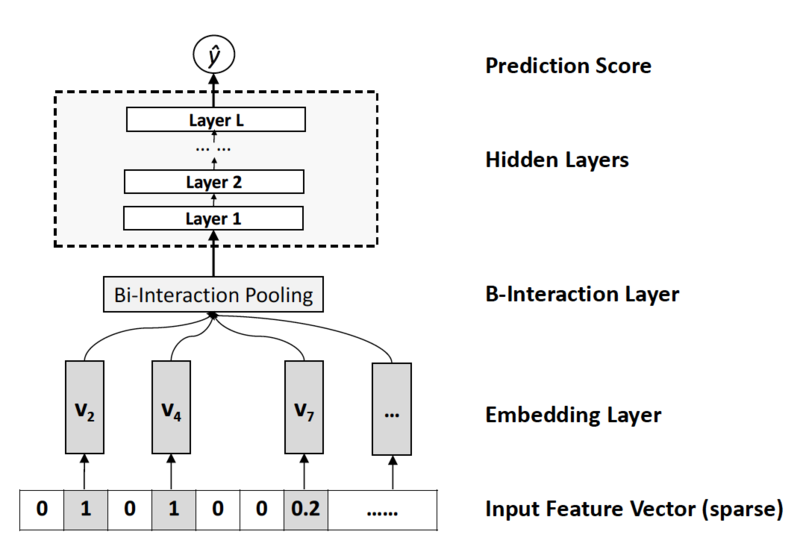
Embedding Layer
全连接网络:将每个特征映射为稠密向量表示
- $v_i$:$k$维embedding向量
- 只需要考虑非0特征,得到一组特征向量
- 特征向量会乘以特征值以反映真实值特征 (一般embedding特征取0/1,等价于查表)
Bi-Interaction Layer
BI层:将一组embedding向量转换为单个向量
- $\odot$:逐元素乘积
- 没有引入额外参数,可在线性时间$\in O(kM_x)$内计算
- 可以捕获在低层次二阶交互影响,较拼接操作更 informative,方便学习更高阶特征交互
- 将BI层替换为拼接、同时替换隐层为塔型MLP(残差网络) 则可以得到wide&deep、DeepCross
- 拼接操作不涉及特征间交互影响,都交由后续深度网络学习 ,实际操作中比较难训练
Hidden Layer
隐层:普通多层嵌套权重、激活函数
- $l=0$没有隐层时,$f_{\sigma}$原样输出,取$h^T$为 全1向量,即可得FM模型
Attentional Factorization Machines
AFM:引入Attention网络替换FM中二阶交互项,学习交互特征的 重要性,剔除无效的特征组合(交互项)
- $\varepsilon$:隐向量集,同上
- $p^T$:Attention网络输出权重
模型结构
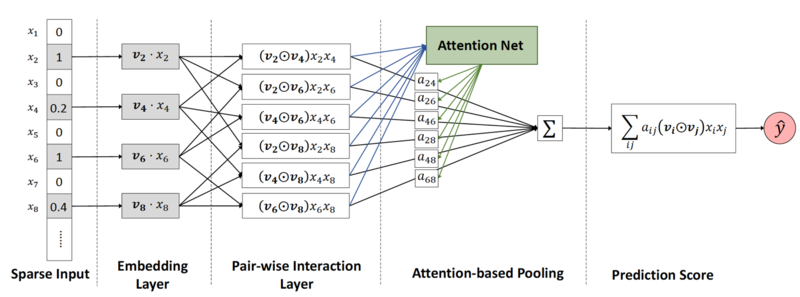
Pair-Wise Interaction Layer
成对交互层:将m个embedding向量扩充为$m(m-1)/2$个交互向量
- $R_X = {(i,j) | i \in X, j \in X, j > i }$
- $v_i$:$k$维embedding向量
Attention-based Pooling
注意力池化层:压缩交互作用为单一表示时,给交互作用赋不同权重
- $a{i,j}$:交互权重$w{i,j}$的注意力得分
- $\odot$:逐元素乘积
考虑到特征高维稀疏,注意力得分不能直接训练,使用MLP attention network参数化注意力得分
- $W \in R^{t*k}, b \in R^t, h \in R^T$:模型参数
- $t$:attention network隐层大小
Deep Interest Network
DIN:融合Attention机制作用于DNN
模型结构
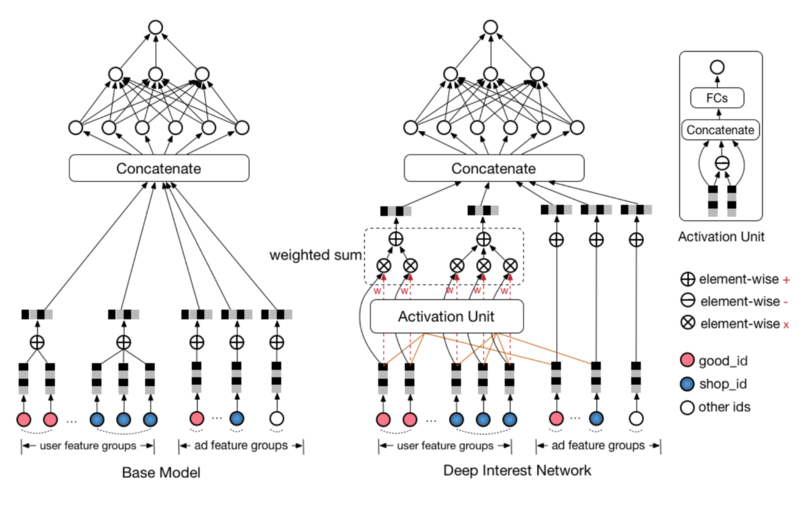
activation unit
激活单元
- 相较于上个结构仅多了直接拼接的用户、上下文特征
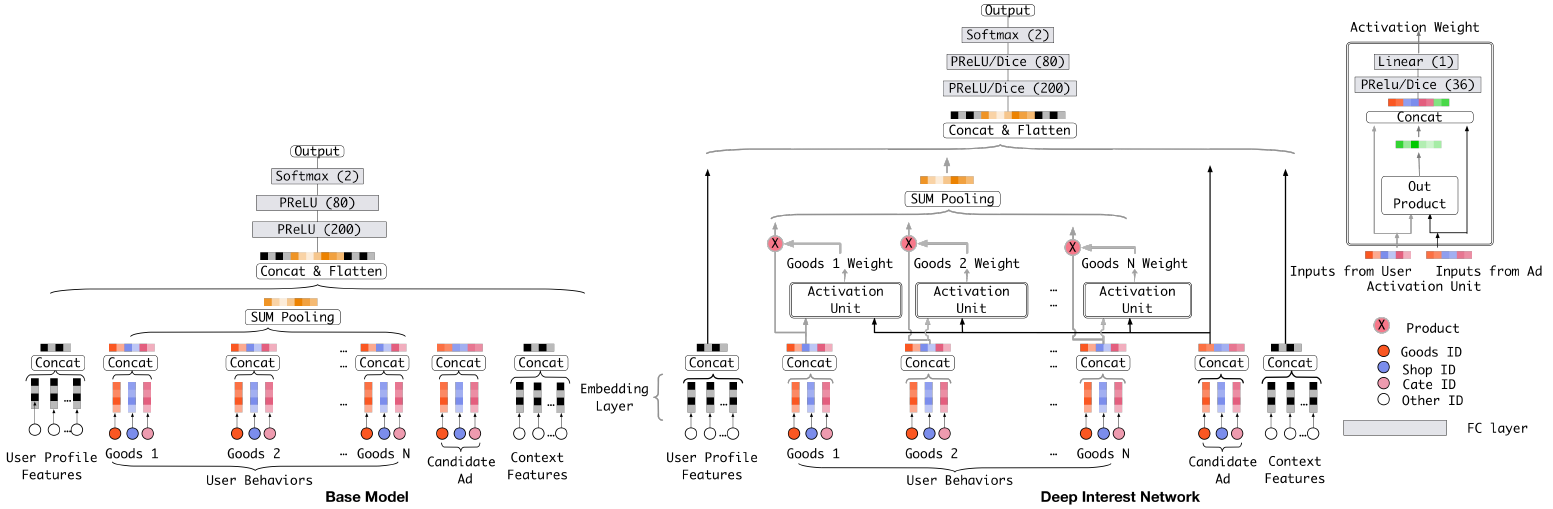
模型训练
Mini-batch Aware Regularization
- 以Batch内参数平均近似$L_2$约束
- $W \in R^{K * M}, W_i$:embedding字典、第$i$embedding 向量
- $K, M$:embedding向量维数、特征数量
- $B, B_j$:batch数量、第$j$个batch
则参数迭代
Data Adaptive Activation Function
PReLU在0点处硬修正,考虑使用其他对输入自适应的函数替代,以 适应不同层的不同输入分布
Deep Interest Evolution Network
DIEN:引入序列模型AUGRU模拟行为进化过程
模型结构
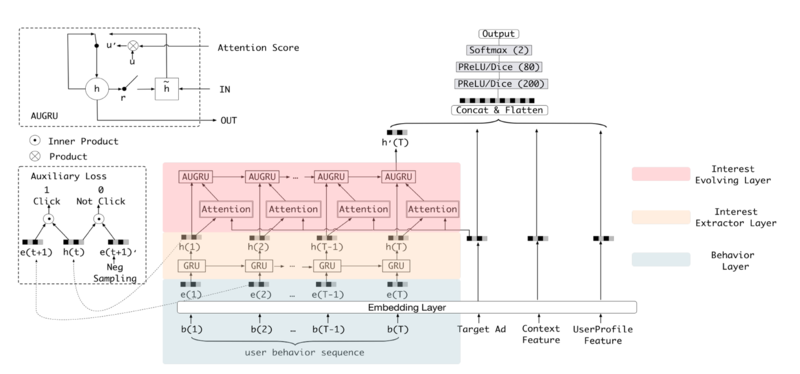
- Interest Extractor Layer:使用GRU单元建模历史行为依赖 关系
? 关系